|
| 1 | +--- |
| 2 | +title: Emotion Recognition |
| 3 | +image: /assets/img/emotion-recognition.jpg |
| 4 | +author: jack |
| 5 | +date: 2022-01-09 20:55:00 +0800 |
| 6 | +categories: [python, machine learning] |
| 7 | +tags: [python, machine learning] |
| 8 | +math: false |
| 9 | +pin: false |
| 10 | +--- |
| 11 | + |
| 12 | +The project is a fork of [usef-kh/fer](https://github.com/usef-kh/fer). We made an application for detecting user-provided human face image. And we use the code from [atulapra/Emotion-detection](https://github.com/atulapra/Emotion-detection) to implement a real-time camera emotion detector. |
| 13 | + |
| 14 | +Github: [https://github.com/blueskyson/emotion-recognition](https://github.com/blueskyson/emotion-recognition) |
| 15 | + |
| 16 | +It is the final project of CSIE7606 - Computer Vision and Deep Learning by [Jenn-Jier (James) Lien](https://www.csie.ncku.edu.tw/en/members/25) at National Cheng Kung University. This course not only allows students to gain an in-depth understanding of the theoretical knowledge of computer vision, machine learning, and artificial intelligence-deep learning, and to analyze how the principles of deep learning are combined with the development of artificial intelligence and computer vision, but also focuses on the technical functionalities. These are explained through the instructor's industry-academic collaboration experiences, including facial expression analysis, cloud-based intelligent monitoring services, automated optical inspection, intelligent robotic arm control, and autonomous vehicles. |
| 17 | + |
| 18 | +## 1. Introduction |
| 19 | + |
| 20 | +Facial emotion recognition plays an important role in **human-computer interactions** and can be applied to **digital advertisement**, **gaming**, and **customer feedback assessment**. |
| 21 | + |
| 22 | +*One specific emotion recognition dataset that encompasses the difficult naturalistic conditions and challenges is FER2013.* Human performance on this dataset is estimated to be 65±5% [2], which means <span style="color:orange;">it is hard even for humans to recognize the emotions.</span> This work adopts <span style="color:orange;">VGG network</span> and shows various experiments to explore different <span style="color:orange;">optimization algorithms</span> and <span style="color:orange;">learning rate schedulers.</span> The authors thoroughly tune the model and hyperparameters to achieve <span style="color:red;">state-of-the-art results at a testing accuracy of 73.28 %.</span> |
| 23 | + |
| 24 | +<span style="color:blue;">We have reproduced this paper’s work. Furthermore, we apply Haar filter to make an application that detects emotions from user-provided images and integrate our model in real-time camera emotion detector.</span> |
| 25 | + |
| 26 | +## 2. System Architecture |
| 27 | + |
| 28 | +<span style="color:orange;">VGGNet</span> is a classical convolutional neural network architecture used in pattern recognition. The network consists of <span style="color:red;">4 convolutional stages</span> and <span style="color:red;">3 fully connected layers</span>. |
| 29 | + |
