- Team interactions must evolve as product / tech matures
- Not a prescription, more of a collection of best practices
- Part 1: Conway's law and how org interrelationships constrain system design
- Part 2: Proven patterns and the implications of choosing each; aligning teams to areas of your system
- Part 3: Evolving org design to be adaptive, able to rapidly respond
- Four team types:
- Stream-aligned team
- Enabling team
- Complicated-subsystem team
- Platform team
- Three interaction modes
- Collaboration
- X-as-a-Service
- Facilitating
-
Key take-aways
- Conway's law suggest major gains from designing software arch and team interactions together
- Team Topologies clarifies team purpose and responsibility to improve interrelationships
- Humanistic approach to building software while setting org up for adaptability
-
Rapid, safe software development in a changing market and regulatory structure requires a team with a wide skillset. Orgs are still creating teams that rely heavily on org charts / matrices, splitting work non-sensically.
-
Traditional org chart is useful for regulatory / legal purposes, but is antithetical to the uncertain, collaborative nature of software dev. Need to rely on decoupled, long-lived teams that can collaborate effectively instead of siloed teams that tend to stay within those silos.
- In practice, people communicate laterally / horizontally across reporting lines to solve actual problems. Enable this.
- Org charts don't reflect how people actually communicate to accomplish outcomes and encourage ineffective allocation of work and responsibilities, similar to how a software arch doc will be outdated as soon as dev starts. Understanding the expected vs actual communication patterns and resulting gaps can inform better systems for the org.
- Decisions based on org chart structure optimize locally, for only a segment of the org, but may not address more important bottlenecks in the stream of work(e.g., adopting IaC reduces infra provisioning time, but if every change requires approval with long lead time then delivery will remain stunted). Systems thinking focuses on looking at the overall flow of work, identifying the largest bottleneck, and eliminating it, then repeating - Organizing teams to address the bottleneck of rigid team structures with poor communication supports that cycle.
- 3 org structures in every org
- Formal structure(Org chart) -> Compliance
- Informal structure -> "Realm of influence" between individuals
- Value creation structure -> How work gets done based on inter-personal and inter-team comm
- Key to successful knowledge work is in the interactions between Informal and Value creation(i.e., interactions between people and teams). Empowering teams as fundamental building blocks -> cohesive teams -> clearer inter-team behaviors and more trust.
- Other mgmt approaches create an org design that remains static and does not account for behaviors and structures post-creation(e.g., Matrix mgmt gives employees both a functional and biz mgr, but the view becomes outdated as soon as biz or tech domain evolves).
- Leads to a cycle of reorgs, which consistently causes employee fear and feelings of setback and routinely breaks down established communication patterns and cohesive teams.
- 5 rules of thumb for org design
- Design when there is a compelling reason
- Develop options for deciding on a design
- Choose the right time to design
- Look for clues that things are mis-aligned
- Stay alert to the future
- 4 fundamental team types: Stream-aligned; platform; enabling; complicated-subsystem
- 3 core team interaction modes: collaboration; x-as-a-service; facilitating
- Combines team types, interaction modes with awareness of Conway's law, team cognitive load, and a "sensing" organization.
- Teams evolve with tech and org maturity: Tech and product discovery require high collaboration and overlapping boundaries; post-discovery, these can lead to wasted effort and misunderstandings.
- Adaptive model allows orgs to sense when strategy change is needed from biz or tech viewpoint.
- Emphasizes humanistic team approach - Team is indivisible, has a finite cognitive load cap that must be respected.
- "Orgs which design systems... are constrained to produce designs which are copies of the communication structures of these orgs."
- i.e., the strong correlation between org's real communication paths and the resulting software architecture
- Building software requires understanding of inter-team communication patterns to determine what arch is feasible. If the desired arch doesn't fit the org model, either the arch or the org must change.
- Inverse Conway: Predicting Conway's law, organizing teams to match the arch they want the system to exhibit rather than expecting teams to follow a mandated arch design.
- Team's cognitive load is sum of all team members' cognitive loads. Rarely discussed when assigning team responsibilities, perhaps because hard to quantify; or because team is expected to adapt without question. Either way, new development / responsibilities are frequently doled out assuming the team(s) have low cognitive load to start.
- Ignoring team cognitive load => Teams spread too thin to develop mastery of their trade; high context switching.
- e.g., a successful Build team may grow to encompass CI, CD, and Infra Automation, at which point prioritization is too difficult and context switching is constant.
- Team Topologies advocates org design optimized for flow of change, requires restricting team cognitive load and explicitly designing inter-team communication for desired arch outcome.
- Historical approaches to software org see it as mfg, completed by individuals arranged into functional specialities, with large projects planned up front and no regard for sociotechnical dynamics, leading to flow obstacles: Disengaged teams; pushing against Conway; Software outsized for team; Confusing org design options; Frequent re-orgs; Many surprises / context switching.
- Agile / Lean / Devops encouraged big technological strides(automation, tooling), but have done less for addressing cultural and org changes.
- Traditional org charts don't match need to reshape teams for collaborative knowledge work in uncertain environments, ignore Conway.
- Key take-aways
- Orgs are constrained to produce designs that reflect communication paths
- Design of the org constrains "solution search space", limiting possible designs
- Requiring everybody to communicate with everybody will not work
- Choose archs that encourage team-scoped flow
- Limiting comm paths to well-defined team interactions produces modular, decoupled systems
- Remains relevant even in the age of microservices, cloud, containers, etc.
- Monolithic database anti-pattern: Couple dependent apps to themselves and become magnets for biz logic changes at the db level. Avoiding them requires an org to have both good arch practices and also team structures that align with a desire not to have a monolithic db.
- Adidas: Restructured via Conway => IT becoming a product-oriented org, in which 80% of org was responsible for in-house software delivery capabilities via x-func teams aligned with biz needs; 20% dedicated to central-platform team taking care of eng platforms and tech evolution, as well as consulting and onboarding => Much faster release cycle + higher software quality.
- Also studies by Alan MacCormack and in other industries support Conway concept.
- "If the arch of the system and the arch of the org are at odds, the arch of the org wins."
- e.g., an org that is arranged in functional silos(QA, DBA, etc) is unlikely to ever produce systems that optimize for end-to-end flow; an org arranged around sales channels for different geo regions is unlikely to produce effective software arch the provides multiple services to all regions.
- Orgs are unlikely to discover / sustain archs because the communication paths simply don't exist, either formally or informally.
- Can be used to discourage undesirable design: If we want to discourage designs focused solely on technical internals, reshape to avoid this.
- or to encourage desirable: If we want to encourage designs that facilitate flow, reshape to do so.
- No guarantee that designing for Conway will force the designs we want to encourage, but we are making it more likely by shaping the communication path.
- Also ref'd as a key support in Accelerate
- Monolithic database anti-pattern: In some cases, no stable teams and many temporary projects => apps deeply coupled at the db level via sprocs => impossible to migrate to commodity systems for certain parts of the biz since they couldn't be decoupled => Engineers forced to support undesirable outcome instead of serving new needs.
- Simplified example: Four teams, each with front-end and back-end devs, who work on different system parts and hand off to a DBA for db changes(i.e., all four teams' work are eventually bottlnecked at the dba and ops level)
- Given this, we expect each team to have a separate front-end and back-end and a single, shared core database. The existence of a shared DBA team is likely to yield a single shared database; and the existence of both front-end and back-end devs is likely to drive a separation of UI and app tiers. Nothing wrong with this if it's what was intended.
- What if we don't want a single shared db, though? e.g., we want to move to microservices with siloed data
- Conway is exerting a natural pull into the shared db via entrenched communication mandates / flows.
- We can redesign into four teams: Each with front-end, back-end, and dba. Conway will naturally encourage these teams to have their own dbs.
- We need to understand required arch before organizing teams.
- Practices that encourage fast-flow within the team:
- Loose coupling: Components don't hold strong deps on other components
- High cohesion: Components have clearly bounded responsibilities, internal elements are strongly related.
- Clear and appropriate version compat
- Clear and appropriate cross-team testing
- Arch should resemble the flows of change they enable: Instead of series of inter-connected components, we design flows on top of an underlying platform.
- Keeping things team-sized promotes ease of understanding by limiting module size, promotes ease of contribution by minimizing propagation of design changes. Optimizes for people's ability to work on the software.
- Keeping things decoupled and team-scoped => increased rate of flow of change, simpler to change the arch to suit new contexts.
- If we accept Conway - i.e., that org structure drives arch - then we also accept that anybody making decisions about the shape of the org is strongly influencing the arch. Thus, technical leaders must be involved in org design.
- This echoes down to service creation and who builds them, etc.
- Not all collaboration and communication is desired / good, so we need to define team interfaces to set expectations around hwat kind of work requires collab and doesn't. More communication is not better.
- Focused communication between specific teams is the goal. Need to look for unexpected communication and address the cause.
- If teams shouldn't need to communicate based on software arch, then what is driving the communication? API mismatch, unsuitable platform, missing component, etc.
- In-person, can separate teams physically(by floor, wing, etc). Virtually, need to examine inter-team comm patterns.
- If a large team regularly deals with multiple areas, can be useful to split it into n smaller teams dedicated to each but made from the same people. If the team works on more than one part by design(e.g., supports an older component and a newer service), keep them together.
- Teams may communicate simply because they share a repo or are a part of the same app or service even though they logically ought to be separate. Use fracture planes to split into smaller chunks, separate repos.
- A system where everyone needs to know everything will encourage a lack of modularity via Conway.
- An org that expects that "everyone should see every chat message" or "everyone needs to be present in every meeting" will similarly encourage monolithic, coupled systems.
- Tool Choices Drive Communication Patterns
- tl;dr: Don't select a single tool for the whole org without considering team inter-relationships. May be helpful to have separate tools for independent teams, shared tools for collab teams.
- Sometimes an org has multiple tools when a single would suffice(single pane), while other times a single tool is used and teams would be better served with separate.
- Because tools often effect how teams interact, they have a Conway impact: Shared tools may encourage collaboration, separate may encourage clear responsibilities and boundaries.
- e.g., if we need a dev team to work closely with IT operations, then having separate ticketing or incident management tools for the two teams will encourage poor inter-team communications.
- Having a "production only" tool that is limited to teams with security access and that effects teams' software will encourage additional communication.
- When team responsibilities don't overlap and shouldn't need to communicate, little value in insisting on the same incident-tracking or monitoring tool.
- Many Different Components Teams
- aka complicated-subsystems teams. Sometimes needed but only for exceptional cases where detailed expertise is required. Prefer stream-aligned teams.
- Repeated Reorgs that Create Fiefdoms or Reduce Headcount
- Historical reorgs have sought to reduce staff or carve out fiefdoms for leaders. This is antithetical to designing an org for Conway.
- Regular reorgs for mgmt convenience / headcount reduction destroy the org's ability to build and operate software effectively. Reorgs that ignore Conway, team cognitive load, and related are highly destructive.
- Conway's law implies a strong correlation between software arch and org design.
- Org design will limit the number of possible solutions for any given problem and affect delivery speed via inter-team dependencies.
- Fast flow requires restricting inter-team comm. Team collab is needed for uncertain development where discovery and expertise are required to advance. Team collab is detrimental in mature areas where execution is the focus.
- Reverse Conway can help leaders decide on a structure that fits their desired arch rather than allowing the structure to dictate the arch on its own.
