|
| 1 | +--- |
| 2 | +title: "Quick Start" |
| 3 | +description: "Monitors quick start guide to help you quickly get started with Monitors functionality." |
| 4 | +date: "2025-11-07T19:24:43.956+08:00" |
| 5 | +url: "https://docs.flashcat.cloud/en/flashduty/monitors/installation?nav=01JCQ7A4N4WRWNXW8EWEHXCMF5" |
| 6 | +--- |
| 7 | + |
| 8 | +To experience Monitors functionality, there are three core steps: install `monitedge`, create data sources, and create alert rules. |
| 9 | + |
| 10 | +## 1. Install monitedge |
| 11 | + |
| 12 | +`monitedge` needs to be deployed within users' private networks, responsible for synchronizing alert rules from SaaS, performing periodic data source queries and threshold evaluation, generating alert events and pushing them to the SaaS side. To experience alerting functionality, you must first install `monitedge`. |
| 13 | + |
| 14 | +Menu entry: Alert Engine → Engine Installation/Upgrade. You can choose any of the three installation methods: Linux, Docker, or Kubernetes. |
| 15 | + |
| 16 | +Pay special attention to the **Engine Cluster Name**. `monitedge` instances with the same **Engine Cluster Name** will form a cluster, jointly sharding the processing of alert rules to avoid single point of failure risks. If you only plan one set of `monitedge` clusters, the engine cluster name can maintain the default `default`; if you plan multiple sets of `monitedge` clusters, such as one set for the East US data center and one set for the South China data center, please specify different engine cluster names for each set of clusters. |
| 17 | + |
| 18 | +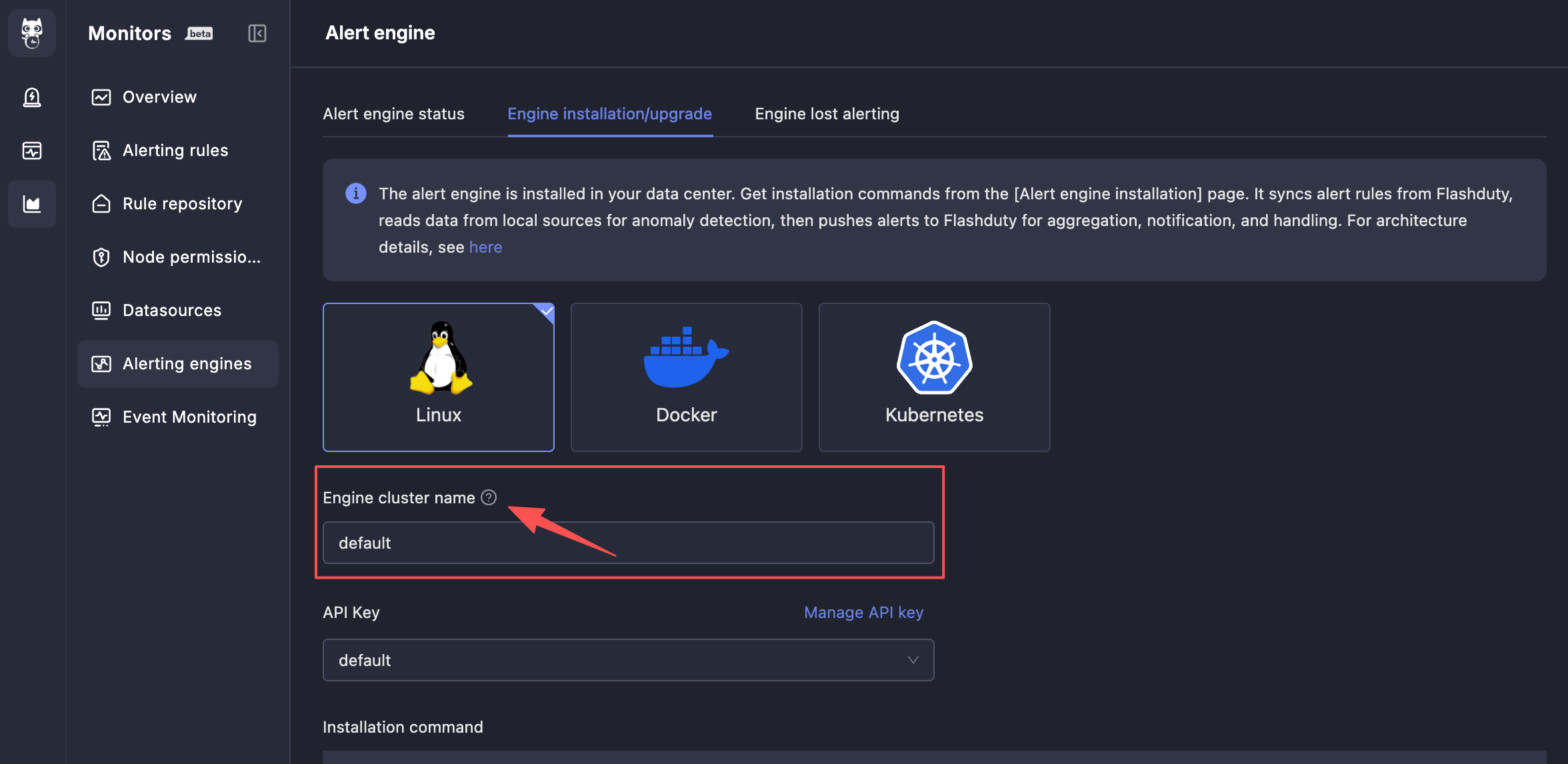 |
| 19 | + |
| 20 | +### Alert Engine Status |
| 21 | + |
| 22 | +After the alert engine `monitedge` is installed, it will automatically connect to the SaaS side and periodically synchronize alert rules. You can view the current alert engine status information on the alert engine status page. |
| 23 | + |
| 24 | +Some alert engine instances that have not had heartbeats for a long time will display a delete button. You can click the delete button to remove these long-inactive alert engine instances from the system to avoid engine disconnection alerts. |
| 25 | + |
| 26 | +### Engine Disconnection Alerts |
| 27 | + |