| 30 | +Each convolutional stage contains two <span style="color:red;">convolution blocks</span> and a max-pooling layer. Each <span style="color:orange;">convolution block</span> contains a <span style="color:red;">convolutional layer</span>, a <span style="color:red;">ReLU activation</span>, and a <span style="color:red;">batch normalization</span> layer. Batch normalization is used to speed up learning process, reduce the internal covariance shift, and prevent gradient vanishing or explosion. |
| 31 | + |
| 32 | +The first two fully connected layers are followed by a ReLU activation. The third fully connected layer is for classification. |
| 33 | + |
| 34 | +Overall, convolutional stages are responsible for feature extraction, and fully connected layers are trained to classify the images. |
| 35 | + |
| 36 | +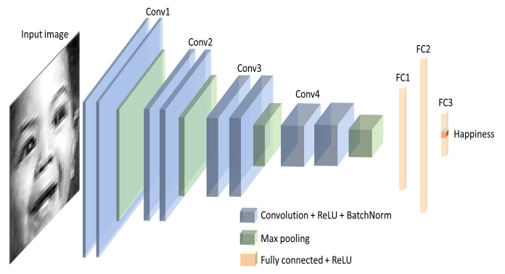 |
| 37 | + |
| 38 | +- **Conv1** to **Conv4** are convolution stages, which are used for feature extraction. |
| 39 | +- A blue rectangle represents a convolution block. |
| 40 | +- A green rectangle represents a max-pooling layer. |
| 41 | +- **FC1** to **FC3** are fully connected layers, which are used to classify emotions from features extracted by former stages. |
| 42 | + |
| 43 | +### Optimizers |
| 44 | + |
| 45 | +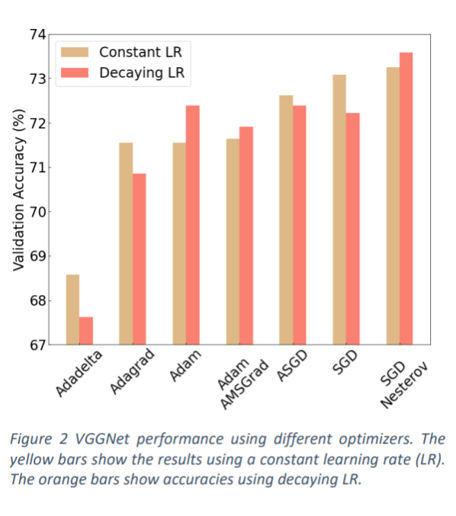 |
| 46 | + |
| 47 | +The authors test 6 different optimizers, including SGD, |
| 48 | +SGD with Nesterov Momentum, Average SGD, Adam, |
| 49 | +Adam with AMSGrad, Adadelta, and Adagrad. This |
| 50 | +experiment is done under two configurations: |
| 51 | + |
| 52 | +<span style="color: blue;">Constant LR</span>: Fixed learning rate of 0.001. |
| 53 | +<span style="color: blue;">Decaying LR</span>: Decaying the initial learning rate of |
| 54 | +0.01 by a factor of 0.75 if the validation accuracy |
| 55 | +plateaus for 5 epochs (RLRP scheduling). |
| 56 | + |
| 57 | +<span style="color: red;">They find that the SGD with Nesterov Momentum |
| 58 | +is the best.</span> |
| 59 | + |
| 60 | +### Learning Rate (LR) Schedule |
| 61 | + |
| 62 | +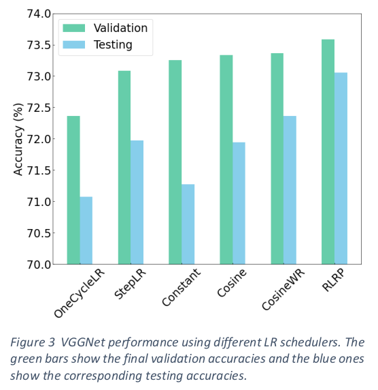 |
| 63 | + |
| 64 | +The authors test 5 different LR schedulers, including |
| 65 | +Reduce Learning Rate on Plateau (RLRP), Cosine |
| 66 | +Annealing (Cosine), Cosine Annealing with Warm |
| 67 | +Restarts (CosineWR), One Cycle Learning Rate |
| 68 | +(OneCycleLR), and Step Learning Rate (StepLR). |
| 69 | + |
| 70 | +Using SGD with Nesterov momentum optimizer. |
| 71 | + |
| 72 | +<span style="color: red;">They find that the RLRP is the best since it |
| 73 | +monitors the current performance before deciding |
| 74 | +when to drop the learning rate.</span> |
| 75 | + |
| 76 | +## 3. Data Collection |
| 77 | + |
| 78 | +<span style="color: orange;">FER2013</span> is a dataset composed of 35587 grey-scale 48x48 images of faces classified in <span style="color: orange;">7 categories: anger, disgust, fear, happiness, sadness, surprise, neutral.</span> |
| 79 | + |
| 80 | +The dataset is divided in a training set (28709 images), a public |
| 81 | +test set (3589 images), usually considered the test set for final |
