Implement dataset class for training the MAE model.
Model input:
N x T x F x D
where:
- N = batch size (?)
- T = number of frames per window (64 representing ~2 seconds)
- F = number of features/landmarks (478 using mediapipe's face_mesh)
- D = feature dimension (2 x, y)
The dataset was saved in json files with the following fields:
- id: frame number
- results: pose data
- list of tuples with length=478 landmarks, each tuple contains x and y coordinates
- timestamps
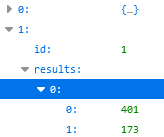
see json file sample:
extracted pose sample
Implement dataset class for training the MAE model.
Model input:
N x T x F x D
where:
The dataset was saved in json files with the following fields:
see json file sample:
extracted pose sample