You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
Copy file name to clipboardExpand all lines: 02-Regression.qmd
+20-12Lines changed: 20 additions & 12 deletions
Original file line number
Diff line number
Diff line change
@@ -51,21 +51,23 @@ This model is formed by making the the line of best fit determined by the minimu
51
51
52
52
Another illustration:
53
53
54
-
{width="800"}
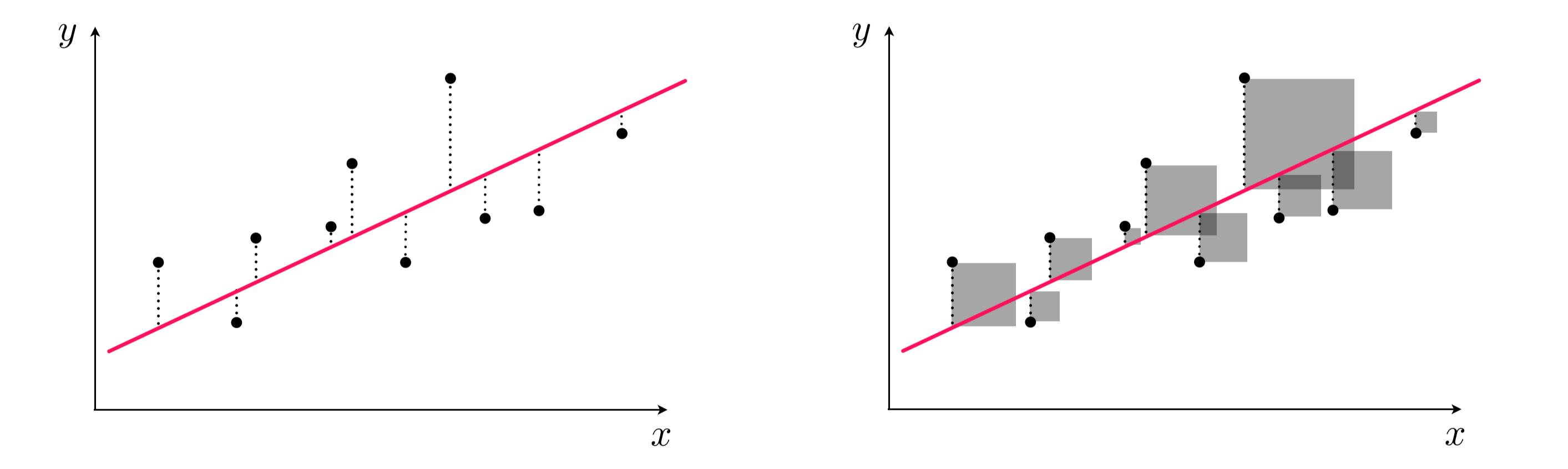
Left panel: difference between response and predicted response (residual). Right panel: squared difference between predicted response and response.
55
57
56
58
## Assumptions of linear regression
57
59
58
60
Any model that one uses has some assumptions about the data that allows the model to make good predictions. *Note that there are other types of assumptions if your modeling technique is focused on inference*.
59
61
60
-
Here are common situations when the assumptions of linear regression are *not* held:
62
+
Let's take a look what are the assumptions needed for a sound model, and what we can do to address it not upheld.
61
63
62
-
### Non-Linearity of responder-predictor relationship
64
+
### Linearity of responder-predictor relationship
63
65
64
66
The linear regression model assumes that there is a straight line (linear) relationship between the predictors and the response. It doesn't ask for the straight line relationship to be perfect, but rather on average the cloud of points has a linear shape. If that is not true, then our prediction is going to be less accurate.
65
67
66
68
To check for this relationship, we have to calculate the **residual**, which is the difference between the response value and the predicted response value (similar to a type of model performance metrics we examined last week). Then, we can make a **residual plot** of the predicted response vs. residual. Ideally, this residual plot should have no pattern - some residuals above 0, some below 0, but no strong trend.