| 28 | +If the alert engine (`monitedge`) fails, the impact is significant. Therefore, engine disconnection alerts are provided to promptly issue alert notifications when the engine fails. For engine clusters composed of multiple instances, as long as one instance in the cluster is alive, engine disconnection alerts will not be triggered because the cluster can still work normally. |
| 29 | + |
| 30 | +## 2. Create Data Sources |
| 31 | + |
| 32 | +Menu entry: Data Sources, click the **New** button to create a data source. |
| 33 | + |
| 34 | +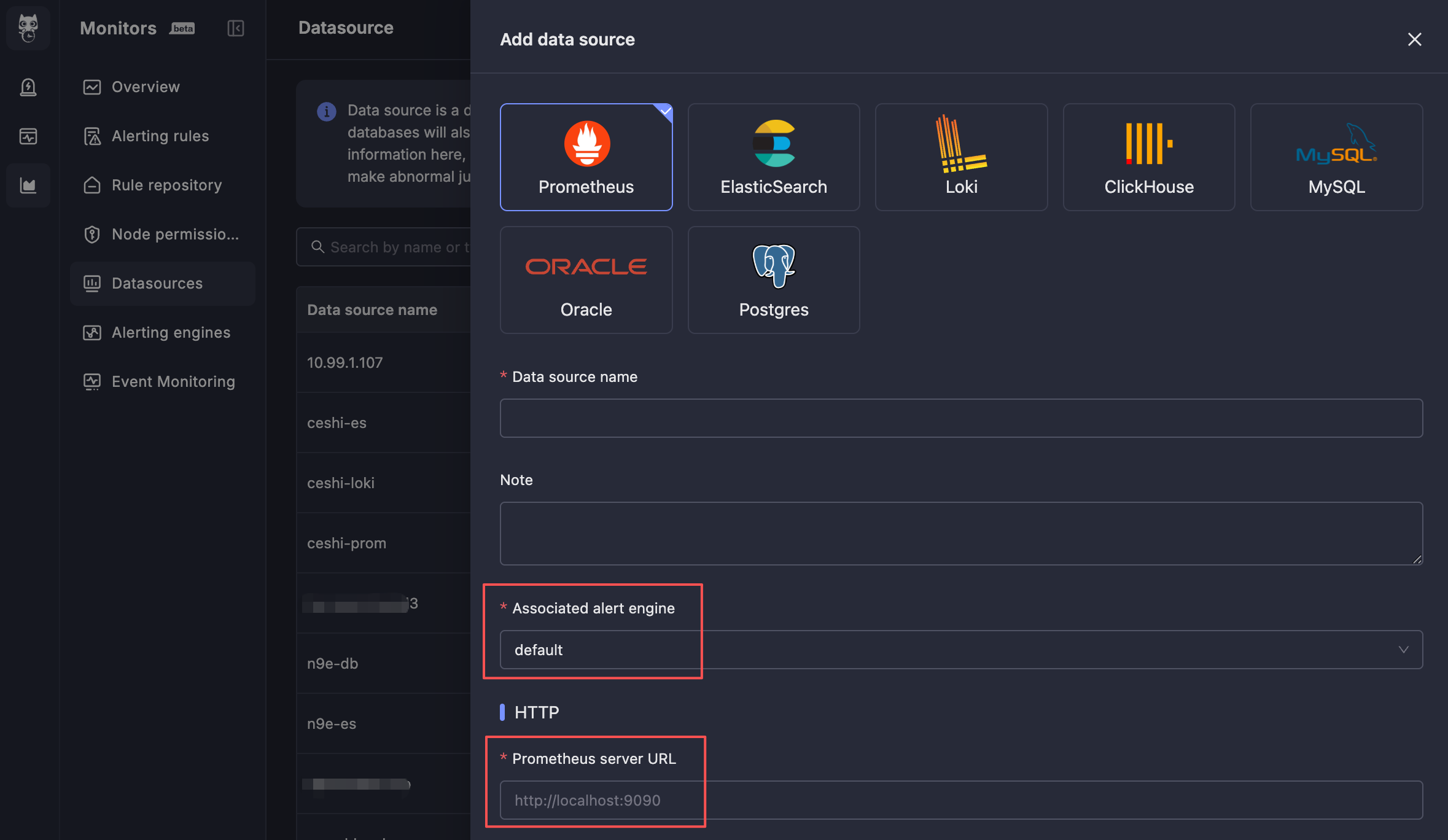 |
| 35 | + |
| 36 | +The two most critical configuration items: |
| 37 | + |
| 38 | +- **Associated Alert Engine**: Through this configuration item, specify which alert engine cluster will perform data queries and alert evaluation for this data source. Usually, select the alert engine cluster in the same data center. |
| 39 | +- **Data Source Connection Address**: This address is for `monitedge` to connect to, and must be an address that `monitedge` can access. Usually, this is an internal network address. |
| 40 | + |
| 41 | +## 3. Create Alert Rules |
| 42 | + |
| 43 | +Menu entry: Alert Rules. |
| 44 | + |
