|
1 | 1 | --- |
2 | 2 | title: "Loki Alert Rule Configuration" |
3 | | -description: "This document provides detailed instructions on configuring alert rules for Loki data sources in Monitors. Monitors supports Loki's LogQL query syntax and can perform aggregation analysis on log data to trigger alerts." |
| 3 | +description: "This document details how to configure Loki data source alert rules in the Monitors alert engine. Monitors supports Loki's LogQL query syntax, enabling aggregation analysis of log data and alert triggering." |
4 | 4 | date: "2025-12-30T18:21:50.775+08:00" |
5 | | -url: "https://docs.flashcat.cloud/en/flashduty/monitors/loki-alert-rules" |
| 5 | +url: "https://docs.flashcat.cloud/en/flashduty/monitors/loki-alert-rules?nav=01JCQ7A4N4WRWNXW8EWEHXCMF5" |
6 | 6 | --- |
7 | 7 |
|
8 | | -This document provides detailed instructions on configuring alert rules for Loki data sources in Monitors. Monitors supports Loki's LogQL query syntax and can perform aggregation analysis on log data to trigger alerts. |
| 8 | +This document details how to configure Loki data source alert rules in the Monitors alert engine. Monitors supports Loki's LogQL query syntax, enabling aggregation analysis of log data and alert triggering. |
9 | 9 |
|
10 | 10 | ## Core concepts |
11 | 11 |
|
12 | 12 | Loki's query language LogQL is divided into two categories: |
13 | | - |
14 | 13 | 1. **Log queries**: Return log line content (Stream). |
15 | | -2. **Metric queries**: Count or aggregate logs, returning numeric values (Vector). |
16 | | - |
17 | | -**Monitors alert engine primarily uses metric queries**. Always use functions like `count_over_time`, `rate`, `sum` to convert logs into numeric series for threshold evaluation. |
| 14 | +2. **Metric queries**: Count or aggregate logs, such as using `count_over_time` function to return values (Vector). |
18 | 15 |
|
19 | 16 | --- |
20 | 17 |
|
21 | 18 | ## 1. Threshold mode |
22 | 19 |
|
23 | | -This mode is suitable for scenarios requiring multi-level threshold evaluation on log aggregation values (e.g., Info/Warning/Critical). |
| 20 | +This mode is suitable for scenarios that require multi-level threshold evaluation (such as Info/Warning/Critical) on log aggregation values. |
24 | 21 |
|
25 | 22 | ### Configuration |
26 | 23 |
|
27 | | -- **Query**: Write a LogQL that returns numeric vectors. |
28 | | - - Example: Count log entries containing the `error` keyword in the `mysql` job over the last 5 minutes. |
29 | | - ```logql |
30 | | - count_over_time({job="mysql"} |= "error" [5m]) |
31 | | - ``` |
32 | | -- **Threshold conditions**: |
33 | | - - **Critical**: `$A > 50` (more than 50 error logs in 5 minutes) |
34 | | - - **Warning**: `$A > 10` (more than 10 error logs in 5 minutes) |
| 24 | +* **Query statement (LogQL)**: Write a LogQL that returns a numeric vector (select "Statistics" query mode). |
| 25 | + * *Example*: Count the number of logs containing the `error` keyword in the `mysql` job over the last 5 minutes. |
| 26 | + ```logql |
| 27 | + count_over_time({job="mysql"} |= "error" [5m]) |
| 28 | + ``` |
| 29 | +* **Threshold conditions**: |
| 30 | + * **Critical**: `$A > 50` (more than 50 error logs in 5 minutes) |
| 31 | + * **Warning**: `$A > 10` (more than 10 error logs in 5 minutes) |
35 | 32 |
|
36 | 33 | ### How it works |
37 | | -
|
38 | | -The engine executes the LogQL query and retrieves time series data with labels (Vector). It iterates through each series, extracting values to compare against the configured threshold expressions. |
