| title | 操作系统文件系统详解:inode、VFS、Page Cache 与日志机制 | |||||||
|---|---|---|---|---|---|---|---|---|
| description | 文件系统高频面试题总结,从文件和目录讲起,讲清 inode、dentry、文件描述符、VFS、磁盘块分配、空闲空间管理、硬链接、软链接、Page Cache、fsync 和日志文件系统。 | |||||||
| category | 计算机基础 | |||||||
| tag |
|
|||||||
| head |
|
写一个保存文件的接口,最直觉的写法是:拿到路径,open 一个文件,把数据 write 进去,最后 close。文件少、并发低、机器不出故障的时候,这套流程看起来没什么难度。
可一到面试追问,问题就来了。open() 返回的 fd 到底指向什么?文件名是存在 inode 里吗?两个硬链接为什么能看到同一份内容?write() 返回成功,数据是不是已经落盘?日志文件删了,为什么 df -h 还是显示磁盘满?
这些问题都绕不开文件系统。它要把路径解析成文件对象,把文件的第 N 个字节定位到底层数据块,还要处理权限、缓存、删除、重命名和崩溃恢复。
答案就藏在 inode、dentry、VFS、Page Cache 和日志机制里。
下面先从最基础的问题讲起:文件系统到底在管什么?
平时写代码,看到的是路径、文件名、目录、read、write。对于建立在本地块设备上的文件系统,底层通常是逻辑块、扇区和设备 I/O;文件系统把这些低层资源组织成文件、目录和元数据。
不过,并不是所有文件系统都对应本机磁盘。tmpfs 主要以内存作为后端,procfs 暴露内核运行状态,NFS 则把远端文件系统接入本地目录树。VFS 在这些实现之上提供统一的文件接口。
小 G 更建议这样看文件系统:它不是只负责“保存文件内容”,还要同时解决 4 件事。
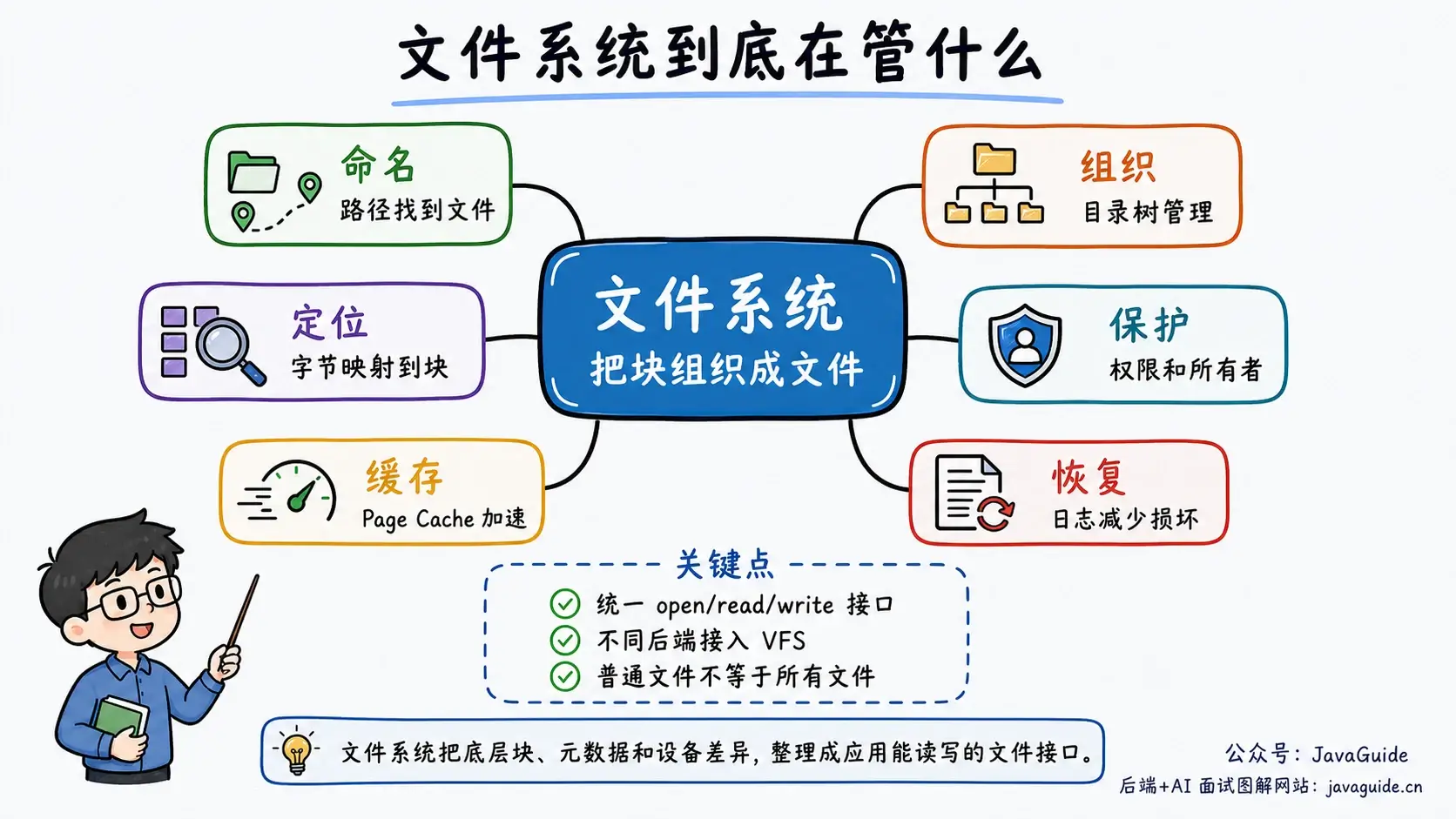
- 命名:用路径和文件名找到目标文件,例如
/var/log/app.log。 - 组织:用目录树管理文件,让不同文件能归到不同目录下。
- 定位:把文件的第 N 个字节映射到磁盘或 SSD 上的某个数据块。
- 保护:记录权限、所有者、时间戳,并在访问时做检查。
没有文件系统,应用就得自己记住“第几个块到第几个块属于哪个文件”,还要自己处理删除、扩容、权限、崩溃恢复。文件系统把这些事收进统一接口里,应用只需要拿文件描述符读写。
本文主要按 Linux/Unix 风格讲。NTFS、APFS、Btrfs、XFS、ext4 的实现各有差异,但文件、目录、元数据、缓存、分配、恢复这些问题绕不开。