| 45 | +There may be many alert rules that need to be categorized and managed. Monitors provides a tree-structured grouping structure as a classification management solution for alert rules. Each alert rule must belong to a certain group. You can first create groups, then create alert rules under the groups. |
| 46 | + |
| 47 | +The following details the various configurations of alert rules. Each field usually has help tips next to it. You can hover your mouse over the help tip icons to view specific instructions. |
| 48 | + |
| 49 | +### Basic Configuration |
| 50 | + |
| 51 | +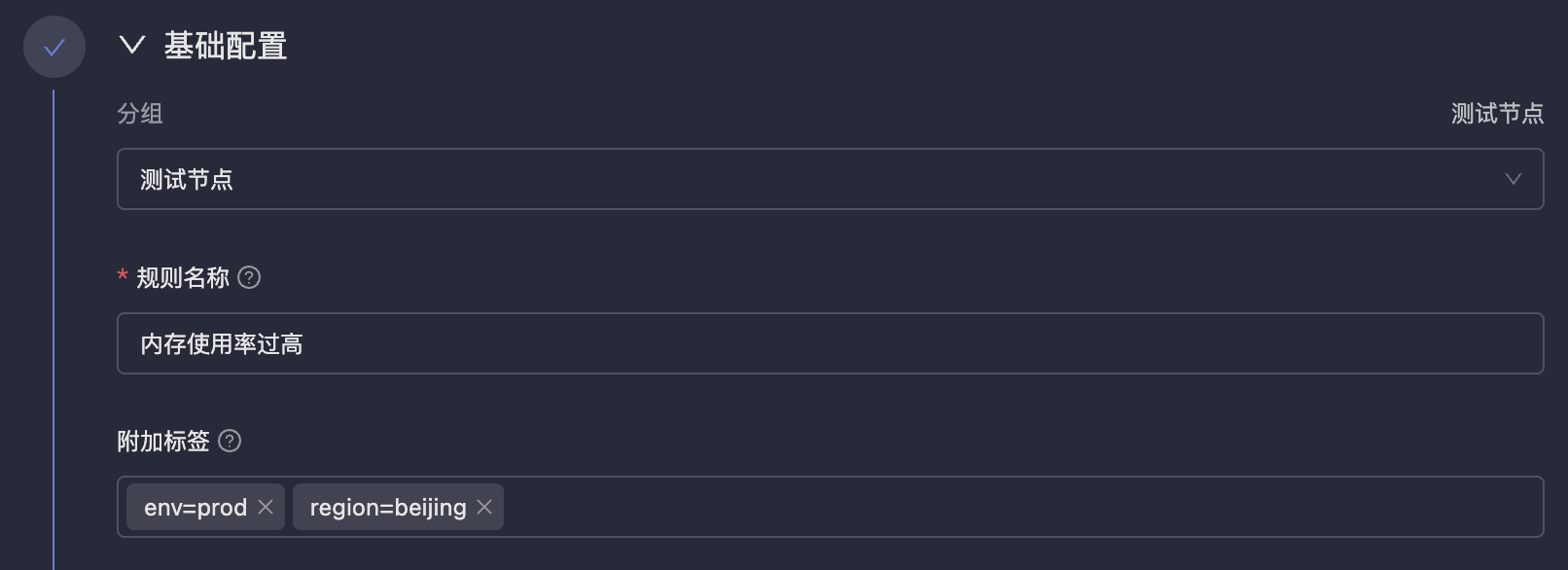 |
| 52 | + |
| 53 | +- **Rule Name**: The name of the alert rule, for easy identification and management. Variable references are not supported because names may be used for filtering, aggregation and other operations in the future, and fixed names are more convenient for processing. |
| 54 | +- **Additional Labels**: Similar to `labels` in Prometheus alert rules, they will be attached to all alert events generated by this rule, facilitating filtering, routing, inhibition and other operations in On-call. |
| 55 | + |
| 56 | +### Data Source Selection |
| 57 | + |
| 58 | +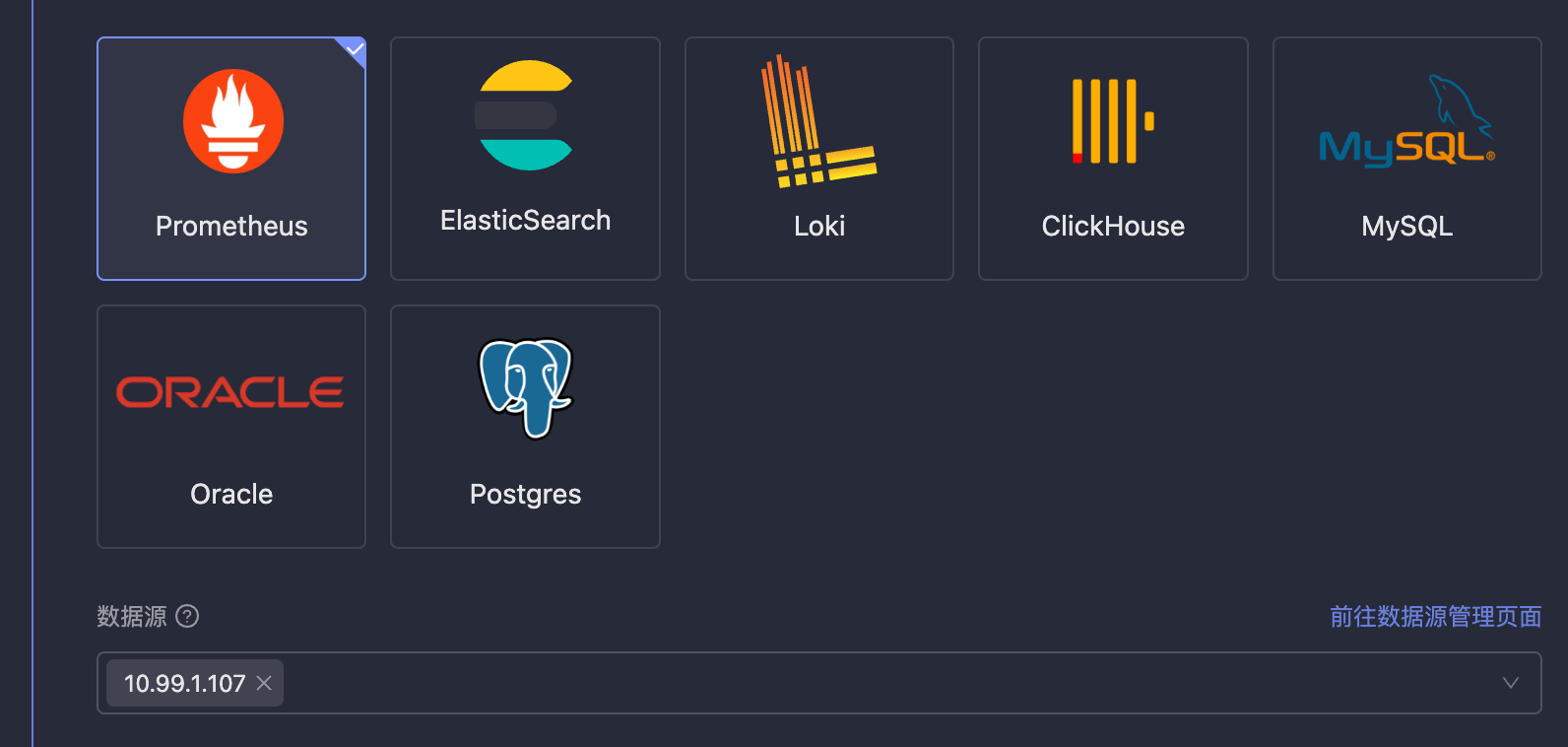 |
| 59 | + |
| 60 | +Monitors can make one rule effective for multiple data sources, and wildcards can be used, such as `db-*`, indicating that this rule will apply to all data sources whose names start with `db-`. |