| 34 | +The engine executes the LogQL query and retrieves time series data (Vector) with labels. The engine iterates through each series, extracts the value, and compares it against the configured threshold expressions. |
39 | 35 |
|
40 | 36 | ### Recovery logic |
41 | | -
|
42 | | -- **Auto recovery**: Automatically recovers when query result values fall below the threshold. |
43 | | -- **Specific recovery conditions**: Configure conditions like `$A < 5` to prevent flapping near the threshold. |
44 | | -- **Recovery query**: |
45 | | - - Supports configuring an independent LogQL for recovery evaluation. |
46 | | - - Supports `${label_name}` variable substitution. |
47 | | - - Example: Alert checks for error logs, recovery checks for specific recovery logs `count_over_time({job="mysql"} |= "recovered" [5m])`. |
| 37 | +* **Automatic recovery**: When the query result value falls below the threshold, it automatically recovers. |
| 38 | +* **Specific recovery condition**: Can be configured as `$A < 5` to avoid oscillation near the threshold. |
| 39 | +* **Recovery query**: |
| 40 | + * Supports configuring a separate LogQL for recovery evaluation; recovery is triggered as long as data is found. |
| 41 | + * Supports `${label_name}` variable substitution. |
| 42 | + * *Example*: Alert on error logs, recover on specific recovery logs `count_over_time({job="mysql"} |= "recovered" [5m])`. |
48 | 43 |
|
49 | 44 | --- |
50 | 45 |
|
51 | 46 | ## 2. Data exists mode |
52 | 47 |
|
53 | | -This mode is suitable for users who prefer writing filter conditions directly in LogQL, or scenarios where you only care about "whether anomalous data exists". |
| 48 | +This mode is suitable for scenarios where you prefer to write filter conditions directly in LogQL, or only care about "whether abnormal data exists". This mode is recommended for log anomaly detection alerts. |
54 | 49 |
|
55 | 50 | ### Configuration |
56 | 51 |
|
57 | | -- **Query**: Write a LogQL with comparison operators that only returns data meeting the conditions. |
58 | | - - Example: Directly filter services with error rates exceeding 5%. |
59 | | - ```logql |
60 | | - rate({job="ingress"} |= "500" [1m]) / rate({job="ingress"} [1m]) * 100 > 5 |
61 | | - ``` |
62 | | -- **Evaluation rule**: An alert is triggered as soon as the LogQL query returns data. |
| 52 | +* **Query statement (LogQL)**: Write a LogQL containing comparison operators that returns only data meeting the conditions. |
| 53 | + * *Example*: Directly filter out services with error rates exceeding 5%. |
| 54 | + ```logql |
| 55 | + count_over_time({job="ingress"} |= "error-code-500" [5m]) / count_over_time({job="ingress"} [5m]) * 100 > 5 |
| 56 | + ``` |
| 57 | +* **Evaluation rule**: An alert is triggered as long as the LogQL query returns data. |
63 | 58 |
|
64 | 59 | ### Pros and cons |
65 | | -
|
66 | | -- **Pros**: Computation logic is pushed down to the Loki server, reducing data transmission. |
67 | | -- **Cons**: Cannot distinguish between alert severity levels; can only trigger a single level alert. |
| 60 | +* **Pros**: Computation logic is pushed down to the Loki server, reducing data transfer. |
| 61 | +* **Cons**: Cannot distinguish alert levels; can only trigger a single level of alert. |
68 | 62 |
|
69 | 63 | ### Recovery logic |
70 | | -
|
71 | | -- **Data disappearance means recovery**: Recovery is confirmed when the LogQL query result is empty (i.e., the `> 5` condition is no longer met). |
72 | | -- **Recovery query**: Supports configuring additional query statements to assist in determining recovery status. |
| 64 | +* **Recover when data disappears**: When the LogQL query result is empty (i.e., no longer meets the `> 5` condition), recovery is determined. |
