You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
StartTime | int64 | Yes | Trigger time, Unix timestamp in seconds
137
136
EndTime | int64 | No | Recovery time, Unix timestamp in seconds, default 0
138
-
CloseTime | int64 | No | Close time, EndTime is alert recovery time, CloseTime is processing progress close time. Alert automatically closes upon recovery, manual closure doesn't affect alert recovery. Unix timestamp in seconds, default 0
139
137
`Labels` | map[string]string | No | Label key-value pairs, both Key and Value are strings
| start_time | int64 | Yes | First trigger time (time of first event received by platform), Unix timestamp in seconds |
71
70
| last_time | int64 | Yes | Latest event time (time of most recent event received by platform), Unix timestamp in seconds |
72
71
| end_time | int64 | No | Alert recovery time (time when platform last received end-type event), Unix timestamp in seconds, defaults to 0 |
73
-
| close_time | int64 | No | Closure time, different from end_time, this indicates progress closure, not actual alert recovery. Unix timestamp in seconds, defaults to 0 |
74
72
| labels | map[string]string | No | Label key-value pairs, both Key and Value are strings |
75
73
| event_cnt | int64 | No | Number of associated events |
76
74
| incident |[Incident](#Incident)| No | Associated incident |
@@ -103,7 +101,6 @@ curl -X POST 'https://example.com/alert/webhook?a=a' \
103
101
"alert_status":"Warning",
104
102
"channel_id":1163577812973,
105
103
"channel_name":"Order System",
106
-
"close_time":0,
107
104
"created_at":1683766015,
108
105
"data_source_id":1571358104973,
109
106
"data_source_name":"Aliyun SLS",
@@ -131,7 +128,6 @@ curl -X POST 'https://example.com/alert/webhook?a=a' \
| start_time | int64 | Yes | First trigger time (time of first event received by platform), Unix timestamp in seconds |
102
101
| last_time | int64 | Yes | Latest event time (time of latest event received by platform), Unix timestamp in seconds |
103
102
| end_time | int64 | No | Alert recovery time (time of last end-type event received by platform), Unix timestamp in seconds, default 0 |
104
-
| close_time | int64 | No | Close time, different from end_time, this is processing progress closure, doesn't mean alert actually recovered. Unix timestamp in seconds, default 0 |
105
103
| labels | map[string]string | No | Label KV pairs, both Key and Value are strings |
106
104
107
105
</div>
@@ -132,7 +130,6 @@ curl -X POST 'https://example.com/incident/action?a=a' \
132
130
"alert_key": "asdflasdfl2xzasd112621",
133
131
"alert_severity": "Critical",
134
132
"alert_status": "Critical",
135
-
"close_time": 0,
136
133
"created_at": 1699869567,
137
134
"data_source_id": 2398086111504,
138
135
"description": "cpu.idle < 20%",
@@ -148,10 +145,6 @@ curl -X POST 'https://example.com/incident/action?a=a' \
description: "The Alert Engine (Monitors) integrates with various metric and log data sources, performs threshold evaluation based on user-configured alert rules through periodic data queries, generates alert events, and finally pushes them to Flashduty On-call for aggregation and delivery."
2
+
title: "Alerting Engine (Monitors) Introduction"
3
+
description: "The Alerting Engine (Monitors) integrates with various metric and log data sources, performs threshold evaluation based on user-configured alert rules through periodic data queries, generates alert events, and finally pushes them to Flashduty On-call for aggregation and delivery."
The Alert Engine (Monitors) integrates with various metric and log data sources, performs threshold evaluation based on your configured alert rules through periodic data queries, generates alert events, and finally pushes them to Flashduty On-call for aggregation and delivery.
10
+
The Alerting Engine (Monitors) integrates with various metric and log data sources, performs threshold evaluation based on your configured alert rules through periodic data queries, generates alert events, and finally pushes them to Flashduty On-call for aggregation and delivery.
11
11
12
-
Flashduty Monitors can replace the alerting capabilities of products like Nightingale, vmalert, and elastalert. The Monitors alert engine is designed to be extremely flexible and deeply integrated with On-call products, capable of meeting various complex alerting requirements.
12
+
Flashduty Monitors can replace the alerting capabilities of products like Nightingale, vmalert, and elastalert. The Monitors alerting engine is designed to be extremely flexible and deeply integrated with On-call products, capable of meeting various complex alerting requirements.