| 61 | + |
| 62 | +> ⚠️ Note: Because wildcards need to be supported here for data sources, data source names are stored instead of data source IDs. If the data source name is modified, it will affect the effectiveness of alert rules. Please be cautious when modifying data source names. |
| 63 | +
|
| 64 | +### Query Detection Method |
| 65 | + |
| 66 | +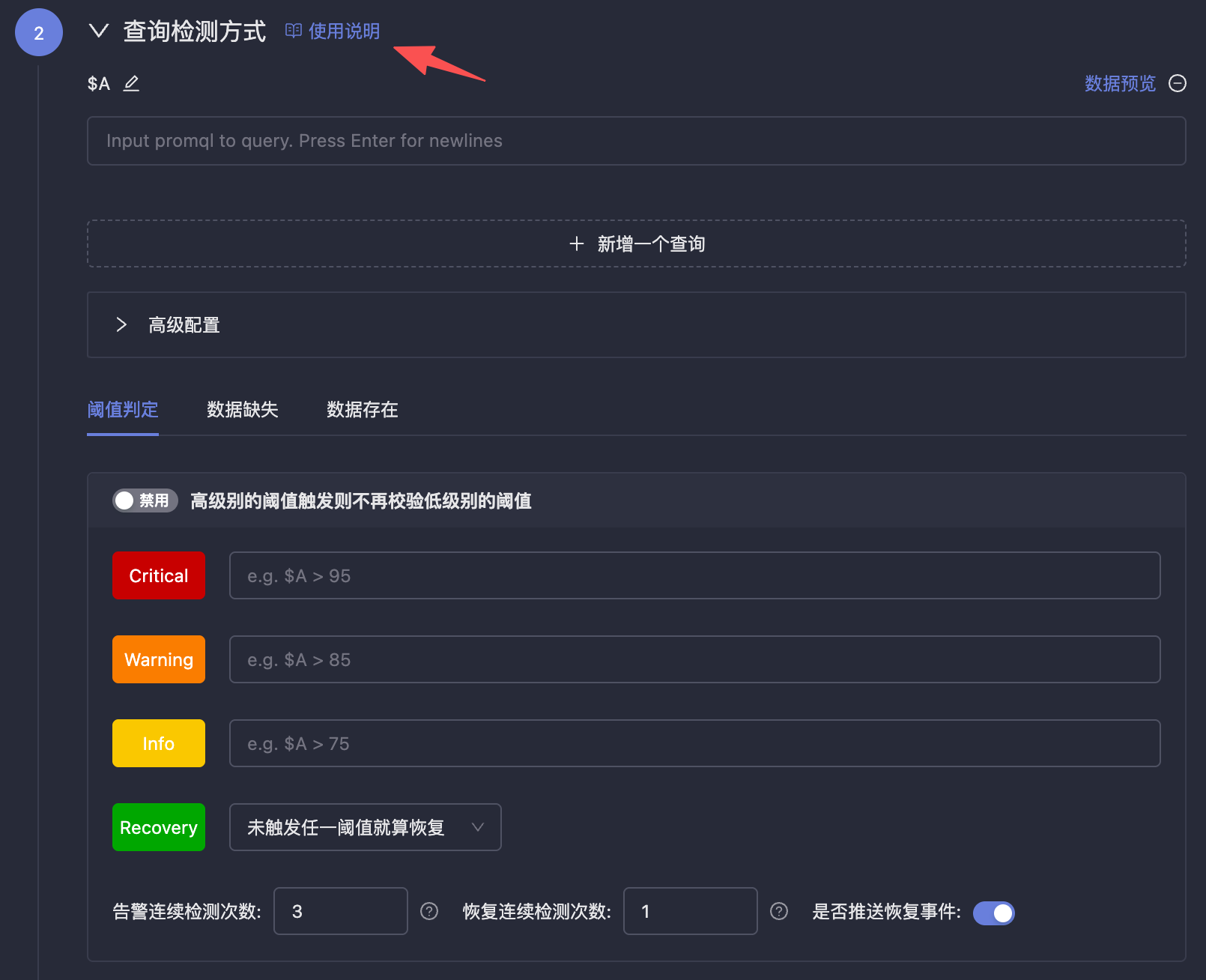 |
| 67 | + |
| 68 | +This section is used to configure how to query data from data sources and how to determine alert conditions. This functionality is designed to be very flexible, which also brings higher complexity. Please read the usage instructions on the right side of **Query Detection Method** on the page to understand the configuration method. |
| 69 | + |
| 70 | +### Detection Frequency & Effective Time |
| 71 | + |
| 72 | +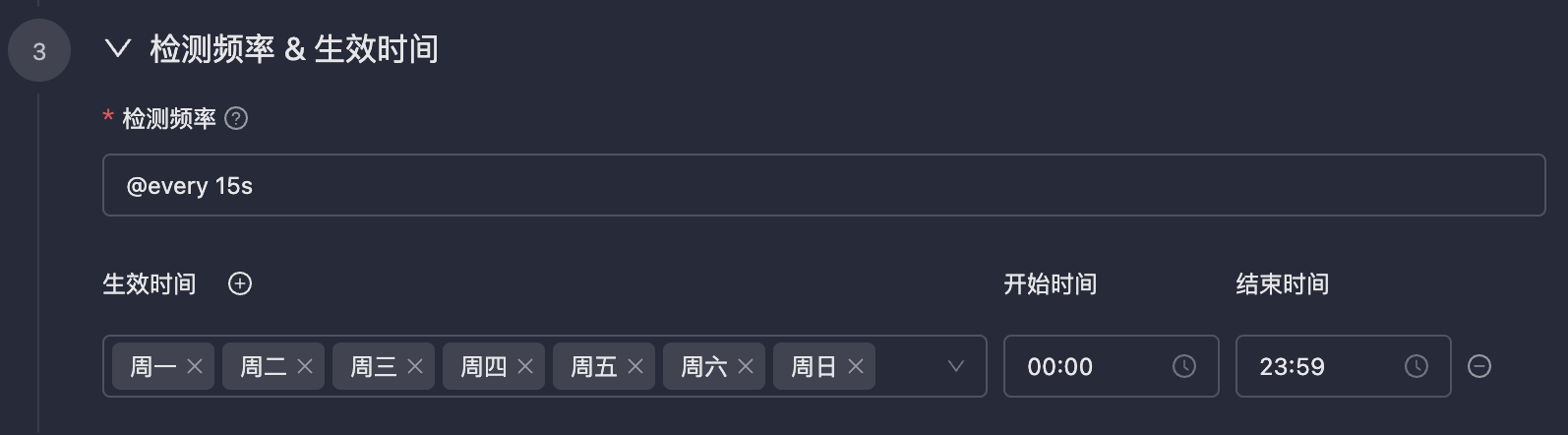 |
| 73 | + |
| 74 | +- **Detection Frequency**: Usually periodic detection, also supports configuring `cron` expressions. The `cron` expressions in Monitors are accurate to the second. |