-
Key take-aways
- The team is the most effective means of software delivery, not individuals
- Limit size of multi-team groupings within the org based on Dunbar's number
- Dunbar's number: a suggested cognitive limit to the number of people with whom one can maintain stable social relationships
- Restrict team responsibilities to match max team cognitive load
- Change team working env to help teams succeed
-
Org behavior experts have routinely found that cohesive teams perform better than collections of individuals for knowledge-rich, problem-solving tasks requiring lots of info.
- Even Army General writes that best-performing teams "accomplish remarkable feats not simply because of the individual qualifications of their members but because those members coalesce into a single organism."
- Google finds that team performance is dictated less by the individuals than by team dynaics; and that when measuring performance, teams matter more than individuals.
- Team: A stable grouping of 5-9 people who work toward a shared goal as a unit. The smallest entity of delivery within the org(e.g., work should never be assigned to individuals, always to a team).
- Teams larger than 9 may start to break down trust between team members as we get further away from Dunbar's numbers. High trust yields innovative teams. Low trust will slow delivery.
- Very high-trust orgs may exceed this number up to the limit of 15, but this is very rare.
- Limit on size and Dunbar's number applies to groupings of teams, departments, streams of work, lines of biz, etc.
- Limits to relationship depth:
- 5 people: Number with whom we can hold close personal relationships and working memory
- 15 people: Number with whom we can experience deep trust
- 50 people: Number with whom we can have mutual trust
- 150 people: Number whose capabilities we can remember
- If the size of a group grows too large for necessary trust level, it won't be as effective, so:
- Team: 5-9 people, or 15 if the org is VERY high-trust
- Families: Groupings of teams of no more than 50 people, or 150 if the org is VERY high-trust
- Divisions / streams / P&L lines: Groupings of no more than 150 people, or 500 if the org is VERY high-trust
- When a level gets too big, it naturally indicates a need for another semi-independent grouping. New groupings should take care to limit based on number of biz lines or streams of work, and arch may need to be realigned for effective ongoing ownership.
- Software arch will be expected to change to fit Dunbar's number as org grows.
- Teams take time to coalesce, maybe weeks or months, but is much more effective once they get there. Thus, reassigning people after the end of a six-month project where they've only just hit their stride will yield little value(Mythical Man Month: Adding people to existing projects will slow those projects for some amount of time).
- Instead of flowing people to teams to do work, flow work to long-lived teams.
- Teams should be stable but not static, changing only occasionally and when necessary.
- In high-trust orgs, people may change teams ~once/year. In typical orgs, should be longer(18-24 months), and the team should be coached to improve and sustain cohesion.
- The Tuckman Teal Team Performance Model
- Forming: Assembling for the first time
- Storming: Working through initial differences in personality and ways of working
- Recently, research has shown that Storming may take place continually throughout the lifecycle, so teams should be coached to maintain performance.
- Norming: Evolving standard ways of working together
- Performing: Reaching a high state of effectiveness
- Team ownership fosters continuity of care and enables teams to think in multiple "horizons" - from Exploration to Exploitation to Execution.
- Exploration: Immediate future with products and services that will deliver results the same year
- Exploitation: Next few periods, in which we expand the reach of the products and services
- Experimentation: Far future, where experimentation is needed to assess market fit and suitability of new services, products, features.
- Multi-team ownership encourages a lack of ownership in practice.
- Single-team ownership allows the team to make sensible short-term decisions(e.g., a dirty bug fix that they can remove in a bit).
- Every part of the system must be owned by exactly one team. Teams may use and contribute to shared systems, but they cannot make changes without owners.
- Not territorial - Teams are stewards rather than private owners.
- Since the team is the smallest unit of delivery, the individuals must have a team-first mindset i.e., the team's needs are more important than the individuals':
- Arrive at meetings on time
- Keep discussions and investigations on track
- Encourage a focus on team goals
- Help unblock teammates before starting new work.
- Mentor less experienced team members.
- Avoid "winning" arguments and, instead, agree to explore options.
- Some people are unsuitable to teamwork or unwilling to put the team above themselves. These people must be removed.
- Diverse backgrounds yield more creative solutions more quickly by more empathetic teams.
- Rewarding individual performance in modern orgs tends to drive poor results and damages staff behavior(e.g., tying individual bonus to company profitability may fail to reward outstanding performance due to down years, misaligning individual merit and the actual bonus received).
- Reward the whole team for their combined effort - e.g., Pay difference should be small across org, bonuses small and applied on team basis and company performance, not individual performance; training budget should be at the team level to allow the team to decide if one person is particularly suited to going and bringing back valuable insights; etc.
- Increasing size and complexity of modern codebases creates unbounded cognitive load.
- Traditional ops/infra teams may suffer overwhelming cognitive load due to the number of domains of responsibility, number of apps they need to operate, number of tools they need to manage.
- Team-first approach matches responsibility to what the team can handle e.g., by limiting the size of the system that a team is expected to work with, and not allowing the system to grow beyond the cognitive load of the team.
- 3 types of cognitive load
- Intrinsic: Aspects of the task fundamental to the problem space(e.g., how do i create a class, define a method, knowledge of c#)
- Extraneous: Environment in which the task is being done(e.g., how do i deploy this app, how do i configure this service, knowledge of how to spin up a container env for the app)
- Germane: Aspects that need special attention for learning or high performance(e.g., how should this service interact with our invoicing system)
- Minimize intrinsic cognitive load(through training, tech choices, pairing, etc); eliminate extraneous(through automating repetitive tasks); make room for germane, which is where the value-add thinking occurs.
- Many orgs assume that by assigning more teams to the load, the load will be shared across those teams. Instead, the teams will suffer from communication issues.
- Exceeding team's cog load => lower performing unit of individuals rather than team, each trying to accomplish their own tasks without considering team interest.
- Simple check: Ask the team, "Do you feel like you're effective and able to respond in a timely fashion to the work you are asked to do?" If response is clearly negative, determine if cognitive load is too high, and takes steps to reduce the load.
- Do not measure lines of code, number of modules, etc, as they aren't reliable.
- Key is the complexity of the problem the software is trying to solve(i.e., Domain Complexity) - e.g., Running and evolving a CI/CD toolchain may require a substantial amount of integration and testing but very little actual code.
- e.g., a team tasked with too many domains may have too much work with lots of context switching yielding a feeling that the team lacked sufficient domain knowledge but had no time to acquire it. Most of their load is extraneous, leaving very little for value-add intrinsic or germane.
- Instead, split into micro-teams, each responsible for a single domain / product area(IDE productivity; platform-server productivity; infrastructure automation). Productivity teams are colo. Overlapping domains rare, so new structure allowed teams to collaborate closely on cross-domain issues without needing the single-team permanent structure. Micro-teams slowly master their new domains, context switching drops, flow improves.
- There is no "right number" - domains aren't static, nor are teams' cognitive capacity. Reasoning around relative domain complexity - with a focus on how the responsible team feels about the domain's complexity - can help shape appropriate responsibilities and boundaries.
- Do not downplay complexity("there are plenty of tools for continuous delivery, it's not difficult") in order to pack more domains into a team.
- Identifying and Assigning Domains
- Identify distinct domains that each team deals with -> Classify these into Simple(most work has a clear path of action), Complicated(changes need to be analyzed and might require a few iterations to get right), or Complex(solutions require lots of experimentation and discovery). Refine classifications by comparing domain pairs across teams(How does Domain A compare to B? Do they have similar complexity or is one more clearly complex than the other? Does the current classification reflect that?)
- Assign each domain to a single team. If a domain is too large for one team, split the domain into sub-domains, then assign the sub-domains.
- A single team of 7-9 people should be able to accomodate 2-3 "simple" domains, where context switching is relatively cheap(e.g., older software that has straightforward maintenance needs)
- A single team of 7-9 people can handle only one "complex" domain and should not take on even a single "simple", as the cost of disrupting work on the "complex" to context switch; and tendency to prioritize the "simple" fixes above the more complex.
- Avoid a single team responsible for two "complicated" domains. In practice, the team may behave as two subteams, one for each domain, yet everybody will be expected to know both. Split the teams into two teams of five(by increasing headcount) instead to encourage focus and autonomy.
- Instead of designing a system in the abstract, design to fit the available cognitive load within delivery teams.
- e.g., instead of choosing Monolith vs Microservices, design the software to fit the max team cog load.
- Every subsystem must be sized for a single team.
- To increase the size of the softwware or domain for which a team is responsible, work to maximize its cognitive load capacity:
- Provide a team-first working env
- Minimize distractions by limiting meetings, reducing messages, assigning a dedicated team or person to support questions, etc.
- Change mgmt style by communicating goals and outcomes rather than obsessing over the "how"("eyes on, hands off")
- Increase the qualify of developer experience for other teams using your team's code and APIs through documentation, consistency, UX, etc
- Use a platform that is explicitly designed to reduce cognitive load for teams building software on it.
- Minimizing extraneous load frees up space for larger domains.
- If the team isn't currently set up this way, they will need to take on smaller domains in the meantime.
- Team-first approach also encourages teams to develop a shared mental model of their domain, which is a good predictor of team performance.
- With stable teams, can build a stable api surrounding each team:
- Code: runtime endpoints, libraries, etc produced by the team
- Versioning: how the team communicates changes(e.g., semver)
- Docs: especially how-to guides for owned software
- Practices and Principles: team's preferred way of working
- Communication: team's approach to remote comm tools
- Work info: what the team is working on now, what's next, and overall priorities in the short-medium term
- Other: anything else that teams need to interact with the team
- Team API should explicity target usability by other teams: Will they find it easy to interact with us, will it be easy to onboard new teams to our codebase and working practices, how do we respond to PRs, are we communicating our priorities, etc.
- API must be continuously defined, advertised, tested, and evolved to ensure that it fits the needs of other teams
- e.g., Pivotal Cloud Foundry, "try to maintain... API-based separation of concerns between teams. We try not to share code bases between teams. All repos for a team's feature are wholly owned by that team."
- e.g., AWS, assume that "every other team becomes a potential denial of service attacker requiring service levels, quotas, and throttling."
- Setting aside explicit time for teams and people to communicate and learn facilitate trust building and learning. e.g., consciously designed physical and virtual environment, time for teams to attend communities of practice.
- Some tasks require full concentration, low noise; others require high collab. Design your environment to facilitate what teams need at any given time - Focused individual work, collab intra-team work, collab inter-team work.
- Virtual env is as important as physical: Documentation, blogs, chat tools, etc.
- Give chat tool spaces obvious names that are easy to predict / search
- CI/CD, TDD, SOLID, etc are all foundational to making any of this work.
- The team is the smallest unit of delivery.
- Teams are small and long-lived, allowing members to develop their working patterns and dynamics.
- Cognitive load must be managed, and teams must have sole ownership over an amount of cognitive load they can handle.
- Team-first allows diverse people to thrive, as they can shine in their respective areas of strength within the team's context; and the org can better support diverse communication needs, from those who are good 1:1 to those who are better in a group, while limiting the communication scope of destructive individuals.
- Key Take-aways
- Ad hoc or constantly changing team design slows down software delivery
- There is no single definitive team topolgy but several inadequate topologies for any one org
- Technical and cultural maturity, org scale, and engineering discipline are critical aspects when considering topology
- Particularly, feature-team/product-team pattern is powerful but only works with a supporting environment
- Splitting a team's responsibilities can break silos and empower other teams
- Ad hoc team design including teams that have grown too large and been broken up as the comm overhead takes a toll; teams created to take care of all COTS software or all middleware; or a DBA team created after a production crash due to poor database handling. Each of these deserves action, but consideration of the broader context is important to avoid slowing down delivery and reducing autonomy.