| 82 | +evaluations. |
| 83 | + |
| 84 | +FER2013 is known as a challenging dataset because of its <span style="color: orange;">noisy |
| 85 | +data with a relatively large number of non-face images and |
| 86 | +misclassifications</span>. It is also <span style="color: orange;">strongly unbalanced</span>, with only 436 |
| 87 | +samples in the less populated category, "Disgust", and 7215 |
| 88 | +samples in the more populated happiness. |
| 89 | + |
| 90 | +<span style="color: red;">This dataset analogous to real world challenges in the field.</span> |
| 91 | + |
| 92 | +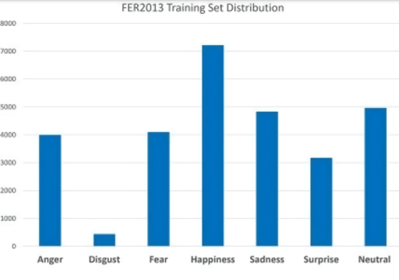 |
| 93 | + |
| 94 | +## 4. Our Experimental Results |
| 95 | + |
| 96 | +### Accuracy |
| 97 | + |
| 98 | +In our experiment the model had <strong>great gains from epoch [0 to 30]</strong>, and <strong>continues to advance [epoch 31~100]</strong> thanks to the <span style="color: orange;">RLRP learning rate scheduler</span>. |
| 99 | + |
| 100 | +<p style="color: red;"> |
| 101 | +<strong>Terminating at the 100th epoch, the resulting testing set accuracy is 71.52415%</strong>, which is on par with that of the original paper (73.06%) we based our experiment on. |
| 102 | +</p> |
| 103 | + |
| 104 | +<p style="color: blue;"> |
| 105 | +<strong>This is state-of-the-art on FER2013 without extra training data.</strong> |
| 106 | +</p> |
| 107 | + |
| 108 | + |
| 109 | + |
| 110 | +### Loss |
| 111 | + |
| 112 | +During the training phase, the training loss never equaled to validation loss, indicating that <strong>there is no underfitting</strong>. |
| 113 | + |
| 114 | +Nor was the training loss much lower than the validation loss, indicating that <strong>no overfitting occured</strong> during the process. |
| 115 | + |
| 116 | +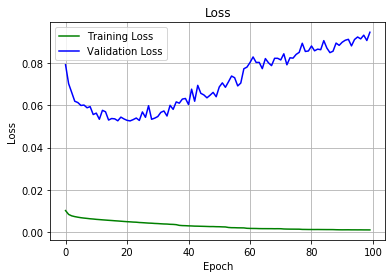 |
| 117 | + |
| 118 | +### The Paper's Original Fine Tuning Result |
| 119 | + |
| 120 | +The authors tune their best model (73.06% accuracy) for <strong>50</strong> extra epochs using both cosine annealing schedulers with <strong>lr=0.0001</strong>. <span style="color: orange;">Cosine Annealing performs best here and improves the model by 0.05 %</span>. Cosine Annealing with Warm Restarts negatively impacts performance in this tuning stage reducing the accuracy by 0.42 %. Both models <span style="color: blue;">perform better after training on the combined dataset</span> resulting from the combined training and validation data. |
| 121 | + |
| 122 | +<p style="color: red;"> |
| 123 | +<strong>Paper’s final best model achieves an accuracy of 73.28%.</strong> |
| 124 | +</p> |
| 125 | + |
| 126 | +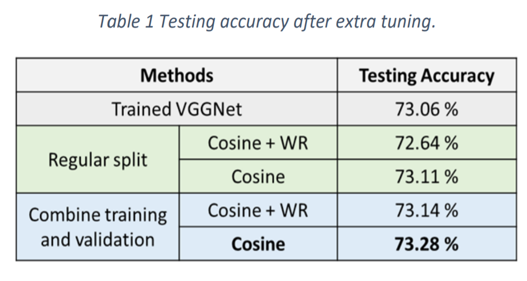 |
| 127 | + |
| 128 | +### Our Fine Tuning Result |
| 129 | + |
| 130 | +Tune our best model (71.6912% accuracy) for <strong>20</strong> extra epochs using both cosine annealing schedulers with <strong>lr=0.0001</strong>. |
| 131 | + |
| 132 | +Both models <span style="color: blue;">perform better after training on the combined dataset</span> resulting from the training and validation data. |
| 133 | + |
| 134 | +<p style="color: red;"> |
| 135 | +<strong>Our final best model achieves an accuracy of 72.3878%.</strong> |