在 Unix/Linux 语境下,普通文件可以理解为一段带有名称和元数据的字节序列,通常由持久化存储保存。VFS 还会用类似的文件接口暴露目录、设备、FIFO、Socket 和伪文件系统对象。
所以,“一切皆文件”更准确的理解是:Linux 尽量让不同资源通过文件描述符和统一的 I/O 接口访问,而不是所有对象都会真正写到磁盘。管道的数据在内核缓冲区里,/proc 下的很多内容则是内核实时生成的伪文件。
目录也是一种文件,只是它的数据内容比较特殊。在 ext4 这类 Unix 风格文件系统中,目录的数据主要保存“文件名到 inode 号”的映射。用户通过路径找文件时,文件系统会逐级查目录:
/home/guide/a.txt
-> 查根目录 /
-> 找到 home
-> 进入 home 后找到 guide
-> 进入 guide 后找到 a.txt
目录树让文件有了层次。挂载机制又把多个文件系统接到同一棵目录树上,例如把 /dev/sda2 挂载到 /data 后,访问 /data/app.log 时,实际访问的就是另一个分区里的文件系统。
目录虽然在文件系统内部也拥有数据块和 inode,但用户态通常不能像普通文件那样直接 read() 它,而要通过 readdir()、getdents() 这类目录遍历接口读取目录项。
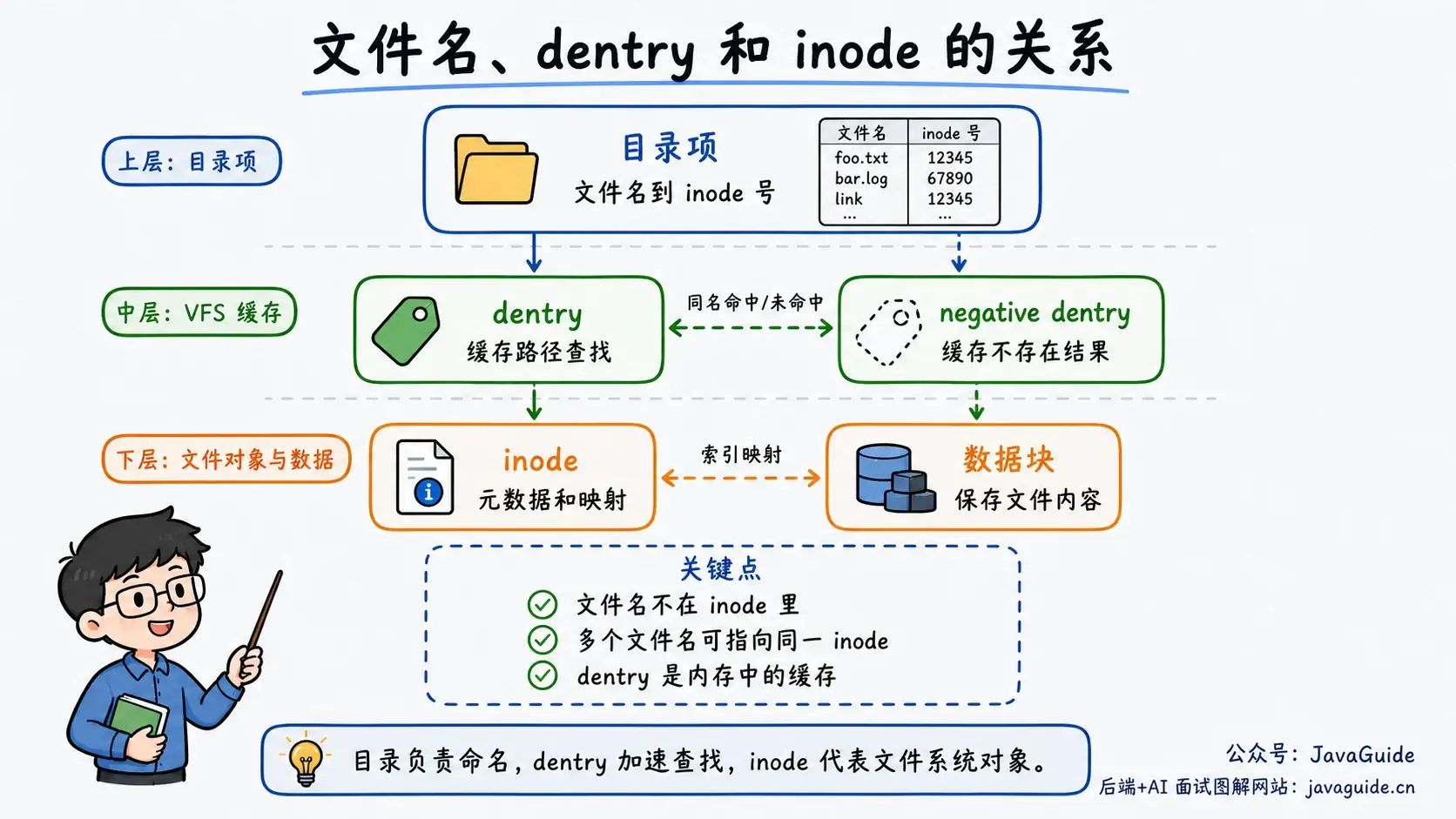
在 Linux/Unix 文件系统里,理解 inode 很关键。
inode(索引节点)记录文件元数据,常见内容包括文件类型、权限、所有者、大小、时间戳、链接计数,以及指向数据块的位置。
inode 通常不保存文件名。文件名属于目录项,同一个 inode 可以有多个文件名。普通文件的数据通常保存在独立的数据块或 extent 中,inode 只保存数据映射信息。不过部分文件系统存在内联优化,例如 ext4 可以把很小的文件内容或短符号链接目标直接放进 inode。
Linux VFS 还会在内存中维护 dentry。dentry 表示路径中的一个目录项,用来缓存名称查找结果;它通常指向 inode,但也可能是“不存在目标”的 negative dentry。可以粗略理解成:
- 文件名:保存在磁盘目录项中。
- dentry:VFS 在内存中维护的路径组件和查找缓存。
- inode:代表文件系统对象,保存或关联其元数据与数据映射。
- 数据块或 extent:保存普通文件的数据内容。
这也解释了为什么重命名文件通常很快。mv a.txt b.txt 如果发生在同一个文件系统内,很多时候只是修改目录项里的名字映射,文件内容本身不用移动。
可以用下面几个命令观察这些信息:
