大型语言模型(LLM),如GPT系列,以其强大的自然语言理解和生成能力惊艳了世界。然而,它们并非完美无缺,其核心的“记忆”存在两大困境:
- 知识截止日期(Knowledge Cutoff):LLM的知识被冻结在训练数据截止的那个时刻。它们对之后发生的新事件、新知识一无所知。你无法向一个2023年训练的模型询问2024年的世界杯冠军。
- 幻觉(Hallucination):当被问及超出其知识范围或需要高度精确性的问题时,LLM有时会“一本正经地胡说八道”,编造出看似合理但完全错误的信息。对于需要事实准确性的企业应用来说,这是致命的。
此外,LLM无法直接访问组织的内部私有知识库(如产品文档、项目Wiki、财务报告等)。
那么,如何才能让LLM既能利用其强大的推理生成能力,又能访问实时、动态、私有的外部知识呢?答案就是 检索增强生成(Retrieval-Augmented Generation, RAG)。
RAG是一种AI框架,它通过将LLM与外部知识库相结合,来增强LLM的能力。它的核心思想可以拆解为两个部分:
- 检索(Retrieval):当面对一个问题时,系统不直接把它交给LLM。而是先去一个外部的知识库(如向量数据库)中,检索出与问题最相关的信息片段。
- 增强生成(Augmented Generation):系统将用户原始的问题和从知识库中检索到的相关信息,一起“打包”成一个新的、内容更丰富的提示(Prompt),然后提交给LLM。LLM基于这些“增强”过的信息来生成最终答案。
简单来说,RAG就是为LLM配备了一个可以随时查阅的、动态更新的“开卷考试资料库”。
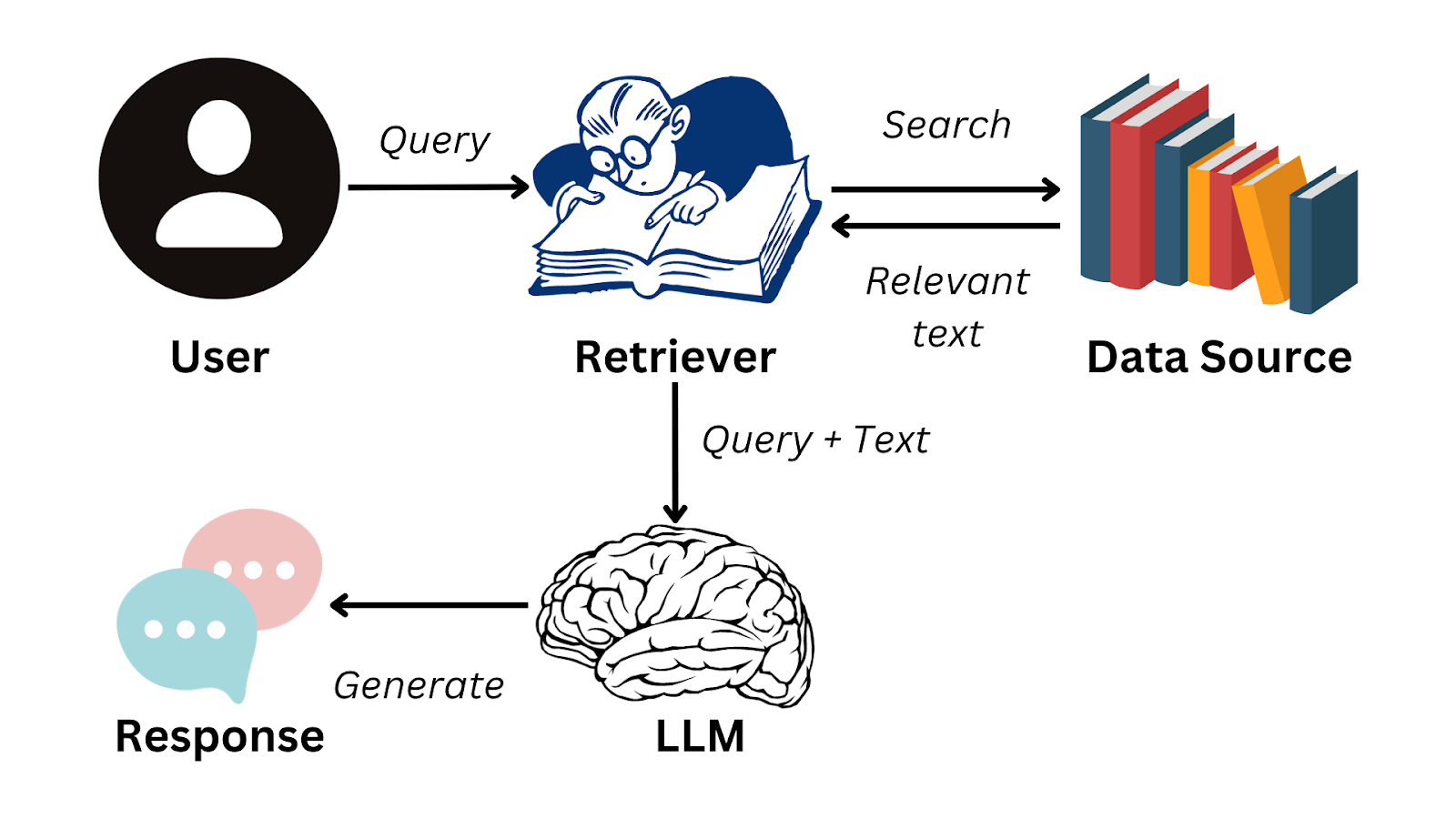
一个典型的RAG系统工作流程可以分为两个阶段:数据准备(离线) 和 推理生成(在线)。
这个阶段的目标是建立我们的“知识库”。
- 数据加载(Data Loading):从各种来源加载原始数据,如PDF文档、网页、数据库、API等。
- 数据分块(Chunking):将加载的长文档切分成更小的、语义完整的块(chunks)。分块是至关重要的一步,因为太大的块会包含太多噪声,太小的块则可能丢失上下文信息。
- 向量化(Embedding):使用Embedding模型(如BERT、OpenAI a-da-002等)将每个数据块转换为一个高维向量。这个向量是该数据块语义的数学表示。
- 索引存储(Indexing):将所有数据块的向量化表示存储到一个专门的 向量数据库 中(如Milvus, Pinecone, Chroma等)。向量数据库会构建高效的索引(如HNSW),以便后续能够进行快速的相似性搜索。
这个阶段是用户与系统交互的实时过程。