| 75 | +- **Effective Time**: Configure the effective time period for alert rules. Alerts will not be triggered during non-effective time periods. |
| 76 | + |
| 77 | +### Event Configuration |
| 78 | + |
| 79 | +- **Custom Fields**: Similar to `annotations` in Prometheus alert rules, they will be attached to all alert events generated by this rule, such as attaching dashboard URLs, SOP URLs, etc. |
| 80 | +- **Associated Query**: The results of associated queries are not used as data basis for alert threshold determination, but can be placed in remarks as variable references, facilitating viewing more contextual information in On-call to assist in troubleshooting. For example, if the number of Error logs in the last 5 minutes is 1000, greater than 0 triggers an alert, and you want to attach a log sample to the alert event, you can use additional queries to achieve this. |
| 81 | +- **Remark Description**: This field is extremely critical. It is an unstructured text field that supports variable references. Alert events will display the content of this field, facilitating rapid positioning and problem handling by on-call personnel. For specific configuration methods, please refer to the usage instructions on the right side of **Remark Description**. |
| 82 | +- **Channel**: Refers to the channel in Flashduty On-call. If a channel is specified, alert events will be sent to the specified channel; if not specified, alert events will be sent to integrations, and then determined which channels to deliver to based on routing rules configured in the integrations. For specific situations, please refer to the prompt instructions on the right side of **Channel**. |
| 83 | +- **Repeat Notification**: If alerts do not recover, continuous notifications can be sent at specified intervals, and the maximum number of notifications can also be specified, defaulting to 10000 times. |
| 84 | + |
| 85 | +> ⚠️ Note: The maximum number of notifications does not represent the number of message reminders received by end users. Because alert events generated by Monitors will be delivered to On-call, On-call may perform aggregation and noise reduction processing on alert events. The final number of message reminders sent to end users depends on On-call configuration. |
| 86 | +
|
| 87 | +## 4. Results |
| 88 | + |
| 89 | +After completing the above configuration, if alert conditions are triggered, alert events will be generated, and the status in front of the alert rule will also change to `Triggered`. |