- Shuffling team members, using volatile teams assembled on a project basis and disassembled after. Ignores the cost of forming new teams and swapping contexts constantly.
- Design teams that emphasize the flow of change from concept to working software.
- Spotify example: Small, autonomous, cross-functional squads of 5-9, each with a long-term mission. Squads in similar areas are a tribe, and stay aware of their fellow squads' work. Engineers within a tribe with similar skills share practices through a chapter(e.g., QA across squads belong to a testing chapter). Management is also by chapter, but the chapter lead also belongs to a squad. Guilds are communities of practice from multiple tribes, chapters, and squads.
- Dev isn't linear(Dev -> Test -> Transition -> Maintenance)
- Teams must be production-aware, "cross-functional, with all skills necessary to design, develop, test, deploy, and operate the system on the same team." => More customer-focused teams.
- DevOps intended to address gap between software delivery speed and ops teams' capacity to provide resources or deploy updates.
- DevOps focuses on team interaction(or lack of) across the delivery chain(leading to rework, failures, etc).
- DevOps topologies reflect two ideas: No one size fits all approach to structuring teams for DevOps success, must base it on context; there are several anti-patterns that should be avoided.
- Feature teams: Cross-functional, cross-component teams that can take a customer-facing feature from idea to production, including observability in production.
- Pros
- Cross-functional teams can deliver cross-cutting features faster than component teams working in sync
- Cons
- Can only work if the feature team is entirely self-sufficient
- Team often must touch multiple codebases owned by multiple teams, so must have the maturity to do so responsibly: Must provide automated tests, must clean up "bad" code they find, etc. Otherwise, teams will distruct the x-func team.
- Lack of ownership may develop if inter-team discipline isn't high.
- In an org of feature teams, important to have architect roles responsible for ensuring cohesive UX, performance baselines, and reliability. This role interfaces with many feature teams on cross-subsystem concerns.
- Product teams: Cross-functional, cross-component teams that own a set of customer-facing features(a product) from idea to production, including observability in production.
- Due to cognitive load capacity, likely to need help with some of their dependencies(build systems, delivery pipelines, etc)
- Key for autonomy to ensure external deps don't block deployment of new features(e.g., that the team won't have to wait on QA team capacity before shipping). Often accomplished via self-service capabilities(e.g., around provisioning envs, creating deployment pipelines, monitoring, etc) that are maintained by other teams.
- Product teams without a compatible support system will hit more bottlenecks and will get trapped between the pressure to deliver faster and the external dependencies' inability to keep up.
- Ops teams masquerading as cloud teams won't deliver the expected value, as they won't eliminate bottlenecks.
- Cloud teams must own the provisioning process(ensuring compliance and auditing), but product teams must have the autonomy to provision their own resoruces, including new images and templates. Split is between designing the cloud process and the actual provisioning, which will be performed by teams.
- SRE should have strong coding skills and desire for automation, using an error budget to guide the speed of delivery.
- SRE is optional - If a project is shrinking in scale, allow the dev team to own the SRE work.
- SRE cycle:
- Dev team develops product, including initial production releases, without SRE support
- As product scales, SRE guides the team on hardening it for scale
- At large scale, SRE becomes fully involved by running and supporting the app up to a certain error budget
- Application team takes ownership back if error budget is breached or app usage declines to no longer require SRE support
- Needs high ongoing commitment from leadership, else prone to devolving into SRE vs App Team silos
- Technical and Cultural Maturity
- Orgs adopting small batches of delivery may lack mature engineering practices required to keep a sustainable pace over time(e.g., automated testing, deployment, observability). These may benefit from a temporary DevOps team of experienced engineers that drive collaboration on shared practices and tools.
- However, without a clear mission and expiration date, this risks crossing into the anti-pattern of a siloed devops team with specialized knowledge.
- For a large org where devops adoption requires top-to-bottom alignment, makes sense to create a team of devops evangelists that raise awareness and cheer early successes.
- Orgs adopting small batches of delivery may lack mature engineering practices required to keep a sustainable pace over time(e.g., automated testing, deployment, observability). These may benefit from a temporary DevOps team of experienced engineers that drive collaboration on shared practices and tools.
- Org Size, Software Scale, and Engineering Maturity
- Matrix of Maturity(M) vs Size or Scale(S):
- High M / Low S: E2E team ownership with regular collab
- High M / High S: Both E2E and specialized teams focused on reliability
- Low M / High S: Specialized teams relying on a Platform-as-a-Service
- Low M / Low S: Specialized teams with strong collab
- Low-maturity orgs need time to acquire capabilities for E2E teams, so rely on specialized teams that collab closely to minimize wait times and address issues.
- As scale increases, focusing on providing an underlying platform-as-a-service becomes more important to prevent bottlenecks
- At high maturity and discipline, the previously described SRE model may make sense
- Matrix of Maturity(M) vs Size or Scale(S):
- Splitting Responsibilities to Break Silos
- May remove or lessen deps on certain teams by breaking down their set of responsibilities and empowering other teams to take them on e.g., splitting Database dev from Database admin, since database admin often will be held internal to the platform(or delegated to a database-as-a-service offering)
- Dependencies and Wait Times Between Times
- Visualize the dependency matrix that describes the communication needed to make them work well.
- Can split deps into three categories(knowledge, task, and resource deps) to pinpoint inter-team deps and potential constraints to work flow.
- Must track number of deps per area and thresholds for that number that trigger adjustments in team design and deps.
- The DevOps Topologies catalog provides good snapshot advice on effective structure, but needs will change over time, and the topologies must change to match expected changes in org capabilities and constraints.
- Example: DevOps team created, had become a silo
- Created IaC project on cloud provider that automatically installed, configured, and operated an enterprise doc mgmt product.
- "Ops as Infrastructure-as-a-Service": Early ops team involvement in operational code, developers focused on non-functional production requirements, and individuals from the siloed tooling team to help support the infrastructure during the transition.
- Evolve DevOps team into DevOps Evangelism team, working to enable the individual project teams. They automate the dev and ops steps, then look to make dev and ops teams own the automation and execution themselves.
- Setting up new teams as a reaction to scale, adopt new tech, or respond to demands can help in the present but fail to deliver the needed speed and efficiency of intentional topologies. Because these decisions are often made on a team basis, they lack consideration for org constraints(tech and cultural maturity, org size, scale of the software, engineering discipline, inter-team deps, etc), resulting in team structures optimized for temporary problems and unable to adapt to new problems over time.
- DevOps team example: Carving out a DevOps team makes sense to accelerate short-term delivery, but will become a hard dep for all app teams, leaving them little time to help design and build self-service capabilities that app teams can rely on.
- Adopt topologies that work given the slow-changing org context, rather than those that solve a particular problem in the moment.
- Use the DevOps Topologies Catalog as a starting point.
-
Key Take-aways
- The 4 fundamental team topologies simplify modern software interactions
- Mapping common industry team types to the fundamental topologies sets up orgs for success, removing gray areas of ownership and overloaded/underloaded teams.
- The main topology is (biz) stream-aligned; all other topologies support this type.
- The other topologies are enabling, complicated-subsystems, and platform
- The topologies are often "fractal" (self-similar) at large scale: teams of teams
-
The four types should act as "magnets" that teams ought to move toward to reduce ambiguity around roles.
-
Large or mid-sized orgs will likely have one or more of each topology(though complicated-subsytem should be rare)
-
On Ops / Support team: There is deliberately no ops/support team, as the long-lived teams building the systems also operate them, even in the SRE model proposed in Ch. 4, where the team is still closely aligned.
- Stream: A continuous flow of work aligned to a biz domain or org capability.
- Stream-aligned team: A team aligned to a single, valuable stream of work(a product/service; set of features; user journey; user persona; etc) that is empowered to build and deliver customer value as quickly, safely, and independently as possible, without requiring hand-offs to other teams to perform parts of their work.
- This should be the primary team type in the org - Other topologies reduce burden on stream-aligned teams.
- Based on successful org, ratio of s-a teams to other types should be between 6:1 and 9:1
- Close to the customer and able to quickly react to feedback while monitoring their software in production.
- Multiple stream types that coexist in an org: specific customer streams, business-area streams, geography streams, product streams, user-persona streams, compliance streams(if highly regulated), a micro-enterprise with an independent focus and purpose(r&d), etc.
- Stream-aligned teams are funded in a long-term, sustainable manner based on a portfolio or program of work, not a time-bounded project.
- e.g., Amazon forcing teams to be independent
- Mandates:
- Each team is fully responsible for developing and operating its own service
- Each service is provided through an API, either for internal or external consumption. Other teams make do not interfere or make assumptions on other teams' services architecture or technology.
- Teams must be cross-functional with all capabilities needed to manage, specify, design, develop, test, and operate their services(including infra provisioning and support). A single person may provide more than one capability.
- SDETs coordinate more - They work cross-org evangelizing practices and tools; ensure smooth cross-service, cross-device UX.
- Mandates:
- Capabilities within a stream-aligned team(non-exhaustive, and a single person may fulfill more than one capability)
- App security
- Commercial / operational viability analysis
- Design and arch
- Dev and coding
- Infrastructure and operability
- Metrics and monitoring
- Product mgmt and ownership
- Testing and QA
- UX
- On SRE: Special stream-aligned team responsible for the reliability of large-scale apps in Prod. SRE interacts with one or more stream-aligned app dev teams. The flow of change is still stream-aligned.
- Why stream-aligned vs "Product" or "Feature" team?
- Aligning a team's purpose to streams reinforces a focus on unimpeded change flow at the org level.
- Customers' E2E experience has changed: IoT, multiple OSes, feedback via social media, etc. Modern design must incorporate service, feedback, failure, and learning as first-class concepts.
- "Stream" invokes "flow" via water metaphor, keeping focus on flow
- Expected behaviors
- Team aims to produce a steady flow of feature delivery
- Team course-corrects quickly based on feedback
- Team uses an experimental approach to product evolution, constantly learning and adapting
- Team has minimal(preferably zero) hand-offs
- Team is evaluated on sustainable flow of change produced
- Team has time to address code quality / tech debt so that flow of change is maintained
- Team proactively reaches out to supporting topology teams
- Members of team are engaged: feel they have or may achieve autonomy, mastery, and purpose
- Enabling teams: Teams of specialists that support E2E stream-aligned teams that may not be able to research / learn about new skills emerging in all capabilities. Enabling teams research and try out alternatives to make suggestions on tooling, practices, frameworks, etc.
- Must be strongly collaborative: Seek to understand the problems of stream-aligned teams in order to provide effective guidance.
- Must not be ivory towers: They do not dictate choices for other teams, but do help teams understand and comply with org-wide tech constraints. End goal is to increase autonomy of stream-aligned teams by growing their capabilities with a focus on their problems first, not the solutions.
- A successful enabling team should not be needed by stream-aligned teams after a few weeks or months, and should never be a permanent dependency.
- May align to any of the capabilities, but often are focused on specific areas(build engineering, CI/CD, deployments, test automation for a particular client tech, etc).
- Knowledge transfers between enabling and s-a teams may be temporary(e.g., when a s-a team adopts a new tech, like containers) or long-term(e.g., for faster builds or test execution). Pairing may help.
- Expected behaviors
- Proactively seeks to understand the needs of s-a teams, establishing regular checkpoints and jointly agreeing when more collab is needed
- Keeps abreast of new approaches, tooling, practices in their specialization before s-a teams need them if new developments may enable other teams
- Delivers both good(new framework that eliminates toil) and bad(widely-used library needs to be deprecated) news.