13
13
14
-
## Alert Engine (Monitors) Architecture Design
14
+
## Alerting Engine (Monitors) Architecture Design
15
15
16
-
Flashduty is a SaaS service that cannot access data sources within users' private networks from the SaaS side. Therefore, the Alert Engine (Monitors) consists of two parts:
16
+
Flashduty is a SaaS service that cannot access data sources within users' private networks from the SaaS side. Therefore, the Alerting Engine (Monitors) consists of two parts:
17
17
18
18
-**SaaS Server**: Responsible for managing alert rules and permissions
19
19
-**monitedge**: Deployed within users' private networks, synchronizes alert rules from SaaS, performs periodic data queries and threshold evaluation, generates alert events and pushes them to the SaaS side
The diagram assumes that the customer has two data centers, East US and South China. Each data center has a `monitedge` instance deployed, responsible for alert evaluation of data sources within their respective data centers and pushing alert events to the SaaS side.
26
26
27
27
If you only have one data center, or if the network quality between data centers is good, you can also deploy only one `monitedge` instance to handle alert evaluation for all data sources.
28
28
29
29
If you are concerned about single point of failure risks when deploying one `monitedge`, you can also deploy multiple `monitedge` instances to form a cluster. For example, deploy 2 `monitedge` instances in the East US data center to form a cluster, setting the same cluster name through the `--alerter.clusterName meidong` parameter when starting the instances; deploy 2 `monitedge` instances in the South China data center to form another cluster, setting another cluster name through the `--alerter.clusterName huanan` parameter when starting these two instances.
30
30
31
-