| 65 | +* **Recovery query**: Supports configuring additional query statements to assist in determining recovery status. |
73 | 66 |
|
74 | 67 | --- |
75 | 68 |
|
76 | 69 | ## 3. No data mode |
77 | 70 |
|
78 | | -This mode monitors whether log reporting pipelines are interrupted, or whether logs that should be continuously generated have stopped. |
| 71 | +This mode is used to monitor whether the log reporting pipeline is interrupted, or whether logs that should be continuously generated have stopped. |
79 | 72 |
|
80 | 73 | ### Configuration |
81 | 74 |
|
82 | | -- **Query**: Write a query that should always have data. |
83 | | - - Example: Calculate log reporting rate for all hosts. |
84 | | - ```logql |
85 | | - rate({job="node-logs"} [1m]) |
86 | | - ``` |
87 | | -- **Evaluation rule**: If a Series (uniquely identified by labels, e.g., `instance="host-1"`) existed in previous cycles but cannot be found in the current and N consecutive cycles, a "no data" alert is triggered. |
| 75 | +* **Query statement (LogQL)**: Write a query that should always have data. |
| 76 | + * *Example*: Count the log reporting rate for all hosts. |
| 77 | + ```logql |
| 78 | + rate({job="node-logs"} [1m]) |
| 79 | + ``` |
| 80 | +* **Evaluation rule**: If a Series (uniquely identified by labels, such as `instance="host-1"`) existed in previous cycles but cannot be found in the current and consecutive N cycles, a "no data" alert is triggered. |
88 | 81 |
|
89 | 82 | ### Typical applications |
90 | | -
|
91 | | -- Monitor whether collection agents like Promtail/Fluentd have stopped working. |
92 | | -- Monitor whether critical business logs (such as order creation logs) have been abnormally interrupted. |
| 83 | +* Monitor whether collection agents like Promtail/Fluentd have stopped working. |
| 84 | +* Monitor whether critical business logs (such as order creation logs) have been abnormally interrupted. |
93 | 85 |
|
94 | 86 | --- |
95 | 87 |
|
96 | | -## 4. Best practices and considerations |
97 | | -
|
98 | | -### Avoid querying raw logs |
99 | | -
|
100 | | -**Do not** use LogQL that only returns log streams in alert rules (e.g., `{job="mysql"} |= "error"`). |
101 | | -
|
102 | | -- **Reason**: The alert engine needs numeric values for calculations and evaluation. Raw log streams cannot be directly used for threshold comparisons. |
103 | | -- **Correct approach**: Must wrap with aggregation functions like `count_over_time(...)`. |
| 88 | +## 4. Get original logs when alerting |
104 | 89 |
|
105 | | -### Performance optimization |
| 90 | +You can get original logs through related queries when alerting. However, it is usually not recommended to get too many; just get 1 as a log sample to include in the alert message. |
106 | 91 |
|
107 | | -- **Time range**: The time range in LogQL (e.g., `[5m]`) should be moderate. Too large a range leads to slow queries, while too small a range may cause high data volatility. |
108 | | -- **Label filtering**: Use precise label filters in the LogQL Stream Selector section (within braces `{...}`) as much as possible to reduce the amount of data scanned. |
| 92 | +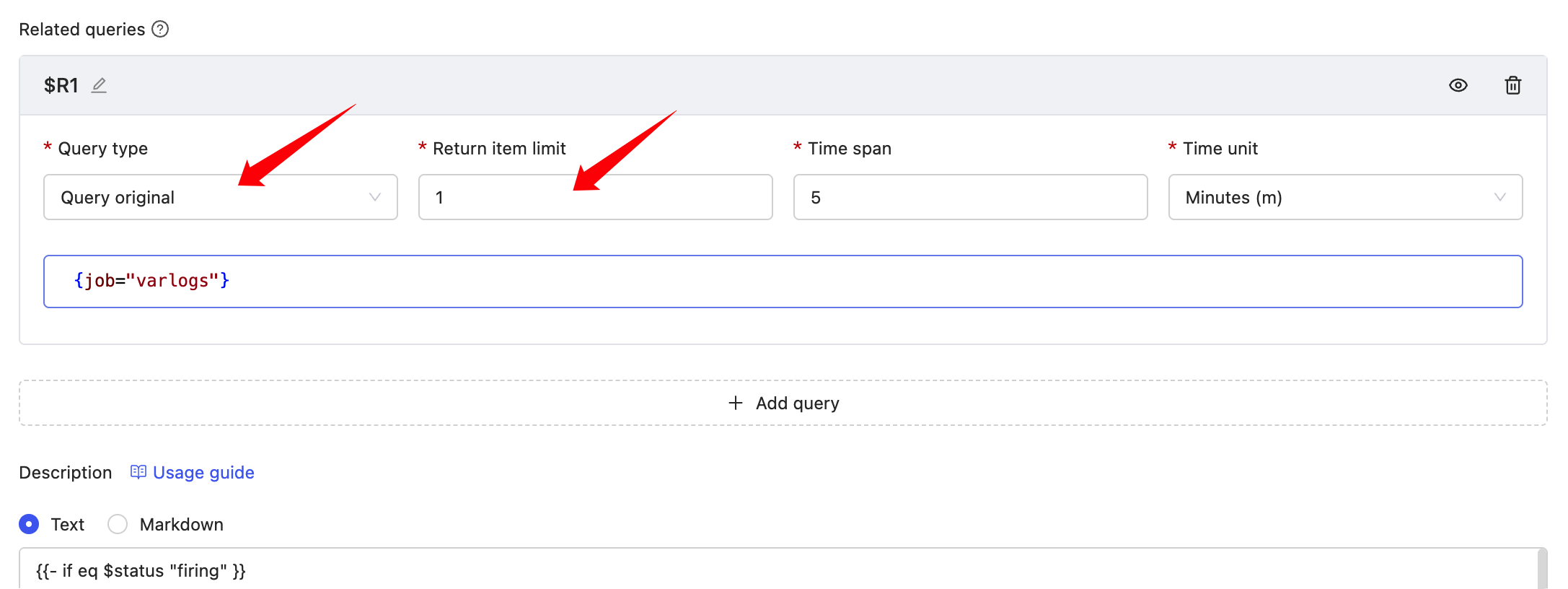 |
109 | 93 |
|
| 94 | +The results of related queries can be rendered in the "Note description", example: |
110 | 95 |
|
| 96 | +``` |
| 97 | +{{- if eq $status "firing" }} |
| 98 | +error log count: {{ $value | printf "%.3f" }} |
| 99 | +{{- range $x := $relates.R1}} |
| 100 | +Loki log time: {{(nanoTime $x.Fields.__time__ 8).Format "2006-01-02T15:04:05Z07:00"}} |
| 101 | +Loki Log line: {{$x.Fields.__log__}} |
| 102 | +{{- end}} |
| 103 | +{{- end}} |
| 104 | +``` |
0 commit comments