- May act as a proxy for external or internal services that are too difficult for s-a teams to use directly.
- Promotes learning both inside the team and in s-a teams, acting as a curator that facilitates appropriate knowledge sharing.
- Case study
- Team forced in response to long feature lead times; coupled release cycles for seperate sysems; low team morale; siloed technical knowledge; org losing ground to competitors as they couldn't innovate rapidly.
- Team composed of specialists from app dev, build/release, testing, etc, both from internal teams and external consultants, with goal of sharing good practices and education, not introducing new tooling.
- Shared a team charter with their goals to enable faster delivery with higher quality in eight weeks using the following metrics:
- Time taken per deployment
- Absolute number of successful deploys per day
- Time taken to fix a failing deploy
- Time from commit to deploy(i.e., cycle team)
- Focused on making themselves redundant - Ran mob sessions, recorded demos, invited teams to showcases. 25% time solutioning, 75% time knowledge sharing.
- 72% decrease in deployment time; 700% increase in deploy pipeline runs; deploy pipeline duration decreased by 98%; failing builds fixed within 23hrs from infinite.
- Success gave the team leverage to go after more wide-reaching changes for other pain points.
- Enabling teams help s-a teams deliver software in a sustainable, responsible way, but are not in place to fix problems that result from poor practices, poor code quality, or poor prioritization. s-a teams should expect enabling to consult for weeks or months to increase their capabilities around a new tech, concept, or approach, and then enabling teams will move on to next team.
- Enabling teams vs Communities of Practice(CoP)
- Both can increase awareness and capabilities of other teams, but enabling does it full-time, while CoP may be a more diffuse set of people that share on a regular cadence.
- Responsible for building and maintaining a part of the system that depends so heavily on specialist knowledge that most team members must be specialists to make changes.
- Goal is to reduce cognitive load on s-a teams that use the subsystem, as those teams can't be expected to each have the expertise in-house.
- Examples: Video processing; statistical modeling; real-time trade reconciliation; face recognition; etc.
- Critical difference between a traditional component team and a c-s team is that the c-s team is created only when the subsystem needs heavy specialist knowledge, driven by the cognitive load of that knowledge, not a perceived opportunity to share functionality. As a result, should be rare.
- Expected Behaviors
- Mindful of the current development stage of the subsystem and acts accordingly: High collab with s-a teams during early exploration and dev phases; reduced interaction, higher focus on interface, feature evolution, and usage when more mature.
- Delivery must be higher with the c-s team than it would be if owned by a s-a team.
- Prioritizes and delivers work respecting the needs of the s-a teams using the subsystem.
- Enable s-a teams to deliver work with autonomy by providing internal services that reduce the cognitive load required for s-a teams to develop these concerns(e.g., build, deploy, etc)
- s-a team maintains full ownership of building, running, and fixing their apps in Production.
- Digital platform: A foundation of self-service APIs, tools, svcs, knowledge, and support which are arranged as a compelling internal product. Autonomous teams can make use of the platform to deliver product features at a higher pace with reduced coordination.
- Platform capabilities best exposed via web portal and/or API rather than just docs. Ease of use is top priority, reflecting that platform teams must treat the services they offer as products that are reliable, usable, and fit for purpose, whether intended for internal or external customers.
- Platform teams are pure service providers for domain teams and their success can be measured by the value of the services they provide to domain teams.
- Should focus on providing a smaller number of services of acceptable quality rather than a large number of services with many resilience and quality problems.
- Must balance practicality vs quality: If s-a teams demand zero-downtime, auto-scaling, and self-recovery, then platform teams may not be able to keep up with demand.
- May want to use internal pricing(e.g., tracking cloud spend by team or service) to determine resilience needs
- May be thick(a platform that wraps several the output of several platform teams) or thin(a platform that wraps a service provider).
- Examples: Server provisioning, networking, access management, etc.
- Expected behaviors
- Collaborates with s-a teams to understand their needs
- Relies on fast prototyping and involves s-a teams for fast feedback on what works and doesn't
- Focuses on usability and reliability of their services and regularly assesses if their services are still useful and usable
- Leads by example, using their services internally(when applicable), partnering with s-a and enabling teams, and consuming lower-level platforms(owned by other platform teams) when possible
- Understands that adoption of new services is not immediate, evolves along a curve
- Case Study
- Evolved org from small number of scrum teams to squads, sub-tribes, and tribes.
- Incorporated DevOps early - First when they needed improvements to builds and releases because they were having trouble delivering, then as a core part of squads, and later into dedicated reliability teams, with ops members embedded in delivery teams.
- Needed to solve configuration management, maintain a DR environment synced to Prod, so created a Platform Evolution team composed of mixed software and infrastructure devs with a top priority of implementing configuration management via Chef.
- Resulting solution was a mass of Chef that was a significant constraint as they grew and engineers began stepping on each other.
- (Continuation from Ch. 8)
- Choice: Dissolve team and make each of the relatively large product teams for their own configuration mgmt, or determine how enable them to accelerate delivery with high quality and reliability
- Evolve Platform Evo -> Platform Services, a product team with services and support capabilities i.e., focus on value-delivering features to be consumed by other teams, prioritizing features according to customer needs.
- Alongside breaking down the Chef monolith, developer value-add services to teams: AWS integrations, build and test envs, logging platforms, etc. In each case, turned a fundamental team capability need into a more usable managed service equivalent.
- Boundary of responsibility was a point of contention, particularly between infra team and Platform Services: PS building firewall, load balancer automation, AWS tooling, secrets management, but struggling with the boundary between it and infra. Eventually, had to ask whether infra was organized in a way to support products. Infra was the last remaining team with a clear delivery/ops split, so reorganized around products and services: smaller teams owning E2E lifecycle of a coherent set of related things, with mandate to make them better for customers; PS merged as part of the Infra function: Load balancer and firewall automation -> networking-related infra squads, other services remained within two new PS squads, Platform Engineering and Delivery Engineering. Automation engineers seeded into infra squads that had poor automation expertise to develop an infra product function that supported those teams' engagement with wider biz.
- Finally, have infra-platform feature teams, just as customer-product teams, with much better engagement and delineation of responsibilities.
- Compose the Platform from Groups of Other Fundamental Teams
- Large orgs may need more than one team to build and run their platforms, and some orgs may need separate platforms for different streams.
- The Platform should be composed of groups of other fundamental topologies(s-a, enabling, c-s, and platform), but they align to different streams than the revenue-generating / customer-facing products and services. Streams relate to services and products within Platform(e.g., logging and monitoring, test environment creation, resource visibility, etc). From the Product Owner's view, there are clear internal streams of value within the platform to which the s-a teams align to help them deliver value to customers of the platform(i.e., the teams that use the platform).
- Result is nested or "fractal" teams within the platform: s-a, c-s teams supporting an internal platform team.
- Dev teams should see the resulting Platform team as a single entity that provides them a service they consume via an API; however, within the platform team there are distinct teams aligned to e.g., network, environments, metrics that collaborate with or provide services to other platform teams.
- Case study
- Org moved from print-based to digital sales, had two separate offices, and used BDUF for tech work, in which devs would leave projects on the day they went live, destroying continuity.
- New dev was financed with CapEx but IT/Ops treated as OpEx: Dev was booked 90% to CapEx, so they had to build new things and align around product management rather than users of their services.
- Moved everybody to OpEx(i.e., everybody doing work needed to make the company money, which can include UX, etc).
- Moved to long-lived cross-functional squads organized around E2E customer journeys.
- Created CI/CD team to help other teams in adopting CD(automated deployments, test automation, observability, etc).
- Within 3 months, fully automated first app, then started on the next. As they enabled more teams, realized there was an opportunity for a platform, refocused on that.
- Evolved team is tasked with building a platform that abstracts the pain away from dev teams, allowing them to take full control(including operational) of their products.
- Several different squads, some focused on new products/features(e.g., adoption of TDD, retros, etc); others focused on day-to-day ops engineering needs(in-depth analysis of live service problems). Focus in on the flow of work for dev teams.
- Never embedded ops people in dev squads - Instead, have ops "Squad Buddies" for each dev squad that attends their standups and provides a link between the platform and dev squads.
- Single-capability expertise teams(QA, DBA, UX, etc) should be avoided to ship quickly, as they introduce bottlenecks via handoffs. Instead, combine s-a teams that support and operate software with platform teams that provide the underlying substrate for s-a teams.
- When a silo is required, a c-s team is formed, but that team provides services to s-a teams and never impedes the flow of change
- x-func teams drive simpler, user-friendly solutions because they are composed of people with various skillsets.
- Care must be taken to ensure that the platform serves the needs of consuming apps and services, not vice-versa
- A good platform provides standards, templates, APIs, and best practices that allow teams to innovate rapidly and safely in the right way for the org
- Thinnest Viable Platform
- Simplest platform: Wiki of underlying components used by consuming software. If all components are perfectly stable and well-understood, then no need for a platform team.
- Platform team should aim to be as thin as possible and not drive the discourse, as the natural tendency will be to build a thicker platform.
- Cognitive Load Reduction and Accelerated Product Dev
- Cognitive load reduction is a primary goal - .net, azure, aws, k8s: all reduce the cognitive load teams take on while exposing enough functionality for teams to build on them.
- Compelling, Consistent, Well-Chosen Constraints
- To avoid the trap of building a platform disconnected from team needs, must ensure that platform teams are focused on UX and DevEx. As the platform grows in size, the platform team will need UX capabilities.
- There must be a way for dev teams to provide feedback about the success and frustrates with the platform to prevent isolation.
- Good UX/DevEx must drive a consistent feel for the APIs and features, with comprehensive but brief how-to guides and docs that focus on specific tasks rather than documenting every edge case.
- Can test UX during onboarding of a new dev to the platform.
- The platform must attempt to get out of the way of dev teams, enabling them to build what they need with few pre-conceptions about how they need to do it.
- Built on an Underlying Platform
- Every app or service is built on some platform(.net, aws, etc), even if the underlying platform is hidden. If the underlying platform is unstable or ill-defined, then the platform built on it will be unstable and unable to accelerate the org. Operational quirks and perf problems must be abstracted away and worked around for dev ease of use - at a minimum, well-documented to dev teams so they can avoid issues.
- Manage as a Live Product or Service
- Users(dev teams) will rely on the stability of the platform and will need to know when new features will come and old ones will be retired, so the platform must be treated as a live/production-grade system, with managed downtime, and appropriate product management(roadmap influenced by dev teams, personas, etc).
- Incident response, downtime, on-call, status pages, observability, all must be considered as the platform represents a critical product for dev teams
- As the platform grows, may reconsider what is most needed from teams and what can be provided externally, reducing the need to hire endlessly.
- Evolution of the platform product is not only driven by feature requests from dev teams, but curated and shaped to meet long-term needs. Feature usage should be tracked to drive prioritization.
- As a product, the platform must not be a collection of features, but a consistent thing that accounts for the direction of technology change in the industry and the changing needs of the org. Should also serve to reduce the need for security and audit teams to interact with dev teams.
- Many orgs will benefit from better clarity around the purpose of their teams(e.g., by deciding which topology a team ought to use, and change the team to fit that topology)
- Move to mostly stream-aligned teams for longevity and flexibility: Most teams should be long-lived, x-func, s-a, that take ownership of discrete slices of functionality or user outcomes, and build relationships with biz reps and other s-a teams. s-a teams shopuld expect to have cognitive load matched to their capabilities through support from enabling, platform, and c-s teams.