67
69
68
-
If there's a trend in the data, that means there are non-linear associations in the data.
70
+
If there's a trend in the data, that means there are non-linear associations between some of the predictors and the response.
69
71
70
72
```{python}
71
73
residual = y_train - y_train_predicted
@@ -79,17 +81,23 @@ plt.show()
79
81
80
82
We see there's a slight curve in our residual plot. We will look at ways to deal with this later in this lecture.
81
83
82
-
### Outliers
84
+
### No Outliers
85
+
86
+
An **outlier** is an obseravtion for which the response is far from the value predicted response (y-axis). An observation has high **leverage** if it has an unusual predictor value (x-axis). Outliers and high leverage observations arise may arise out of incorrect measurements, among many other causes. When these observations cause significant changes to the regression model, they are called **influential**. They may greatly contribute to the Mean Squared Error, as observations away the majority of the data will have exponentially large residuals.
87
+
88
+
Some possible solutions:
89
+
90
+
- We can eyeball for for potential influential points by exploratory data analysis, and see how the model changes if we remove it. We may troubleshoot with the instruments that generated the data in the first place to diagnosis.
83
91
84
-
-An **outlier** is an obseravtion for which the response is far from the value predicted response. An observation has high **leverage** if it has an unusual predictor value. Outliers and high leverage observations arise may arise out of incorrect measurements, among many other causes. Outliers and high leverage observations that cause changes to the regression model is called **influential**. They may greatly contribute to the Mean Squared Error, as observations away the majority of the data will have exponentially large residuals.
92
+
-We can detect an influential point via computing the studentized residuals or cook's distance and decide whether it makes sense to remove it.
85
93
86
-
- We can detect an influential point via computing the studentized residuals or cook's distance and decide whether it makes sense to remove it
94
+
- We can use a different linear regression method, called Huber loss regerssion, that allows more tolerance for outliers.
87
95
88
-
- We can use a different linear regression method, called Huber loss regerssion, that allows more tolerance for outliers.
96
+
### Predictors are not colinear
89
97
90
-
### Collinearity of predictors
98
+
**Colinearity** is the situation when two or more predictors are linearly related to each other. If we put collinear predictors into our regression model, they start to serve as redundant information to our model and can degrade predictive performance.
91
99
92
-
**Colinearity** is the situation when two or more predictors are closely linearly related to each other. If we put collinear predictors into our regression model, they start to serve as redundant information to our model and can degrade predictive performance.
100
+
Some possible solutions:
93
101
94
102
- We can detect collinearity to look at the correlation matrix between predictors. This works well for pairwise correlations.
95
103
@@ -123,7 +131,7 @@ ax.set_xlim([10, 50])
123
131
plt.show()
124
132
```
125
133
126
-
### Number of predictors more than the number of samples
134
+
### Number of predictors is less than the number of samples
127
135
128
136
Sometimes, in machine learning, we have more predictors than the number of samples. This is called a **high dimensional** problem. Our regression method will not work here and we need to find ways to reduce the number of predictors.
According to our model, the relationship between $BMI$ and $MeanBloodPressure$ is a linear line with slope $\beta_1$, and the additional predictor of $Gender$ will change our prediction by only a constant, $\beta_2$. However, this plot suggests that our original model isn't quite right: the additional predictor of Gender changes our prediction by more than a constant - it is dependent on $BMI$ also.
209
+
According to our model, the relationship between $BMI$ and $MeanBloodPressure$ is a linear line with slope $\beta_1$, and the additional predictor of $Gender$ will change our prediction by only a constant, $\beta_2$. Visually, that would look like two parallel lines, with $\beta_2$ dictating the distance between parallel lines. However, this plot suggests that our original model isn't quite right: the additional predictor of Gender changes our prediction by more than a constant - it is dependent on $BMI$ also.
202
210
203
211
When multiple predictors have an synergistic effect on the outcome, their effect on the outcome occurs jointly - this is called an **Interaction**. To incorporate this into our model, we add an interaction term:
0 commit comments