# 查看 inode 号
ls -li app.log
# 查看文件元数据
stat app.log
# 查看文件系统 inode 使用情况
df -i对于 ext4 这类预先建立 inode 表的文件系统,inode 数量也可能比数据块更早耗尽。服务器磁盘看起来仍有空间,但大量小文件占满 inode 后,创建文件仍可能报 No space left on device。不同文件系统的 inode 分配方式并不完全相同,因此 df -i 的解释也要结合具体文件系统。
应用调用 open() 后,内核不会把整个文件读进内存。它主要做几件事:
- 解析路径,找到对应目录项和 inode。
- 检查权限、打开标志和文件类型是否合法。
- 创建一个内核里的打开文件对象,记录文件偏移量、状态标志等信息。
- 在当前进程的文件描述符表里分配一个最小可用的非负整数,也就是 fd。
Linux man-pages 对这块说得很清楚:open() 返回的是进程文件描述符表里的索引;每次 open() 还会创建一个系统范围内的 open file description,用来记录文件偏移和状态标志。
这几个结构容易混:
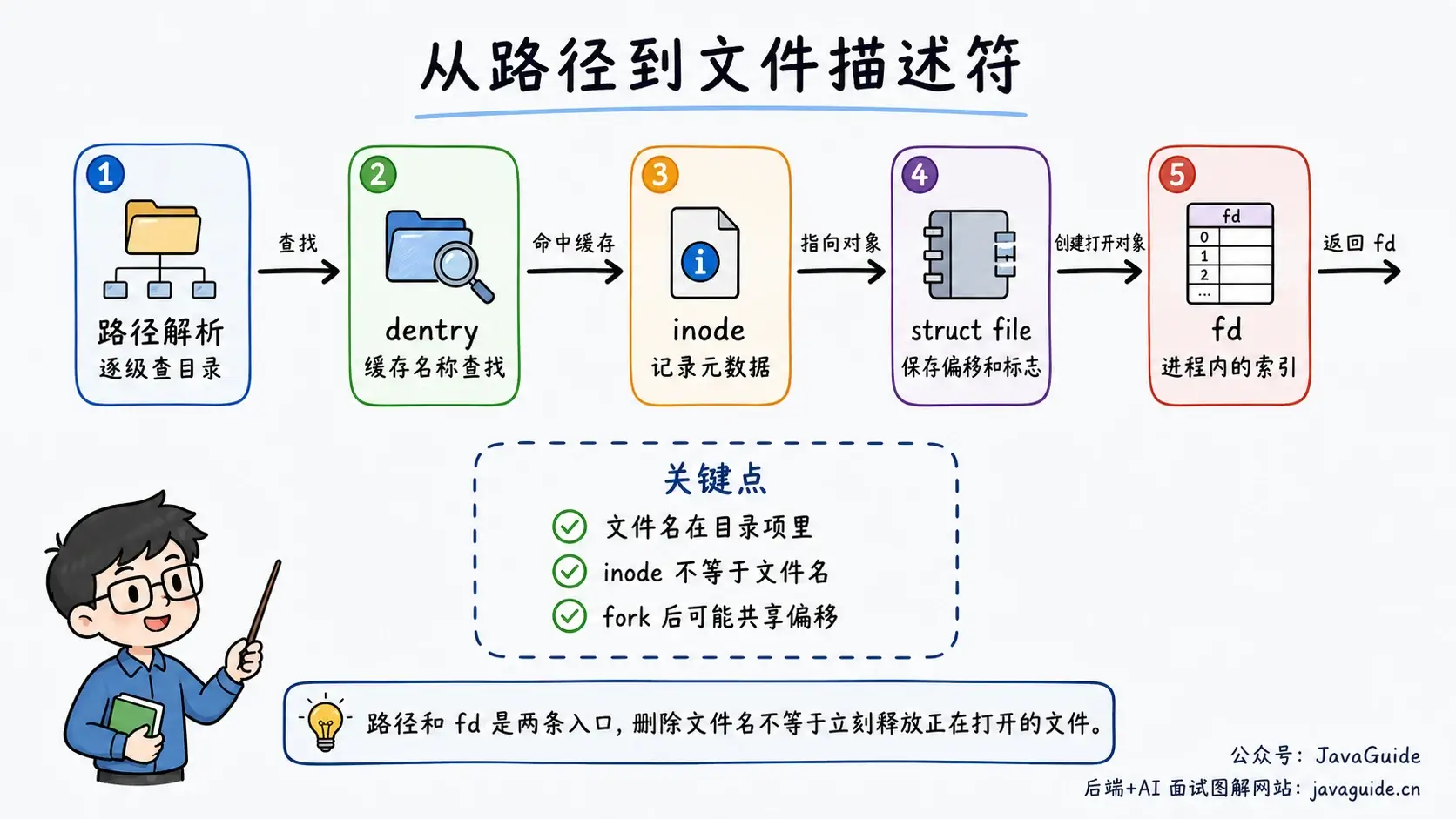
| 结构 | 归属 | 主要记录什么 |
|---|---|---|
| 文件描述符表 | 每个进程一份 | fd 到打开文件对象的引用 |
| 打开文件对象 | 系统范围内 | 当前偏移量、打开状态、读写标志 |
| inode 表/缓存 | 文件系统和内核维护 | 文件元数据、数据块位置 |
dup()、fork() 之后,多个 fd 可能引用同一个打开文件对象,所以它们共享文件偏移量。两个进程分别 open() 同一个文件,则通常会得到两个不同的打开文件对象,各自维护偏移量。
这就是下面这种现象的来源:同一个文件被删除后,正在写它的进程可能还能继续写。unlink() 删除的是目录中的名称,并减少 inode 的链接计数。只有当最后一个硬链接已经删除,并且所有打开引用、内存映射等内核引用都释放后,文件占用的空间才会真正回收。
磁盘和 SSD 对外通常以块为单位读写。文件系统会把一个分区或卷划分成很多块,再用一些元数据结构管理它们。以 ext 系列文件系统为例,磁盘布局通常会包含这些区域:
- 超级块(superblock):记录文件系统整体信息,例如块大小、inode 数、空闲块数量、挂载状态。
- inode 区:保存 inode。
- 数据块区:保存普通文件内容和目录内容。
- 位图或其他空闲空间结构:记录哪些 inode、哪些数据块还没被使用。
教材里常见的文件分配方式有连续分配、链式分配和索引分配。它们适合用来理解设计取舍。