- 用户提问(User Query):用户输入一个问题或提示。
- 查询向量化(Query Embedding):使用与数据准备阶段 相同的Embedding模型 将用户的问题也转换为一个向量。
- 相似性搜索(Similarity Search):用查询向量在向量数据库中进行搜索,找出与查询向量在语义上最相似的
Top-K个数据块。 - 提示增强(Prompt Augmentation):将检索到的这
Top-K个数据块作为上下文(Context),与用户原始的问题一起,构建一个新的、信息更丰富的提示。 - LLM生成答案(LLM Generation):将这个增强后的提示发送给LLM。LLM会根据提供的上下文信息,生成一个更加精准、事实性更强的答案。
相比于其他让LLM学习新知识的方法(如成本高昂的重新训练或微调),RAG具有显著优势:
- 提升事实准确性:通过提供直接相关的外部知识,极大地减少了模型产生幻觉的可能性。
- 知识实时更新:知识库可以独立于LLM进行更新。当新知识出现时,只需更新向量数据库中的数据,而无需重新训练庞大的LLM。
- 可追溯与可解释性:由于答案是基于检索到的特定文本片段生成的,我们可以很容易地追溯到答案的来源,这对于需要验证信息来源的应用至关重要。
- 成本效益高:相比于对LLM进行微调(Fine-tuning)或从头训练,维护一个外部知识库并实现RAG的成本要低得多。
RAG和微调是增强LLM能力的两种不同路径,它们各有侧重:
| 特性 | 检索增强生成 (RAG) | 微调 (Fine-tuning) |
|---|---|---|
| 目标 | 注入 事实性知识 | 传授 特定技能或风格 |
| 知识更新 | 简单,只需更新外部数据库 | 复杂,需要重新训练模型 |
| 成本 | 较低,主要是数据库维护成本 | 较高,需要大量标注数据和计算资源 |
| 可追溯性 | 高,可以明确指出信息来源 | 低,知识内化在模型权重中,难以解释 |
| 适用场景 | 问答、客服、事实核查 | 模仿特定写作风格、特定任务优化 |
在实际应用中,RAG和微调可以结合使用,以达到最佳效果。例如,可以对一个模型进行微调,使其更擅长遵循指令和总结信息,然后再将其接入RAG系统,以确保其回答的事实准确性。
RAG不仅仅是一个技术性的改进,它从根本上改变了我们与LLM的交互方式。它将LLM从一个封闭的“知识黑箱”转变为一个开放的、能够与动态世界连接的“推理引擎”。
通过有效地将海量、实时、私有的数据与LLM强大的生成能力相结合,RAG为构建更智能、更可靠、更具价值的AI应用打开了全新的大门,是当前通往企业级生成式AI应用最重要、最实用的路径之一。