- Infrastructure teams to Platform teams: Difficult because infra teams may not be familiar with product needs, but necessary
- Component teams to Platform or other types: Component teams may be dissolved, with the work going into s-a teams, or converted into another team type(platform if it's a lower-level platform component; enabling if it's easy enough for s-a teams to work with; or c-s if it's too complicated for s-a teams to take on in full). Team should adopt behaviors of whichever type they migrate to.
- e.g., DBA teams may be converted to enabling teams if they stop doing app work and focus on evangelizing database perf, monitoring, etc into the s-a teams. May be converted to platform(handling perf, config, availability, etc), but then shouldn't be responsible for schema changes or app-level database concerns.
- e.g., "middleware" teams -> platform teams if they make those parts of the system easier to use, reduce cognitive load for s-a teams by customizing, simplifying, or wrapping the middleware into easy-to-use self-serve services aligned to org goals.
- Tooling teams to enabling teams or platform: Easy for tooling teams to turn into silos, better to run them as either short-lived, well-scoped enabling teams or as part of platform, with a clear roadmap.
- Support teams: Must align to stream of changes and must operate cross-team to resolve live service incidents. If the teams are needed, align them to stream of change alongside s-a teams. They will evangelize greater awareness of the UX for the whole servic(e.g., by introducing synthetic transaction monitoring). At incident time, support teams attempt to resolve without assistance; if needed, other same-stream s-a teams are brought in; finally, other streams' teams are brought in via an "incident squad" of support specialists composed of members of the various support teams.
- Keeping support teams stream-aligned helps keep streams independent by incentivizing independent design at runtime, instead of treating production as a monolith env supported by a single team
- Knowledge of new limitations and flaws is rapidly shared to other streams to be incorporated into their designs
- Converting Arch and Architects: Part-time enabling team if needed at all. Part-time emphasizes that many decisions should be left to implementing teams. Arch should work to support other teams and make them as effective as possible, rather than imposing design choices on teams. Archs must collab with their users - s-a devs - to deliver useful outcomes. Effective cross-team API design and watching out for unwanted interactions(per Conway) are key focus.
- Many orgs start with a number of teams with poorly defined responsibilities. Recasting these to the 4 fundamental types puts the focus back on team interaction patterns that promote flow of change at both the personal and org level.
- Majority of teams should be s-a, loosely coupled, and capable of delivering useful increments of their products / services / user journeys
- s-a teams are helped by enabling(identify impediments and cross-team challenges, simply adoption of new approaches), c-s(bring deep specialist expertise to system parts), and platform(provide the platform on which s-a teams can build and support software with minimal friction)
- The platform itself must be run as a product with a roadmap, regular interactions with users(s-a teams), focus on UX/DevEx. Platform itself may be composed of internal s-a teams, enabling teams, etc, using the same norms as specified in their topologies.
-
Key Take-aways
- Choose software boundaries using team-first approach
- Beware of hidden monoliths and coupling in the software delivery chain
- Use software boundaries defined by the business-domain bounded contexts
- Consider alternative boundaries when necessary and suitable
-
Hand-offs slow delivery, so eliminating them by establishing the right boundaries is key. Software and system boundaries must be aligned to the capabilities of a single team.
- Tightly coupled modules with unclear boundaries hamper autonomy.
- Bounded contexts and APIs can help decouple domains into smaller units with clear owners.
- When migrating from monolith to loosely coupled, must consider how it will affect the teams - Their cognitive capacity, location, and interest in the new services. Ignoring this aspect risks splitting the monolith in the wrong places(i.e., distributed monolith).
Hidden Monoliths and Coupling
- Application Monolith: A single, large application with many deps and responsibilities that exposes many services and user journeys. Often deployed as a unit.
- Joined-at-the-Database: Several apps/scvs coupled to the same db schema, complicating changes, tests, and independent deploys.
- Monolithic Builds(Rebuild everything): Uses a gigantic CI build to produce a new version of a component.
- Monolithic Releases(Coupled Releases): Many small components bundled into a single "release" for deployment, so can only be tested together.
- Monolithic Model(Single view of the world): Forces a single domain language and representation across many contexts. May impose arch constraints as the org reaches more than a handful of teams or domains.
- Monolithic Thinking(Standardization): One-size-fits-all thinking that leads to unnecessary restrictions on tech and implementation approaches. Standardizing simplifies oversight/management but beats down high performing engineers' desire to try new techniques and techs, and removes their ability to use the right tools for the job.
- Monolithic Workspace(Open Office): Single open office layout for all teams in the same geo. Emphasizes colocation of bodies over colocation of purpose.
- Splitting a monolith brings dangers: Less consistency between different software parts, inconsistent UX, accidental data duplication, etc.
- Fracture plane: A natural software seam that allows a system to be easily split into two or more parts.
- Bounded Context: A unit for partitioning a larger domain/system model into smaller parts, each represetning an internally consistent biz domain.
- Best to try to align software boundaries to different biz domain areas - A monolith powering multiple domains affects prioritization, flow of work, and UX.
- Other fracture planes:
- Business Domain Bounded Context(DDD)
- Most planes should map to biz-domain bounded contexts.
- Domain models act as a shared language to help devs communicate with domain experts. They also act as a foundation for the design of the software - how it's broken into objects or functions. The model must be unified(internally consistent) so that there are no contradictions within it.
- e.g., for a music streaming service, three subdomains: media discovery(finding new music); media delivery(streaming to listeners); licensing(rights management, royalties, etc)
- Identifying contexts requires both biz knowledge and tech expertise, so may make initial mistakes, but should adapt over time even if that means service redesign. Over time, simple, atomic-seeming contexts may expose fracture planes.
- DDD also brings better focus to core complexity and opportunities within a context for a given domain; explores models via collab between biz experts as domains decrease in size; modules that better express the resulting domains; and a ubiquitous language for biz and eng inside a bounded context, reducing translation issues between biz and eng.
- Regulatory Compliance
- Regulation brings reqs for auditing, docs, testing, and deploying.
- Tempting to standardize process across all software, inside or outside regulation, but forcing it on all subsystems isn't advised. e.g., PCI should fall to a dedicated subsystem that follows strict rules, so the surrounding monolith doesn't have to.
- Breaking regulation into its own subsystems also allows compliance/legal teams to better focus on the areas of change split off, rather than the system as a whole.
- Change Cadence
- Monolith moves at the speed of its slowest part. e.g., if new reporting features are needed quarterly, shipping more often may be difficult as the code in that module won't be ready.
- Team Location
- By physical location(e.g., different floors or regions)
- Aligning time zones allows for better intra-team comms(e.g., no PR approval bottlenecks, question bottlenecks).
- Hybrid comm(part in-office, part remote) doesn't work well. Instead, split subsystems appropriately to leverage Conway's law(the natural flow of communication).
- Risk
- Risk: The probability of system or outcome failure
- Compliance risk(addressed earlier); marketing-driven changes with a high risk profile(focus on customer acquisition) vs lower-risk changes to revenue-generating transactional features(focus on retention)
- Usage risk - Changes to highly used features(e.g., in a free vs paid tier) touches more users than changes to paid-only features, especially if you have a closer relationship with those users(e.g., internal systems).
- Splitting by subsystem risk profile allows matching changes to biz appetite / regulatory needs, and allows each subsystem to evolve its risk profile over time(e.g., adopting CI/CD to increase speed of change without more risk)
- Performance Isolation
- Subsystems subject to peak demand spikes require a level of scaling / failover optimization not needed for low-usage systems.
- Splitting perf-sensitive subsystems ensures they can scale autonomously(e.g., tax system: submission and validation could be split as they will get hit hardest and need to respond during tax season; simulation, processing, and payment may have more even profiles)
- Technology
- The most common split(e.g., front vs back end, data tier, etc), but also one that often introduces constraints and bottlenecks
- Appropriate for systems integrating older or less automatable technology, where manual tests, implementation difficulties, and lack of tooling are the norm
- Before choosing this plane, investigate whether other approaches could increase the pace of change in older tech, removing constraints and allowing better plane splits, like bounded contexts.
- User Personas
- Different users will rely on different subsystems / features - Paid tiers vs free, admin vs regular, etc.
- Harder to decouple these subsystems, but allows for sharper focus on customer needs and experience => higher csat, simpler customer support.
- Natural Planes for the Specific Org or Tech
- Litmus test: Does the resulting arch support more autonomous teams with reduced cognitive load?
- May take experimentation, but a simple heuristic is "Could a team effectively consume or provide this subsystem as a service?" If so, may be a candidate for splitting and assignment.
- Case Study
- Company tripled in size, opened international office, landed high-profile brands.
- Used by moer than 15MM employees in 100 countries.
- Scaled in 3 years from a single dev team to eight product etams, one SRE team, and an infra team
- Needed to split the monolith, as they weren't able to scale single-team arch and practices to more engineers.
- Used DevOps/CD as the core for design choices and transitioned to microservices
- Focus on the team as the unit of delivery - Eliminated bottlenecks on individuals(by pairing, mobbing, etc); Instrumented and added telemetry to enable visibility in production; improved E2E deployment pipeline. Together, allowed teams to take ownership.
- Products help orgs communicate electronically with large number of people, so biz domains are concepts like people, content, events, email, mobile, analytics. Spent time assessing how independent each domain really was and whiteboarding scenarios before splitting software along those boundaries to minimize Conway.
- Enabled collab via "matrix product teams", x-func teams sitting together who completely own a product area. Generally 4 devs, one production mgr, one QA, one UX/UI designer. Teams speak directly to customers and stakeholders - shadow support calls; design, build, measure solution impact; accountable for the quality of solutions.
- Use event storming to model the domains
- Pact to standardize approach for contract testing services and inter-team comms.
- Delivery teams aligned to biz domain contexts(e.g., email, calendar, people, surveys, etc). Some align to regulatory boundaries(e.g., ISO-27001). Separate team that ensures consistent UX across all software, acting as internal consultants to delivery teams. Separate SRE capability for high traffic volume and enhancing operability.
- Example: Manufacturing
- Tech ought to be a rare fracture plane, but useful sometimes
- Large mfr of physical devices with IoT capabilities, controlled both via cloud schedules and mobile app
- s-a team would struggle to own this E2E - Mobile app, cloud processing, embedded, with different tech stacks and requirements
- Instead, organize along those tech boundaries: Mobile, cloud, embedded to give each their own cadence
- Could do the following, but in either case the new team would need to operate as a platform team; and coordination will be needed for features that impact multiple areas(this coordination should drive norms of working). If rate of change is different than expected, may need to restructure boundaries.
- Treat cloud software as the platform, called by mobile and embedded: Works well if rate or ease of change of consuming apps is at least as rapid as rate of changes in cloud platform
- Treat embedded as the platform, called by cloud and mobile apps
- Business Domain Bounded Context(DDD)
- s-a teams should be responsible for a single domain, hard when domains are hidden inside monoliths that contain many responsibilities and were designed along tech boundaries
- Fracture planes are natural ways to break apart a system that emphasize team autonomy and delivery
- Aligning subsystem boundaries with mostly independent biz segments is a good starting point, incorporating DDD, but need to keep an eye out for other planes(change cadence, risk, compliance) that may be needed
- Many types of monoliths that impede flow and increase inter-team dependency
- Planes can also be chosen around specific challenges(technology, regulation, performance, geolocation) to help avoid hand-offs
- In all cases, segments must be sized such that teams can own and evolve their software in a sustainable way
-
Key take-aways
- Choose specific team interaction modes to enhance delivery
- Choose between three modes - collaboration, x-as-a-service, and facilitating - to help teams provide and evolve services to other teams
- Collab can be a powerful driver for innovation but can reduce flow
-
Topologies won't be static - Must plan for evolution of team patterns to meet emerging needs(technological, biz landscape, org size, etc). Topologies used should adapt to emerging challenges while retaining focus on team and arch considerations(e.g., Conway)
-
Team interaction modes simplify and clarify the essential interactions between teams, defining expectations and behavior patterns for all teams. Well-defined interaction patterns clarify ambiguity and drive more coherent boundaries and APIs.