连续分配把一个文件放进一段连续块里。优点是顺序读写和随机访问都很直接,只要知道起始块和长度就能定位。缺点也直接:文件增长麻烦,反复创建删除后容易留下外部碎片。
链式分配让文件块分散在磁盘各处,每个块指向下一个块。它不要求连续空间,文件扩展方便,但随机访问差。要读第 1000 个块,可能得从第 1 个块一路跟指针走过去。FAT 文件系统把这些指针集中到文件分配表里,改善了部分查找问题,但表本身又成了需要维护的元数据。
索引分配把文件的数据块地址集中放在索引块里。要读第 i 个块,先查索引块第 i 项,再去读对应数据块。它支持随机访问,也没有连续分配那种外部碎片问题,代价是要额外保存索引块。
经典 ext2/ext3 使用直接块指针、一级间接、二级间接和三级间接块定位文件数据。ext4 通常改用 extent tree:一个 extent 记录一段连续物理块的逻辑起点、物理起点和长度;对于连续大文件,它比“每个块记录一个地址”节省大量映射元数据。
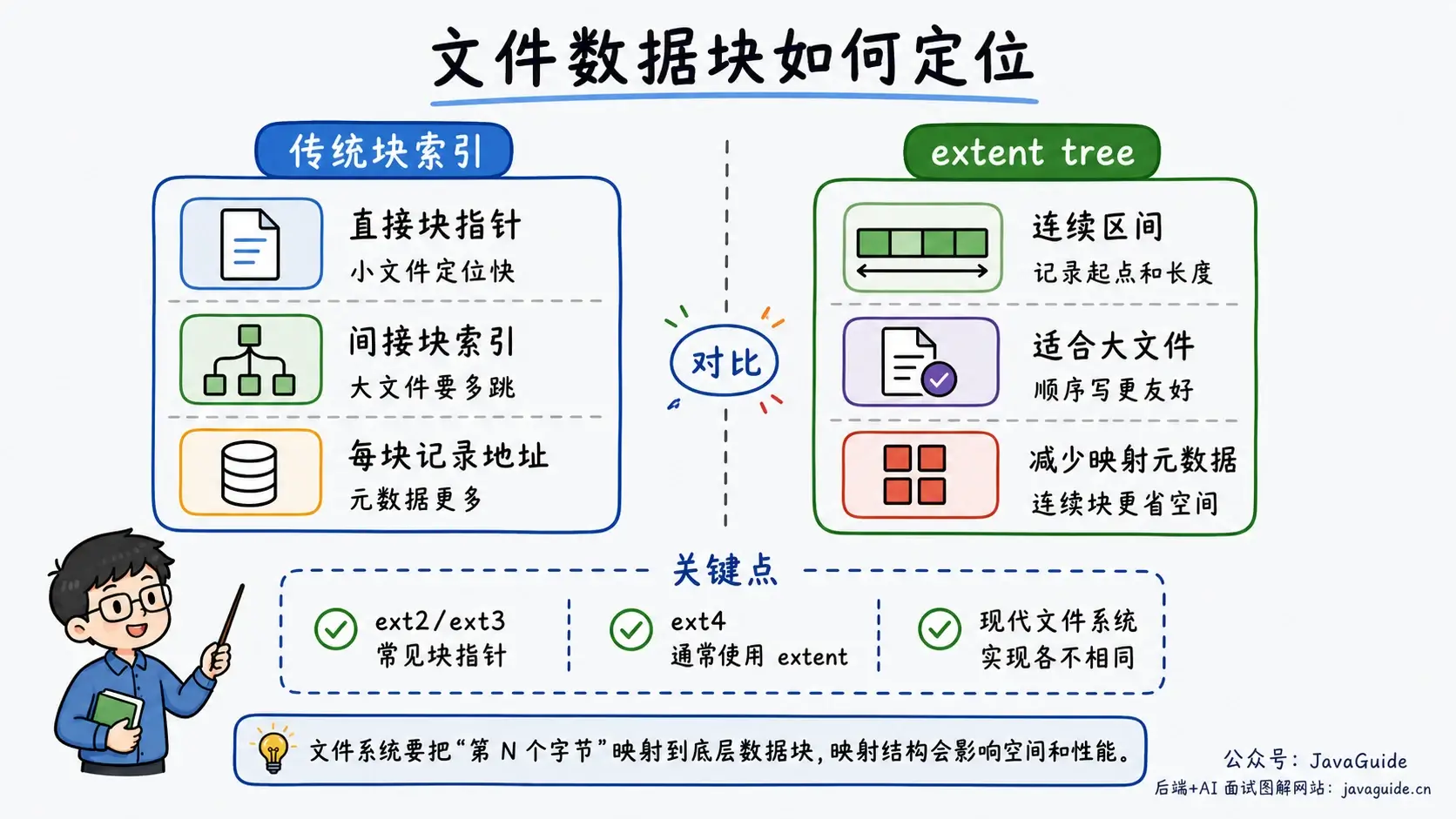
其他现代文件系统也可能使用 B 树、extent、延迟分配、写时复制等不同组合,不能把直接/间接块结构当成所有现代文件系统的统一实现。
文件删除后,原来占用的数据块要归还给文件系统;新文件写入时,又要快速找到可用块。这就是空闲空间管理。
常见方法有几类:
- 空闲表:记录每段连续空闲区域的起始块和长度。适合连续分配,但表会随着碎片增多而变复杂。
- 空闲链表:把空闲块串成链表,分配和回收单个块比较直接,但查找连续空间不方便。
- 位图:每个块对应 1 个 bit,0 表示空闲,1 表示已用。查找连续空闲块可以扫描位图,空间开销也可控。
- 成组链接:把一批空闲块地址放在一个块里,再链接到下一批,早期 Unix 系统里常见。
位图很常见。假设文件系统大小为 1 TiB,块大小为 4 KiB,那么共有 2^28 个块。每个块使用 1 bit 标记,位图大小约为 32 MiB。这个开销可以接受,换来的是清晰的块状态管理。
真实文件系统还会结合分配策略减少碎片。比如优先把同一个目录下的文件、同一个大文件的连续 extent 放得近一些,让顺序读取更友好。SSD 没有机械磁盘的寻道问题,但连续写、写放大、擦除块、TRIM 等因素仍然会影响性能和寿命。
Linux 支持 ext4、XFS、Btrfs、tmpfs、procfs、NFS 等很多文件系统。用户程序不可能为每一种文件系统写一套 open_ext4()、open_xfs()。
VFS(Virtual File System,虚拟文件系统)就是中间抽象层。应用还是调用统一的 open、read、write、close,VFS 根据目标文件所在的文件系统,把操作转发给具体实现。