Multiple instances in an alert engine cluster will automatically shard the processing of alert rules. For example, if this cluster needs to process 100 alert rules, the system will automatically balance the load, allowing each `monitedge` instance to process 50 rules respectively. If one instance fails, another instance will take over the processing of all 100 alert rules, ensuring high availability while avoiding duplicate alert event delivery.
31
+
Multiple instances in an alerting engine cluster will automatically shard the processing of alert rules. For example, if this cluster needs to process 100 alert rules, the system will automatically balance the load, allowing each `monitedge` instance to process 50 rules respectively. If one instance fails, another instance will take over the processing of all 100 alert rules, ensuring high availability while avoiding duplicate alert event delivery.
-**Rule Name**: The name of the alert rule, for easy identification and management. Variable references are not supported because names may be used for filtering, aggregation and other operations in the future, and fixed names are more convenient for processing.
54
54
-**Additional Labels**: Similar to `labels` in Prometheus alert rules, they will be attached to all alert events generated by this rule, facilitating filtering, routing, inhibition and other operations in On-call.
Monitors can make one rule effective for multiple data sources, and wildcards can be used, such as `db-*`, indicating that this rule will apply to all data sources whose names start with `db-`.
61
61
62
62
> ⚠️ Note: Because wildcards need to be supported here for data sources, data source names are stored instead of data source IDs. If the data source name is modified, it will affect the effectiveness of alert rules. Please be cautious when modifying data source names.
This section is used to configure how to query data from data sources and how to determine alert conditions. This functionality is designed to be very flexible, which also brings higher complexity. Please read the usage instructions on the right side of **Query Detection Method** on the page to understand the configuration method.