- Poorly defined interactions and responsibilities cause friction: Team told it's autonomous, self-organizing, but requires multi-team coordination in reality; team has responsiblity to provide an api/service but doesn't have the experience to do it effectively; etc.
- Teams must generally choose between collaborating with another team or treating them as a service provider. May be decided at many levels(e.g., consuming infra-as-a-service via AWS/GCP/Azure, collaborating on logging/metrics, relying on c-s team that specializes in audio codec, collaborating on app deployment).
- Avoid the need for all teams to communicate with all other teams to achieve their goal.
- Collaboration: working closely with another team. Drives innovation and discovery but blurs boundaries.
- Suitable when a high degree of adaptability or discovery is needed(e.g., when exploring new tech or techniques)
- Good for rapid discovery of new things, as there are no hand-offs between teams(e.g., if expertise spans two existing teams in an emerging tech area)
- Natural fit for early phases of new systems; and periods where there is a need for discover new info, tech limitations, and practices.
- Should collab with at most one team at a time.
- Collab => new insights => learning distributed back to other teams.
- 2 visualizations
- Two teams with distinct expertise working together on a small set of things, where the two substantially retain their responsibility and expertise for their area of focus and work on a subset of activities.
- Two teams merge, pool expertise, and share tasks.
- In either case, two teams take joint responsibility for outcome
- Cognitive load of collaboration can be higher than working inside a team's natural boundaries, with increased communication overhead, and possibly perceived short-term reduction in effectiveness. Thus, when teams collab, should be a high value from the collab with a tangible reward, and as little friction as possible.
- Collab model will also drive blurring of arch via Conway - If well-defined boundaries are a goal, then extended collab may not help, as a need for ongoing collab implies incorrect boundaries / responsibilities or skillsets.
- x-as-a-service: consuming or providing something with minimal interaction. Clear responsibilities with predictable delivery but needs good product management.
- Suited where one or more teams need to use a library, component, api, or platform that "just works", and the thing can be abstracted away.
- Appropriate for later phases of system dev and periods where predictable delivery is needed(vs discovery of new approaches). Appropriate when there is high value in abstracting away low-level details of a capability.
- Challenges of the service will already have been discovered by a previous exercise using close collab, producing an effective solution to run as a service that facilitates faster delivery for consumers.
- Clear ownership / boundaries: Consumer vs creator. Little collab.
- Responsibility of the service must make sense in biz domain context / tech domain, and team must understand the needs of its consumers and managing a service(e.g., versioning).
- DevEx must be compelling: Easy to use, test, deploy, debug, with good docs. Feature requests are curated based on needs of all teams, not a single request.
- Expect slower innovation due to lower collab; reduced flow if boundary is poorly chosen.
- Facilitating: helping or being helped by anotehr team to clear impediments. Senses and reduces capability gaps.
- Suitable when one or more teams benefit from help/coaching in some aspect.
- Main operating mode of the enabling team. Goal is to enable the other team to be more effective, learn more quickly, understand new tech better, discover / remove common problems / impediments, discover gaps or inconsistencies in existing components and services.
- Doesn't build the main software systems / supporting components / platform, but focuses on the quality of interactions between those teams(e.g., if a logging service is hard to configure, facilitating team may facilitate improvements to that service). Because facilitating team's boundaries are clear - No building - no question of ownership.
- Some combo of these likely needed for most medium+ orgs, and one team may use more than one interaction mode based on different teams with which it communicates.
- e.g., an s-a team working on personal finance software may use collaboration when interacting with the team on cloud-monitoring tooling, but use x-as-a-service when interacting with the team that provides the platform.
- Formalizing the way teams should interact clarifies inter-team APIs, both in communication and in software systems(Conway).
- Interaction modes become team habits, clarifying team purpose and reducing frustration, and keeps the question top-of-mind: "What kind of interaction should we have with this other team? Should we collaborate closely, expect them to provide a service / provide them a service, or expect them to facilitate / facilitate them?"
- Different interaction styles/behaviors may be needed when interacting with different teams
- Tip: Construct inter-team relationships ni terms of promises rather than in terms of commands or contracts(e.g., semver promises when something may break the consumer)
- Collaboration Behaviors: High Interaction and Mutual Respect
- Activities will take longer as they cross boundaries to solve previously unknown problems
- May train/coach teams in pairing, mobbing, whiteboarding, and general collab to maximize effectiveness
- x-as-a-service Behaviors: Emphasize the Team UX
- If a platform team is providing provisioning for an s-a team, both should emphasize usability: how the API feels, how easy it is to see resource usage, how compelling features are, etc.
- May train teams in UX and DevEx practices to prep them to get this right
- Facilitating Behaviors: Help and Be Helped
- Customers of facilitating teams ned to be open to being helped by those teams, including open to new approaches
- May train in how to facilitate or accept facilitation
- Typically:
| Collaboration | x-as-a-Service | Facilitating | |
|---|---|---|---|
| s-a | Typical | Typical | Occasional |
| Enabling | Occasional | Typical | |
| c-s | Occasional | Typical | |
| Platform | Occasional | Typical |
- e.g., s-a teams can generally expect to interact using either collab or x-as-a-service, but Platform mostly uses x-as-a-service
- Desired team interactions can drive org design most likely to produce the arch we want
- Case Study
- Joined IBM during cloud transition to bring nascent devops practices to 40k devs
- Created a DevOps Advocates team, some full-time, some part-time, to aggregate successful patterns for encouraging and educating others
- Team created training for teams and execs, with a goal to put themselves out of biz, not survive as a long-running team
- Use the Reverse Conway Maneuver with Collab and Facilitating Interactions
- Reverse Conway allows org to anticipate Conway results and arch around them, but initially there will be natural pushback against the reformed teams. To help transition, use temporary but explicit collab modes between teams building software and one or more enabling teams acting in a facilitating mode. Explicitly driving temporary collab and facilitation for the s-a and c-s teams, problems with the new boundaries can be quickly identified and design can be adjusted.
- Team responsibilities during collab phase may need to be back-to-front e.g., if a monolith needs splitting into segments, teams that "logically" own a high-level component may need to work on the lower-level platform for some time in order to make the split(especially if they're the authors). Gradually, responsibility can be passed to the new lower-level owners.
- Discover logical APIs between teams by Deliberate Evolution of Team Topologies
- A dedicated arch team is generally an anti-pattern, but a small group of architects can be effective at discovering, adjusting, and reshaping team interactions(thus, the system architecture, via Conway). These archs need both tech and social skills and need to be involved in biz strategy, org structure, personnel issues, etc. Archs continuously ask "Which team interaction modes are appropriate for these teams? What kind of communication do we need between these system parts?" As a result, these archs drive API design between teams.
- Use the Collaboration Mode to Discover Viable x-as-a-Service Interactions
- x-as-a-service optimizes for flow, but needs clear boundaries and scope to meet consuming teams' needs.
- Collab mode helps redraw service boundaries, either expanding or contracting, to better fit consumer needs.
- Ongoing lightweight collab at boundaries should be expected to ensure that services are most effective - just enough collab to determine appropriate ongoing scope
- If trying to make a new x-as-a-service interaction, same deal: collab to establish boundaries and continue to validate ongoing. Should collab until the interfaces are proven stable and functional.
- Collab mode can drive more innovation of both application and platform/infra, helpful for new products or service offerings
- Experience and Empathy
- If current interaction mode has been in place for a while, changing it temporarily may refresh the team, grow their experience, and increase empathy
- May swap pairs with other teams or moonlight on another team for a feature
- Changes must be deliberate and temporary with enthusiasm from participants
- Use awkwardness in team interactions to sense missing capabilities and misplaced boundaries
- e.g., a s-a team that should be consuming x-as-a-service from a c-s team, but they're spending significant time talking to that team trying to use it. We know that the service should be low-friction, so: is the boundary in the right place, is the component api well-spec
- e.g., Platform team expects to collab closely with s-a team to assess a new tech but is getting little interaction from the team. So: Do they understand the value of collaborating at this point? Do they have the skills to understand the collab or is a different team better suited? Is the boundary being bridged too ambiguous?
- Can use DDD techniques(Event storming, context mapping) to drive boundary awareness
- Orgs that don't design good team interactions(not just boundaries, but interactions) drive confusion, annoyance, and ineffectiveness
- The three interaction modes combined with well-defined team types avoid ambiguity and conflict
-
Key take-aways
- Use different topologies simultaneously for strategic advantage
- Change topologies and interactions to accelerate adoption of new approaches
- Differentiate between explore, exploit, sustain, retire phases using topologies
- Expect multiple, simultaneous topologies to meet different needs
- Recognize triggers for org change
- Treat operations as high-fidelity sensory input for self-steering
-
Modern orgs must be able to respond to change, so the most important part of design isn't the org shape but the rules and heuristics used adapt the org as new challenges arise. Need to design the rules, not just the org.
- Primary interaction modes are Collaboration(rapid discovery, few hand-offs, higher cognitive load) and x-as-a-Service(lower cognitive load, more predictable delivery, slower discovery because the API is established and limits interaction possibilities).
- Collaboration is expensive - Monitor ongoing collab to ensure it remains justified due to valuable discovery, capability building, or deficiency-filling.
- Decide how much collab is appropriate: If Team A should consume a service from Team B but cannot, determine whether they should collab for a short time(weeks or months?) to better define the API; determine what exactly the team should collab on, acknowledging that the collab will tend to blur the system boundaries of each team.
- Case Study: k8s adoption to drive org change: After years of increasing complexity, realized that dev teams had to understand too much of the underlying tech stack. Decided on platform abstraction to reduce cognitive load, adopted k8s - "We didn't change our org because we wanted to use k8s; we used k8s because we wanted to change our org." Deliberately using a change in team interaction to drive beneficial change in delivery capability = strong, strategic tech leadership.
- Deliberately changing interaction mode of two teams to collab can enable rapid learning and adoption(e.g., a team with test automation expertise helping a team with less for a few months can build the capability of the second team and better define the API between the two teams). Particularly useful when two groups have very different prior experience around their respective tech.
- e.g., Team adept with cloud-based services building cloud-hosted metric collection and analytics software receiving data from embedded IoT systems => collab with a team of embedded specialists to help both understand challenges: Team A likely treats test envs as ephemeral, and can bring that to Team B; Team B can help team A understand processing/memory restrictions of embedded devices. Also helps org determine whether the embedded devices should be treated as a platform, and the embedded device team treated as a platform team; or whether the teams continue to collab(perhaps with an enabling/facilitating team), maybe eventually realizing their change cadences are aligning and split into two stream-aligned teams.
- Case Study: Evolution of Team Topologies
- Dev and Ops were completely separated with a large gap.