Linux 官方 VFS 文档把几个对象讲得很直接:
- superblock:代表一个已挂载文件系统。
- inode:代表文件系统里的一个对象,比如普通文件、目录、FIFO。
- dentry:代表路径中的一个目录项,通常指向 inode。
- file:代表一次打开后的文件对象,也就是 fd 背后的内核结构。
有了 VFS,cat /proc/cpuinfo、cat /var/log/app.log、读取 NFS 上的文件,都可以使用相同的用户态接口。差异被压到 VFS 下面的具体文件系统实现里。
硬链接和软链接都能让一个路径关联到另一个文件,但它们指向的对象不同。
| 对比项 | 硬链接 | 软链接 |
|---|---|---|
| 指向对象 | 同一个 inode | 另一个路径 |
| 是否创建新 inode | 不创建新的目标文件 inode,只新增一个目录项并增加链接计数 | 软链接本身是一个独立文件,有自己的 inode |
| 删除源文件后 | 只要还有硬链接,数据还在 | 软链接可能变成悬空链接 |
| 是否能跨文件系统 | 不能 | 可以 |
| 是否能链接目录 | Linux 不允许通过普通硬链接接口链接目录 | 可以 |
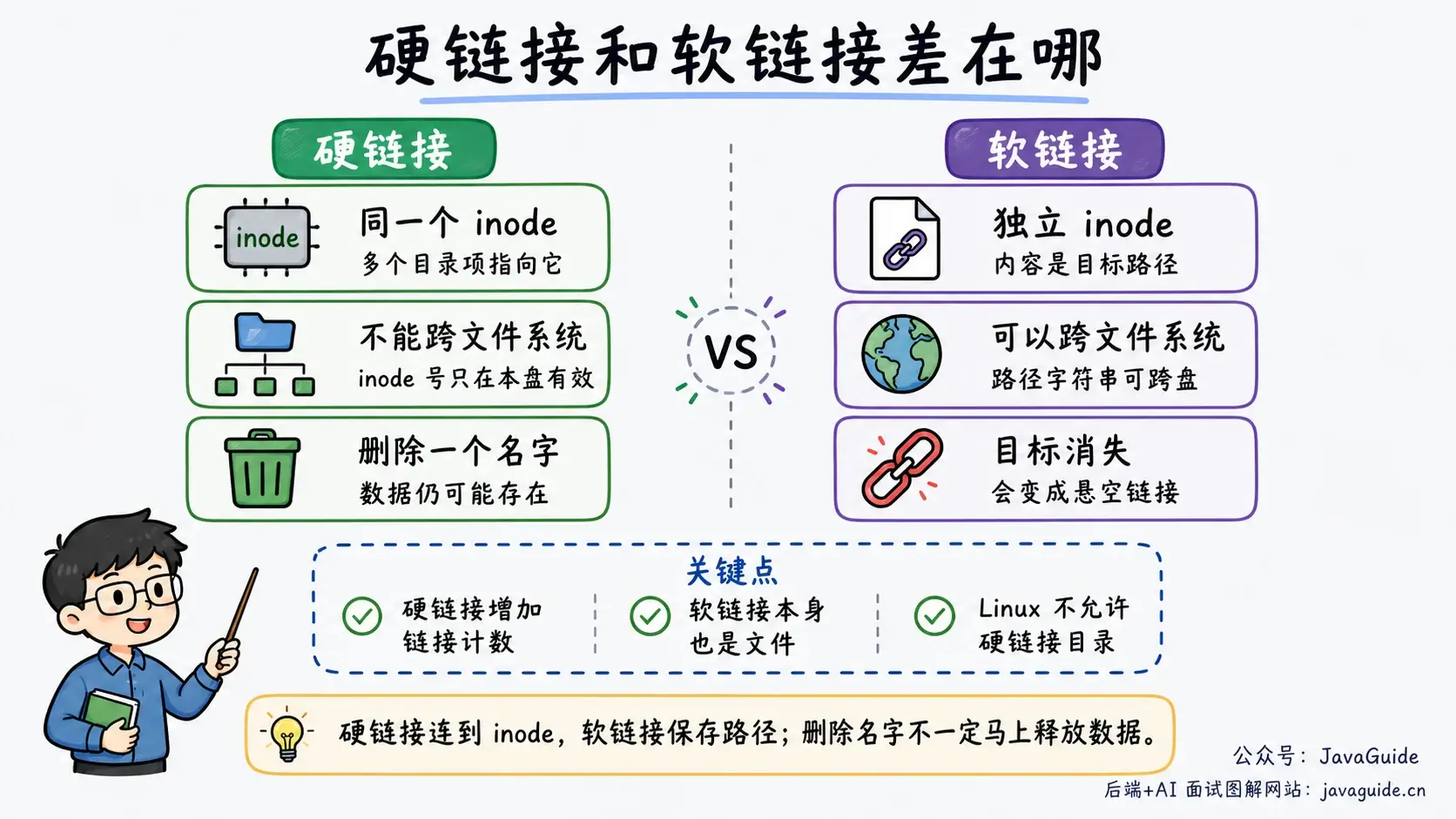
硬链接不能跨文件系统,因为 inode 号只在当前文件系统内有意义。另一个文件系统有自己的 inode 表,同一个数字不代表同一个文件。
可以用下面的命令做个小实验:
echo hello > a.txt
ln a.txt hard.txt
ln -s a.txt soft.txt
ls -li a.txt hard.txt soft.txt你会看到 a.txt 和 hard.txt 的 inode 号相同,soft.txt 的 inode 号不同。删除 a.txt 后,hard.txt 还能读到内容,soft.txt 会指向一个不存在的路径。
直接读写磁盘太慢。Linux 会用 Page Cache 缓存文件数据,把磁盘文件的一部分页保存在内存里。
读文件时,如果目标页已经在 Page Cache 中,内核可以直接从内存复制给用户态,不需要真的读盘。没有命中时,才从磁盘把页读进 Page Cache,再返回给应用。
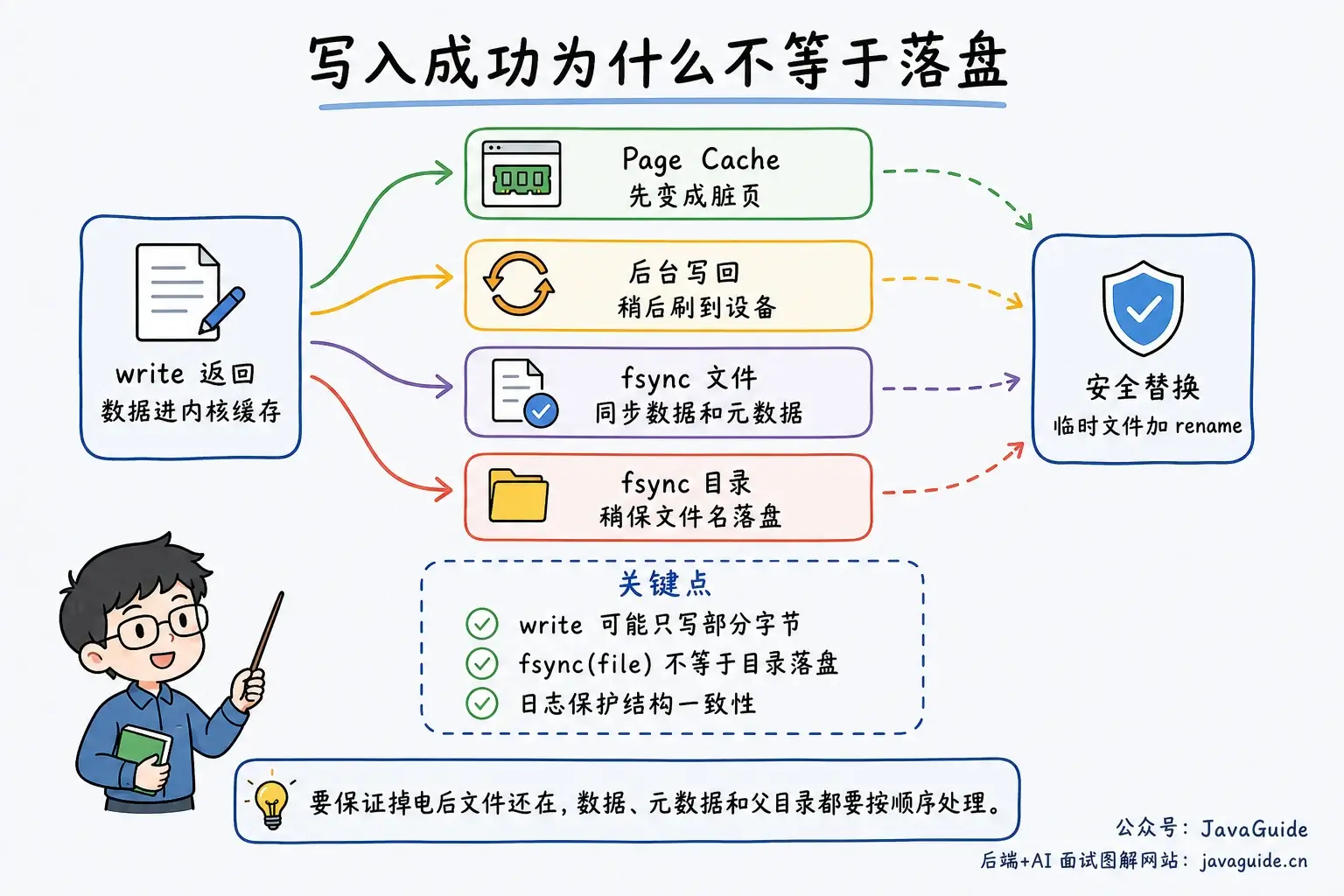
对于普通文件的 buffered I/O,write() 成功通常只表示数据已经被内核接收,常见情况是进入 Page Cache 并被标记为脏页。它既不保证完整写入请求的全部字节,也不保证数据已经持久化到底层设备。调用方要处理 partial write;如果需要持久性,还要检查 fsync()、fdatasync() 和 close() 的错误。