| 90 | + |
| 91 | +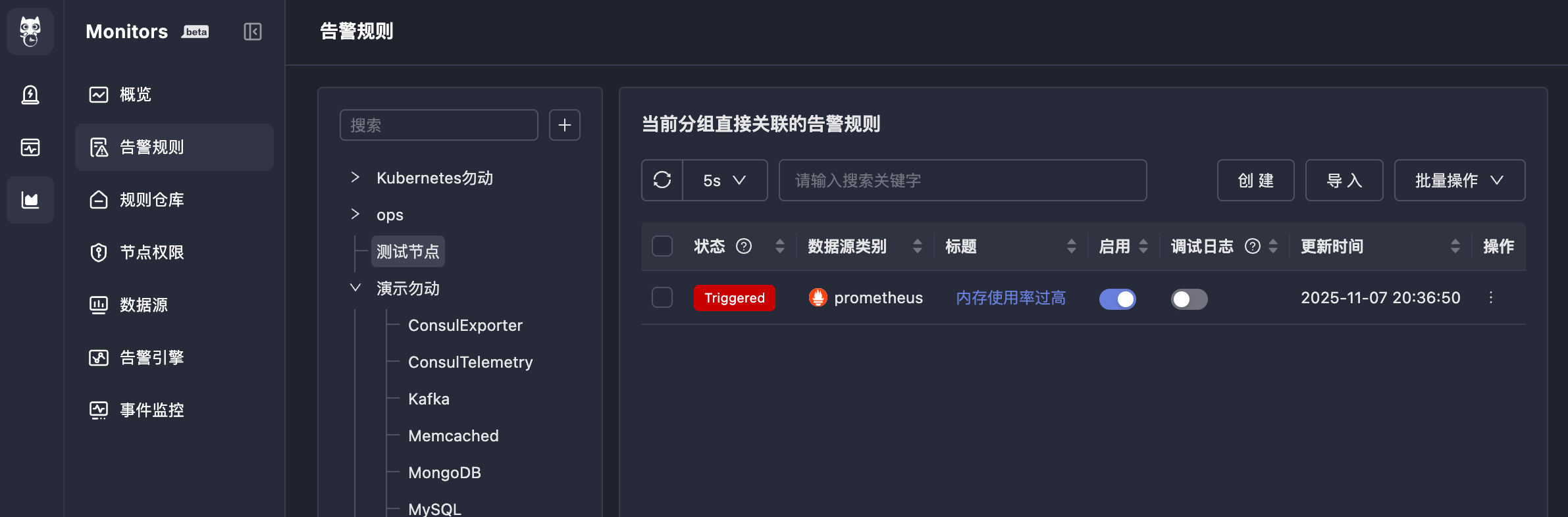 |
| 92 | + |
| 93 | +Clicking `Triggered` will show the alert events generated by this rule (you can also view them in On-call): |
| 94 | + |
| 95 | +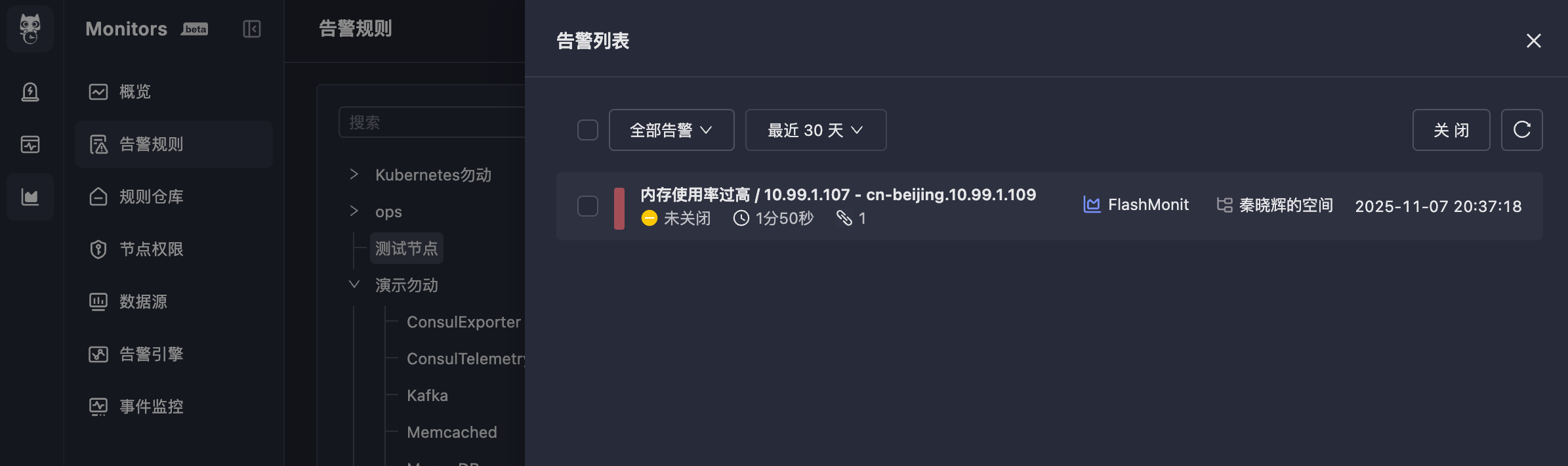 |
| 96 | + |
| 97 | +Continue clicking on the alert event title to see the alert event details, divided into three tabs: **Alert Overview**, **Timeline**, **Associated Events**. These are all functions of the On-call system, and the meaning of each field is also quite obvious, so they will not be described one by one here. |
| 98 | + |
| 99 | +## 5. Import Alert Rules |
| 100 | + |
| 101 | +If you already have a batch of Prometheus alert rules and want to quickly import them into Monitors for use, you can use the alert rule import function. Menu entry: Alert Rules → Import. |
| 102 | + |
| 103 | +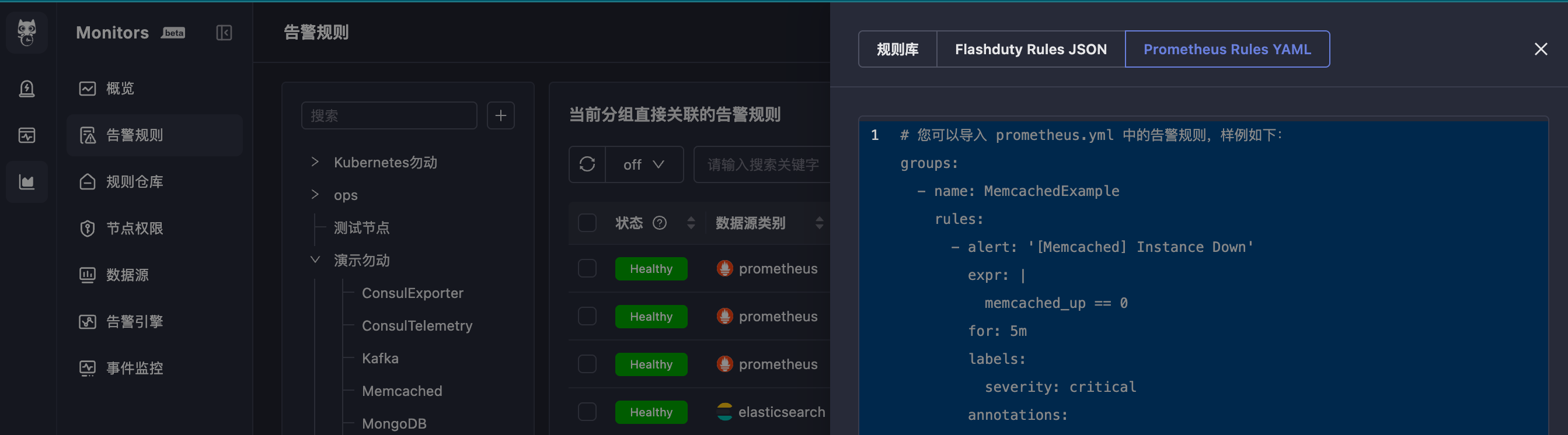 |
| 104 | + |
| 105 | +The requirement is to import Prometheus alert rule YAML format text, in the standard Prometheus alert rule file format with `groups` as the root node. The YAML indentation must be correct, otherwise the import will fail. |
0 commit comments