- Instead of using one evangelism team to bridge, used two due to gap size: System-Build(SB) team on the Dev side, Platform Build(PB) team on the Ops side, with close collab between the two - Simpler than getting all of Dev and all of Ops to collab.
- Drew out expected timelines: Initially, Dev -> SB <-> PB <- Ops. In 6+ months(reality: 2 years), Dev -> SB+PB(close collab) <- Ops. In 12+ months(reality: 4 years), SB and PB remain separate teams but are absorbed into Dev and Ops groups(reality: SB merged back into Dev, Ops becomes PB and absorbs that team).
- i.e., at beginning, expected focus on awareness and operability within dev teams, so SB team expected to collab closely with both Devs and PB. Drove improvements in deployment automation, metrics, logging, other operational aspects.
- Initially expected to evolve SB and PB teams into enabling teams in 12 months, but took 4 years in practice. Result in safer, more regular prod changes, fewer deploy mistakes, better change traceability.
- At 4 year mark, SB team was merged back into Dev teams, PB merged back into Ops teams, bringing higher operational awareness and accountability to Dev, leaving Ops to manage the underlying platform(on top of Azure).
- Interaction modes should be expected to change regularly depending on team goals: Exploration of another team's domain -> Collab; Increased delivery predictability following successful discovery -> x-as-a-Service. i.e., Close collab during Discovery -> Moderate collab, tightening API defn during Establish -> x-as-a-service.
- Conway reminds us that during the collab phase, boundaries / responsibilities will be blurred, so must ensure API defn as the teams move from collab to x-as-a-service.
- In large org, multiple discovery activities at a time, with teams taking advantage of well-defined APIs to consume things as a service, e.g.,
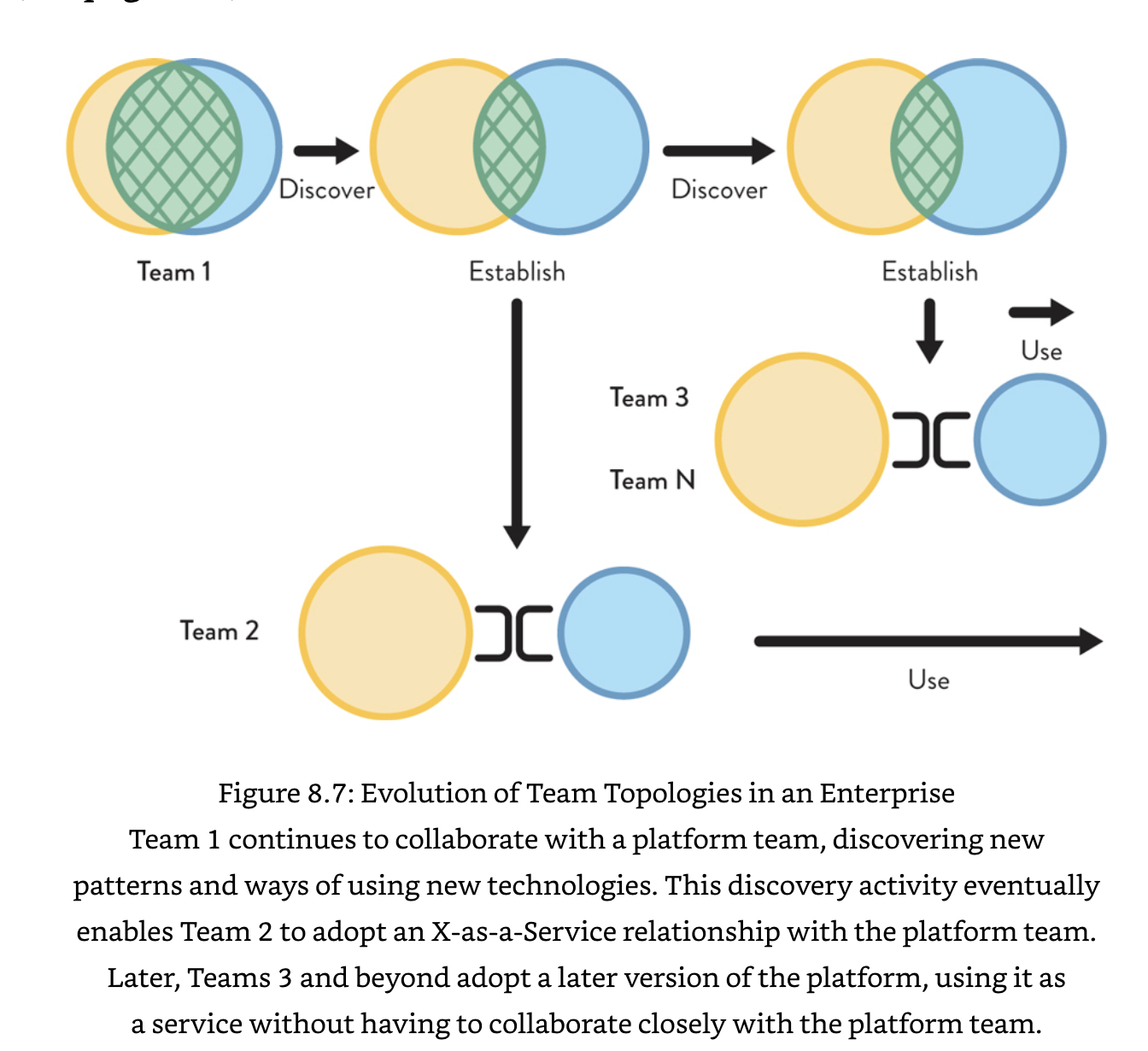
- In some orgs, teams may collab permanently with many teams if rate of innovation is very high; while in others, well-defined problem space and need for execution will tend toward x-as-a-service.
- Orgs should aim to move from discovery to predictable delivery over time as new commodity services / platforms become available. Orgs embrace that different teams will have different experiences based on the kind of work they're doing at a point in time; and that different topologies and interactions for different parts of the org will need to evolve based on their goals and work. Org must ask itself, "Are we trying to discover things and how rapidly do we need to discover them?" At times, may want to colo teams to enhance collaboration; at others, separating them to help enforce an API boundary.
- Topologies change slowly over several months, not weekly. Interaction mode change is encouraged over a few months, with a corresponding change in system arch.
- Case Study: Platform feature teams(Continues Ch. 5 example)
- Content moved to Ch. 5 example
- Many different interaction modes and topologies within the org at any time. Some collab is generally expected, but collab doesn't scale as well as x-as-a-service across many teams.
- e.g., 4 s-a teams building different parts of the system. One may be in collab with Platform team to discover new logging needs, while the other three consume Platform as a service(perhaps with an enabling team facilitating the interactions). So, s-a team has a facilitating interaction with enabling team; collab with Platform team; other s-a teams have x-as-a-service. Explicit interaction modes turn friction into problem signals.
- "Easy" to map structure to topologies at a static point in time, hard to detect when evolution is needed.
- Triggers
- Software has grown too large for one team
- Symptoms
- A startup growing above Dunbar's number(15)
- Teams spending lots of wait time on a single team
- Changes to certain components or workflows routinely routed to the same people, even if busy or away
- Team members complain about lack of system documentation
- Context
- Software will generally grow beyond the ability for everybody to understand every part, leading to often unspoken specialization within the team which optimizes for delivery in time but may obstruct overall flow of work.
- Team may not have the self-awareness to realize the system has become too large, as the limit is based on cognitive capacity to handle changes rather than hard numbers.
- Symptoms
- Delivery cadence slowing
- Symptoms
- Team members qualitatively feel it takes longer to release than it used to
- Velocity or throughput metrics show downward variation vs one year ago(acknowledging any accidental variation)
- Team members complain that the delivery process used to be simpler, with fewer steps
- WIP is increasing, with many changes waiting for another team's input
- Context
- Given autonomy over the entire lifecycle, long-lived, high-performing product teams should steadily improve their delivery cadence as they work more efficiently together(i.e., no hard dependencies on external teams).
- Instead, common to see reduced autonomy by introducing new hard deps between teams e.g., Creating a QA team to centralize all testing
- Tech debt may have accrued to a point where even small changes are costly and cause regressions.
- Symptoms
- Multiple biz services rely on a large set of underlying services
- Symptoms
- s-a teams have limited visibility of E2E flow within their service area
- Difficult to achieve rapid flow of change due to number and complexity of subsystem integrations
- Attempts to reuse an existing set of services becomres more challenging
- Context
- High regulation may drive a large set of underlying services/apis(e.g., insurance company may need lengthy physical checks on factory machinery to update a quote, or bank may need to proof-of-address documents before new account). The lower-level systems provide specialist payment mechanisms, data cleansing, id verification, etc, each of which needs multiple teams to evolve and sustain the service. Alleviated by business process management(and maybe machine learning), but teams will still need to configure workflows of those tools.
- Since high-level services must user lower-level, if they integrate with each separately then it can be challenging to assess flow effectiveness and to diagnose errors in long-running processes that may have human input(e.g., the underlying services may each have a separate way of tracking transactions).
- Must
- Platformize the lower-level services and APIs with a thin wrapper that provides consistent DevEx for s-a teams(e.g., consistent correlation ids, logging timestamps, request/response logging, health-check endpoints, test harnesses, SLOs, diagnostic APIs).
- Use s-a teams for each high-level service responsible for telemetry and fault diagnosis, building "just enough" telemetry integration and diagnostic capabilities to detect where problems occur. Expose metrics, logging, dashboard for the wrapper.
- Wrapper must focus on DevEx - consistency in logging, metrics, correlation ids, etc - for better traceability.