fdatasync() 也会同步文件数据,但只同步后续读取数据所必需的元数据,例如文件大小;fsync() 则同步文件数据和更完整的关联元数据。这里说的是普通 buffered I/O,O_DIRECT、O_SYNC、DAX 等路径会改变具体行为。
代价是崩溃风险。进程写完文件后,如果机器突然掉电,已经返回成功的写入不一定都落盘。需要更强持久性时,要使用 fsync()、fdatasync() 或带同步语义的打开标志,但这些操作会让应用等待刷盘,吞吐会下降。
还有一个很容易漏掉的点:fsync(fileFd) 只同步文件本身,不一定同步父目录中的文件名变化。创建新文件、执行 rename() 或 unlink() 后,如果要求掉电后目录项也可靠持久化,还需要打开父目录并对目录 fd 调用 fsync()。
一个典型的安全替换流程是:在同一目录创建临时文件,写入完整内容,对临时文件调用 fsync(),再用 rename() 原子替换目标文件,最后对父目录调用 fsync()。同一文件系统内的 rename() 可以原子替换目标名称,但“命名空间操作原子”不等于“掉电后一定持久”。
数据库、消息队列、日志系统都绕不开这点。它们经常自己管理刷盘策略:有的追求每次事务提交都尽量落盘,有的允许短窗口内的数据丢失来换取吞吐。这里没有通用最优解,只有业务能接受的恢复点目标。
文件系统最怕写到一半崩溃。比如创建文件时,既要分配 inode,又要分配数据块,还要更新目录项和位图。只写完其中一部分就断电,文件系统可能处于不一致状态。
日志文件系统(journaling filesystem)会先把即将进行的元数据变更写入日志区域,之后再更新正式位置。系统恢复时会扫描日志:已经完整提交、但还没全部写回正式位置的事务可以重放;没有 commit record 或校验失败的事务会被丢弃。日志的目标是避免文件系统结构停在“只更新了一半”的状态。
以 ext4 为例,官方文档列了 3 种数据模式:
data=writeback:只保证元数据日志,不保证相关数据块先于元数据写入。性能通常更好,但崩溃后新写文件里可能出现旧数据。data=ordered:默认模式。元数据进入日志前,相关数据块会先写到主文件系统。它没有把文件数据本身写进日志,但降低了元数据指向未写数据的风险。data=journal:数据和元数据都先写日志,再写最终位置。对经过日志的数据提供更强的崩溃一致性保证,但写放大和性能成本也更高。