| 136 | +</p> |
| 137 | + |
| 138 | +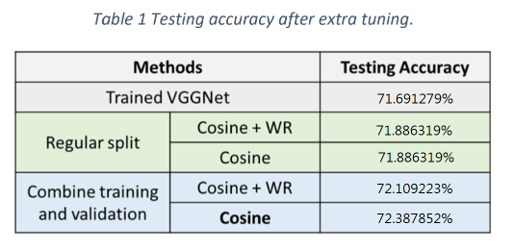 |
| 139 | + |
| 140 | +## 5. Demo |
| 141 | + |
| 142 | +Correct Recognitions: |
| 143 | + |
| 144 | + |
| 145 | + |
| 146 | +Incorrect Recognitions: |
| 147 | + |
| 148 | + |
| 149 | + |
| 150 | +Real-time Camera Detector: |
| 151 | + |
| 152 | + |
| 153 | + |
| 154 | +## 6. Conclusion and Future Works |
| 155 | + |
| 156 | +This paper achieves <span style="color:red;">single-network state-of-the-art classification accuracy on FER2013</span> using a <span style="color:orange;">VGGNet</span>. We thoroughly tune all hyperparameters towards an optimized model for facial emotion recognition. <span style="color:orange;">Different optimizers and learning rate schedulers are explored</span> and the best initial testing classification accuracy achieved is <span style="color:red;">73.06%</span>, surpassing all single-network accuracies previously reported. We also carry out extra tuning on our model using <span style="color:orange;">Cosine Annealing and combine the training and validation datasets</span> to further improve the classification accuracy to <span style="color:red;">73.28%</span>. |
| 157 | + |
| 158 | +For future work, we plan to explore different <span style="color:orange;">image preprocessing</span> techniques on FER2013 and investigate <span style="color:orange;">ensembles of different deep learning architectures</span> to further improve our performance in facial emotion recognition. |
| 159 | + |
| 160 | +<p style="color:blue;"> |
| 161 | +We got our best model by training 100 epochs and reproduced the fine tuning experiments with 20 extra epochs. The result shows that combine training and validation with Cosine Annealing performs best, which is consistent with the paper. |
| 162 | +</p> |
| 163 | + |
| 164 | +## 7. Additional Work |
| 165 | + |
| 166 | +We use <span style="color:orange;">ResNet34V2</span>, published by Microsoft Reasearch. In contrast to the original ResNet34, ResNet34V2 puts batch normalization layer and ReLU activation before the convolution layer. |
| 167 | + |
| 168 | +In our experiment the model had <strong>great gains from epoch[0~20], and continues to advance [epoch 31~100]</strong> thanks to the RLRP learning rate scheduler. |
| 169 | + |
| 170 | +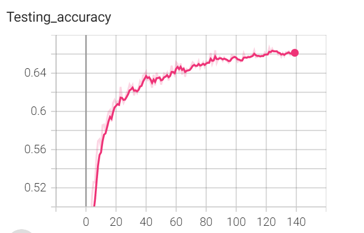 |
| 171 | + |
| 172 | +<span style="color:red;">Terminating at the 140th epoch , the resulting testing set accuracy is 66%.</span> The accuracy is lower than VGGNet, but it is a little bit better than human performance. |
| 173 | + |
| 174 | +| | Our VGGNet | Paper's VGGNet | ResNet34V2 | SVM | |
| 175 | +|-----------------|---------------------------------------------|--------------------------------------------------------|------------|------| |
| 176 | +| Testing Accuracy| 72.387852% | 73.28% | 66% | 31% | |
| 177 | +| epoch | 120 | 350 | 140 | X | |
| 178 | +| fine-tuning | final 20 epochs with combined training and | final 50 epochs with combined training and validation | X | X | |
| 179 | +| | validation dataset | dataset | | | |
0 commit comments