-
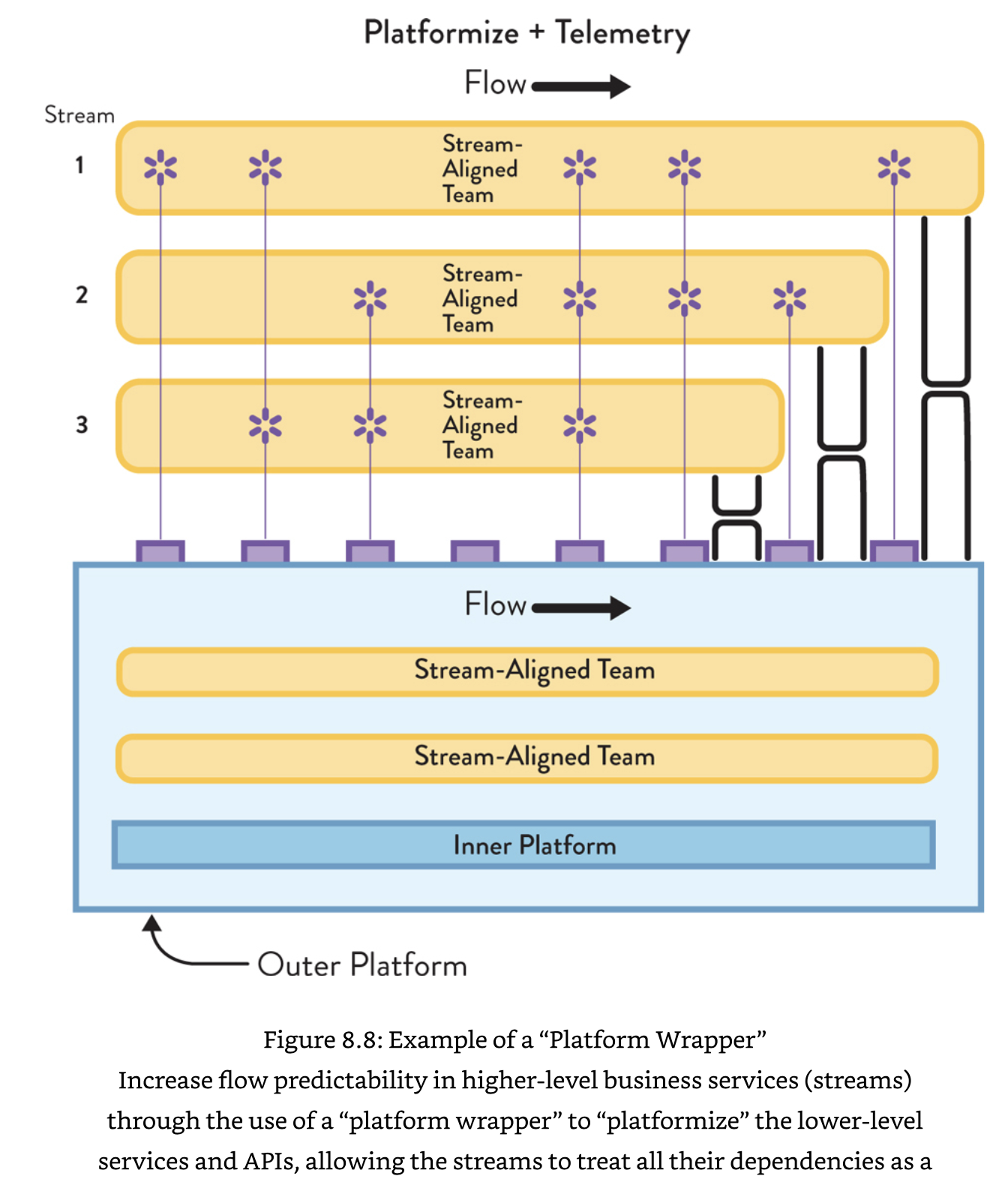
- Symptoms
- Software has grown too large for one team
- Dev and operation aren't separate: Software operation provides signals to dev activities
- Treat teams and team interactions as senses and signals
- Well-defined, stable teams with clear ownership enable orgs to sense their environmental situation
- As opposed to orgs with ill-defined teams that rely on key individuals and suppress many voices, leaving them senseless
- Teams will detect different signals based on what they do, how close they are to internal/external customers, etc, but each will provide sensory input to the org and be capable of responding to info by adjusting their interactions.
- What to sense?
- Have we misunderstood how users need/want to behave?
- Do we need to change team interaction modes to enhance how the org is working?
- Should we still build x in-house, or should we rent it from a provider?
- Is close collab between two teams still effective, or should we move to x-as-a-service?
- Is Team C's flow of work still smooth? What hampers them?
- Does the platform for teams A,B,C provide everything they need? Is an enabling team needed for some period of time?
- Are the inter-team promises between teams A and B still valid and achievable? What needs to change to make the promise more realistic?
- Well-defined, stable teams with clear ownership enable orgs to sense their environmental situation
- IT Ops as high-value sensor input to development
- Signals from maintenance work act as input to software dev activities.
- 3 ways of devops
- Systems thinking: optimize for fast flow across the whole org, not parts
- Feedback loops: Dev informed and guided by Ops
- Culture of continual experimentation and learning: sensing and feedback for every team interaction
- Simplest: Teams with both dev and ops capabilities drive continuous feedback
- Without: Establish and nurture clear communication paths between Ops and Dev to provide info about operability, reliability, usability, securability, etc, and allow dev teams to correct and navigate toward designs that reduce operational overhead.
- Dev and Ops must develop empathy for each other, improving interactions and providing better services.
- The team that designs and builds the software must be involved with running and operational aspects in order to build it effectively, while also taking responsibility for the commercial viability of the service to ensure decisions that are fiscally responsible.
- Encourage teams to care about software by avoiding maintenance teams, which break the feedback loop between Ops and Dev, as well as prevent learning between the maintenance(who has little chance to apply new approaches or telemetry to existing software) and new-tech teams(who are free to implement new tech / approaches without seeing whether they're effective). Each s-a team should expect to maintain one or more older systems alongside newer ones being built and run, allowing them to retrofit telemetry from the newer systems into the old and learn from past mistakes.
- Ops engineers will need to recognize and triage problems quickly to provide useful info to colleagues, so err on the more experienced side.
- Orgs must adapt due to rapid changes in tech, markets, user demands, and regulatory requirements. Using the 4 topologies and 3 interaction modes gives orgs clarity of purpose for their teams, and tell teams explicitly how, when, and why they need to collaborate, consume/provide something as as ervice, and seek/provide facilitation.
-
Key take-aways
- Combine team-first approach with Conway's law, the four fundamental topologies, team interaction modes, topology evolution, and organizational sensing
- Get started: begin with the team, identify streams, identify the thinnest via platform, identify capability gaps, and practice team interactions
-
Common software delivery challenges: Disengaged teams, recurring surprises due to tech and markets, friction with Conway's law, software too big for teams, many org design options and delivery frameworks, teams pulled in many directions, frequent reorgs, and poor change flow.
-
Most orgs obsess over "feature delivery" without considering the human and team dynamics of modern software, exceeding team members' cognitive load and driving disengagement.
-
Conway's law frequently ignored -> haphazard arch choices and significant friction against Conway.
-
Poorly chosen reorgs can destroy capability for innovation and delivery.
-
Too many similar frameworks for delivery, most of which don't specify team behavior patterns and interaction modes -> silos or tight coupling.
-
Team-first approach clarifies responsibilities and arch(via org structure), turning inter-team friction into steering signals for the org.
- Types
- Stream-Aligned: team aligned to main flow of biz change, x-func skills mix, ability to deliver significant increments without external deps
- Platform: works on underlying platform supporting s-a teams. Platform simplifies complex tech and reduces cognitive load for delivery teams.
- Enabling: assists other teams in adopting or modifying software during a transition or learning period
- Complicated-Subsystem: special remit for a subsytem requiring too much specialist knowledge for an s-a or platform team.
- Modes
- Collaboration: two teams work together on a shared goal, particularly during discovery of new tech or approaches. More overhead, rapid learning.
- x-as-a-Service: one team consumes a service provided by another with minimal collab.
- Facilitating: one team(generally enabling) facilitates another in learning or adopting a new approach.
- Team is the fundamental means of delivery, not a collection of individuals but an entity with its own learning, goals, mission, and autonomy. Team learns and delivers together. External API is composed of code, documentation, onboarding processes, interactions with other teams, etc.
- Subsystem size is limited to what's manageable by a single team. Exceeding max team cog load is avoided, so whole team is comfy with complexity. People-first rather than technology-first.
- Restructuring teams and facilitating(or limiting) inter-team communication has a better chance of building systems that evolve naturally and work well in production.
- Increased collab isn't always increased communication: If we need to deploy different system parts independently with short lead time, and we decide to use small, decoupled services to do so, then teams must should be similarly small and decoupled with clear responsibility boundaries.
- Even performant orgs may limit adoption of effective tech and practices due to team org(e.g., BDUF from architects will fail without aligning with team communication patterns).
- Approaches like microservices accomodate the limited cognitive capacity of people, better allowing teams to innovate and support the systems as the systems are fully understood. Approaches like promise theory can help teams increase their day-to-day owner ownership of code and APIs.
- To facilitate, org structure must match the required software arch.
- Team structures and communication pathways need to evolve with tech and org maturity. Discovery requires collaboration with blurred boundaries, but keeping that structure post-discovery may lead to wasted effort and misunderstandings.
- Org should expect teams to collab to discover new patterns and execution models, then push those down into platform and supporting tooling.
- Additional needs:
- Healthy org culture: environment that supports professional development, in which people feel empowered and safe to speak out about problems, and the org learns continuously.
- Good eng practices: tdd, ci/cd, pairing, blameless incidents, etc.
- Healthy funding and financial practices: no CapEx/OpEx split between different parts of IT(at worst, mitigating the split by estimating CapEx/OpEx through sampling the work), avoiding project-driven deadlines and large-batch budgeting wherever possible, and allocating training budgets to teams/groups rather than individuals.
- Clarity of biz vision: exec or leadership provides a clear, non-conflicting vision and direction for the org, with horizaons at human-relevants timescales(3 months, 6 months, one year) and clear reasoning behind priorities, so people can understand how and why they were chosen.
- Above needs are the foundation that allows Team Topologies to thrive. Clarity of purpose and vision sets the context for everyone in the org to act in ways that address that purpose.
- Start with the Team
- What does the team need in order to
- Act and operate as an effective team
- Own part of the software effectively
- Focus on meeting user needs
- Reduce unnecessary cognitive load
- Consume and provide software and info to other teams
- Honest answers should lead to team-first approaches to office space, dev tooling, usability of platforms, realistic subsystem/domain splitting, team-friendly arch, rich telemetry, etc.
- Starting with teams allows addressing other aspects of fast flow: alignment to streams, the platform, and additional capabilities to support and enhance how teams work.
- What does the team need in order to
- Identify suitable streams of change
- Org must choose a set of change streams that act as "pipes" down which the most important changes flow. These streams are the main focus for flow, and all other work takes place to help flow within these streams.
- Stream choice is org-specific, but some typicals:
- Citizen-oriented tasks for govt online services: applying for a passport, paying taxes, registering for healthcare(task-oriented streams)
- Business banking products: online money mgmt, automation of bank transactions, invoicing clients(role-oriented streams)
- Online ticket purchasing: ticket searching and purchases, managing user account, refunds(activity streams)
- Regional products: Euro, North America, Asia, etc(geographical streams)
- Market segment: consumer, small and medium biz, enterprise, large corp(user-type streams)
- s-a teams should be aligned to identified streams, and streams should match the "change pressure" from the org's core. If no clear set of change streams, then need to identify those before proceeding.
- Identify a thinnest viable platform
- Streams in hand, identify services needed to support a reliable, swift flow of change in those streams. These will serve as the plaform upon which services depend, but only needs to be "big enough" to meet the flow needs for the teams: spectrum from docs that help teams use underlying services to full, in-house solution built to meet the needs of the s-a teams.
- Platform evolves over time. May start off needing to build a solution for infra provisioning, discard that in a few years in favor of a newly available cloud solution that fits better.
- Tech is only ever part of the platform - Roadmaps, guided evolution, clear docs, focus on DevEx, appropriate encapsulation of underlying complexity are as critical.
- Identify capability gaps in team coaching, mentoring, service mgmt, docs
- Once you have team-first approach based on core streams of change enabled by a platform, must ensure that teams have the capabilities and skills they'll need to succeed, including: team coaching, mentoring(especially of senior staff), service mgmt(for all kinds of teams and areas, not just for prod systems), well-written docs, and process improvement.
- Note: Team Topologies doesn't cover how to undertake large-scale org transformation, and recommends work of Mary Lynn Manns and Linda Rising
- The above capabilities within teams helps them improve their practices, communicate, and interact with each other, enabling the whole org to increase rate of flow change.
- Share and practice different interaction modes and explain principles behind new ways of working
- Team-first approach will be foreign to many, so will need to explain and demonstrate team interaction modes. Explain why some teams are closer together and others are far apart. Explain basics of Conway's law and how conscious design of teams and intercommunications can help improve the arch of the systems being built by restricting the solution search space and saving time and effort for everyone.
- Emphasize the human aspects: Focus on team, explicit limits on cognitive load, reduction in interrupts, limit on free-for-all comms.
- Emphasize how approach yields better outcomes for people, systems, and the org.