日志文件系统解决的是“文件系统结构一致性”,不是替应用保证所有业务数据都不丢。应用要保证事务级持久性,仍然要正确使用 fsync(),并处理重命名、临时文件、目录刷盘这些细节。
排查文件系统问题,不要只盯磁盘容量。下面这些指标更常见。
inode 是否用完:
df -i小文件过多时,inode 可能比容量更早耗尽。
文件描述符是否泄露:
ulimit -n
cat /proc/<pid>/limits
lsof -p <pid>
ls /proc/<pid>/fd | wc -l服务报 Too many open files 时,先看进程 fd 上限和当前 fd 数,再查有没有连接、日志文件、临时文件没有关闭。这里也要区分两类错误:EMFILE 表示当前进程的文件描述符达到上限,ENFILE 表示系统范围内的打开文件数量达到上限。
多线程程序创建 fd 时,尽量优先使用 O_CLOEXEC 这类原子 close-on-exec 选项,避免 fd 意外泄漏到 exec() 后的新程序。
Page Cache 大小和内存压力:
free -h
vmstat 1free -h 和 vmstat 1 可以辅助判断缓存规模、内存压力、换页和 I/O 活动,但不能直接得出 Page Cache 命中率。Linux 会尽量用空闲内存做缓存,所以 free 里 buff/cache 很大不一定是坏事。真正要看的是应用是否频繁等待 I/O、是否有大量回写、是否因为内存压力导致缓存被反复回收。
需要观察具体文件的缓存页面时,新版 Linux 提供 cachestat();也可以使用基于 eBPF 的 cachestat 一类工具,但生产使用前要评估采集开销。
磁盘是否繁忙:
iostat -x 1对于传统串行设备,%util 长期接近 100% 可能意味着设备繁忙。但对于 NVMe SSD、RAID 和其他可以并行处理多个请求的设备,%util 不能直接等同于饱和度。还要结合 await、r_await、w_await、aqu-sz、吞吐量、IOPS 以及应用端延迟一起判断。
df 很满,du 却找不到大文件:
lsof +L1
ls -l /proc/<pid>/fddu 统计目录树中仍有名字的文件;df 统计文件系统已经分配的块。如果一个大日志已经被 unlink(),但进程还保持 fd 打开,它不会再出现在目录遍历结果里,du 看不到它;底层空间却还没释放,所以 df 仍然很高。处理时通常应该让进程重新打开日志文件,或者正常重启服务,不要直接对 /proc/<pid>/fd/* 做未经验证的破坏性操作。
小 G 这里也留一个限制:不同文件系统、内核版本、挂载参数、硬件缓存策略都会改变表现。比如 O_DIRECT 在 Linux 下还有对齐限制,而且限制会随文件系统和内核版本变化。做性能判断时,最好结合当前系统的 mount、uname -a、fio 或真实业务压测结果,不要只按教材结论下判断。