69
69
70
70
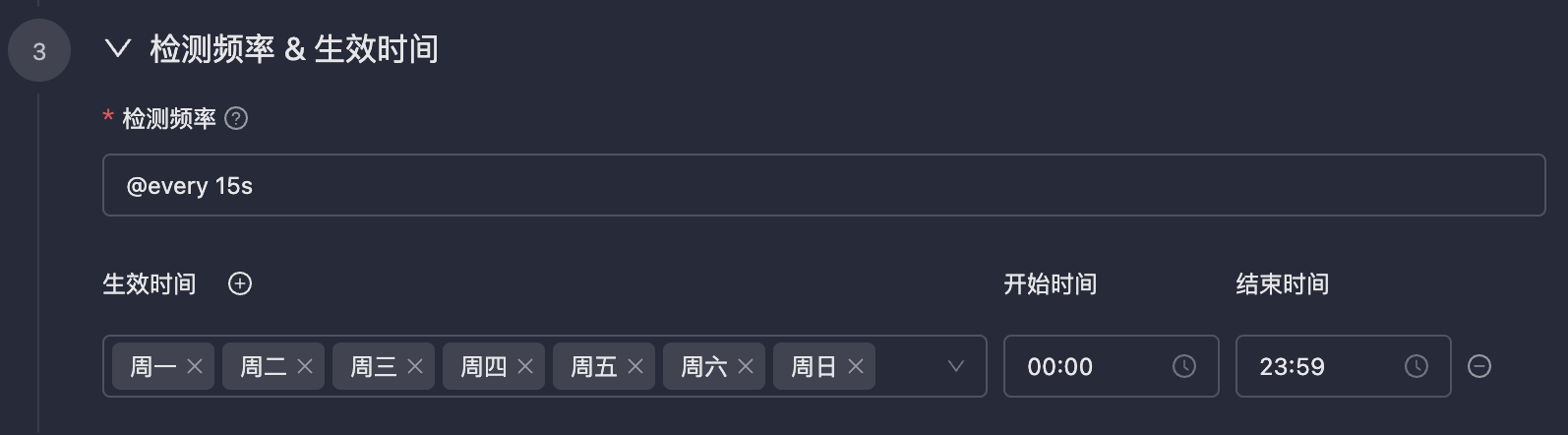
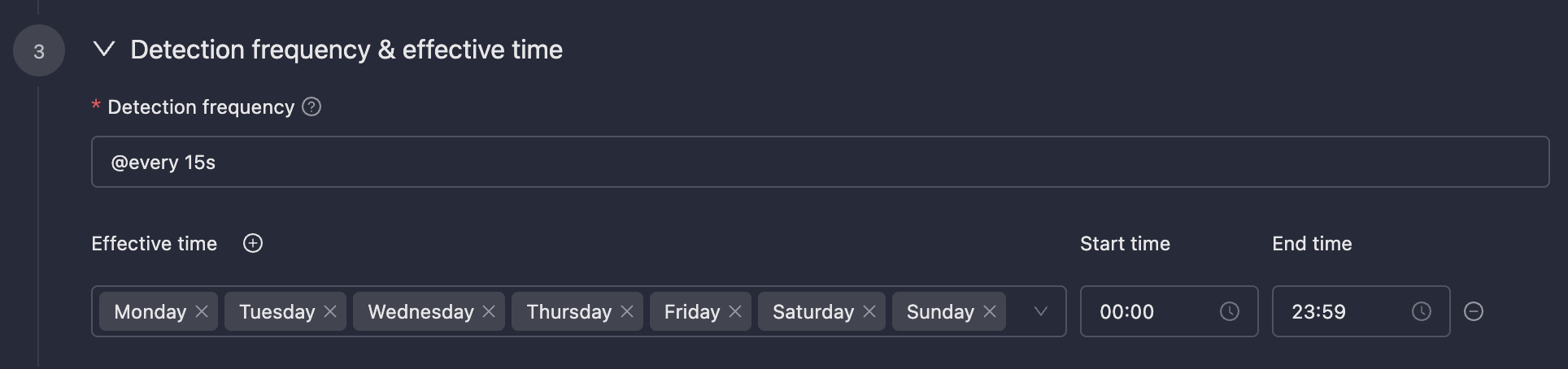
### Detection Frequency & Effective Time
71
71
72
-
72
+
73
73
74
74
-**Detection Frequency**: Usually periodic detection, also supports configuring `cron` expressions. The `cron` expressions in Monitors are accurate to the second.
75
75
-**Effective Time**: Configure the effective time period for alert rules. Alerts will not be triggered during non-effective time periods.
@@ -88,18 +88,18 @@ This section is used to configure how to query data from data sources and how to
88
88
89
89
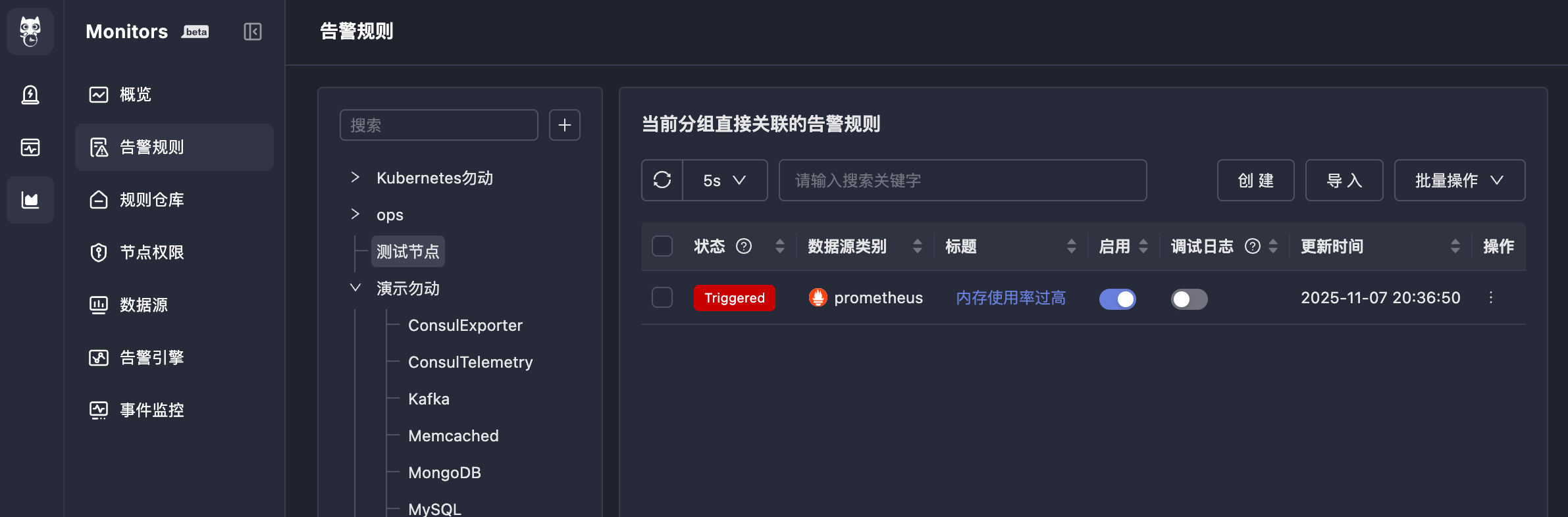
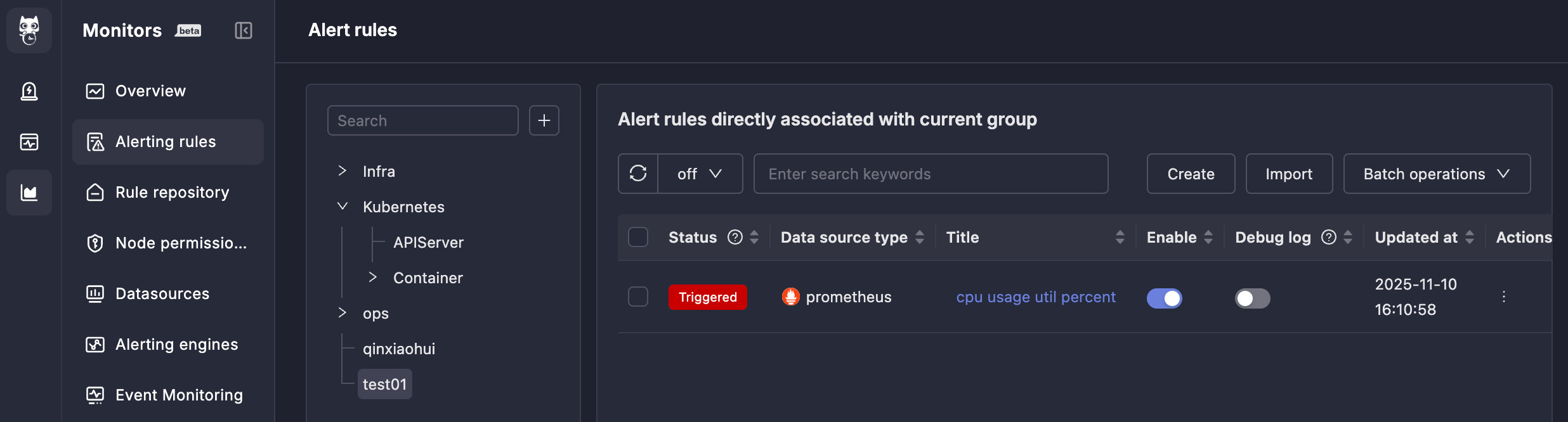
After completing the above configuration, if alert conditions are triggered, alert events will be generated, and the status in front of the alert rule will also change to `Triggered`.
90
90
91
-
91
+
92
92
93
93
Clicking `Triggered` will show the alert events generated by this rule (you can also view them in On-call):
Continue clicking on the alert event title to see the alert event details, divided into three tabs: **Alert Overview**, **Timeline**, **Associated Events**. These are all functions of the On-call system, and the meaning of each field is also quite obvious, so they will not be described one by one here.
98
98
99
99
## 5. Import Alert Rules
100
100
101
101
If you already have a batch of Prometheus alert rules and want to quickly import them into Monitors for use, you can use the alert rule import function. Menu entry: Alert Rules → Import.
The requirement is to import Prometheus alert rule YAML format text, in the standard Prometheus alert rule file format with `groups` as the root node. The YAML indentation must be correct, otherwise the import will fail.
0 commit comments