如果面试问“文件系统是什么”,可以按这条线回答:
文件系统负责把存储设备上的块组织成用户能理解的文件和目录。它要管理命名、目录、元数据、数据块分配、空闲空间、权限、缓存和崩溃恢复。
讲 Linux 时,可以继续补上 inode、dentry、file 和 superblock。文件名保存在目录项里,inode 保存文件元数据和数据块位置;open() 解析路径、检查权限后返回 fd,fd 指向一次打开后的文件对象,读写时再通过 VFS 调到具体文件系统。
如果追问“硬链接和软链接”,抓住一句话:硬链接是多个目录项指向同一个 inode,软链接是一个独立文件,内容是目标路径。
如果追问“为什么写完文件还可能丢”,回答 Page Cache 和写回策略:write() 成功通常只代表数据进入内核缓存,不代表已经持久化;需要更强保证时要配合 fsync()、日志机制和正确的写入顺序。
- Linux Kernel Documentation: Overview of the Linux Virtual File System
- Linux Kernel Documentation: ext4 General Information
- Linux Kernel Documentation: ext4 Directory Entries
- Linux Kernel Documentation: ext4 inode.i_block / Extent Tree
- Linux Kernel Documentation: ext4 Inline Data
- Linux man-pages: open(2)
- Linux man-pages: write(2)
- Linux man-pages: fsync(2)
- Linux man-pages: unlink(2)
- Linux man-pages: link(2)
- Linux man-pages: mmap(2)
- Linux man-pages: cachestat(2)
- Linux man-pages: ext4(5)
- Linux man-pages: iostat(1)
- The Open Group: open - open a file
- 王道考研操作系统知识点整理: 4.2、文件系统实现
- 计算机考研杂货铺: 文件
- 计算机考研杂货铺: 目录
- 计算机考研杂货铺: 文件系统
- JavaGuide 操作系统专题:操作系统常见面试题总结
- JavaGuide 零拷贝详解:zero-copy.md