title: Algorithms date: 7/14/14-9/3/14 time: M & W 10am - 1pm affiliation: Columbia University, Lede Program instructors: Jonathan Soma, Chris Wiggins location: 607c Pulitzer Hall *
new room schedule:
- M Aug 4: 318 Hamilton
- W Aug 6: 318 Hamilton
- M Aug 11: 318 Hamilton
- W Aug 13: 318 Hamilton
- M Aug 18: 607B (j-school)
- W Aug 20: 607B (j-school)
- M Aug 25: 607B (j-school)
- W Aug 27: 607B (j-school)
- M Sept 1: Labor Day
- W Sept 3: 607B
Multiliteracies in algorithms: functional literacy, critical literacy, and rhetorical literacy. Within critical literacy, a strong emphasis will be knowing what is possible. For algorithms, this usually means computational complexity -- the study of how the time needed to perform an algorithm grows as the problem size (e.g., the number of data) grows. For algorithms dealing with data, we will study how this leads to a balance between fast and accurate. Within functional literacy, we will be building on Python's tools for learning from data, including scikit-learn. Rhetorical literacy will be the anchor for the class, as our primary interest is in producing technology-enabled journalism.
"every piece of digital technology embeds within it a model of the world, and acts as an argument for that model." --mark hansen
- What is an algorithm?
- Algorithms in computer science (searching, sorting, clustering)
- Algorithms in real life
- Algorithmic thinking
- Step after step
- Reductions/Black boxes
- Multiliteracies
- Functional literacy
- Rhetorical literacy
- Critical literacy
- Summary of projects
- Documentation
- Agile vs Waterfall
- Analysis of algorithm
- Computationally (Functionally)
- Correctness, Termination, Time, Space
- Generality
- Critically (Nick Diakopoulos)
- Prioritization
- Classification
- Association
- Filtering
- Computationally (Functionally)
- Examples of algorithms in journalism
- QuakeBot
- Narrative Science/Automated Insights
- Projects from last class
- ISO 3103 (2)
- Royal Society of Chemistry
- Orwell
- Automated Insights (2)
- Algorithmic Accountability Reporting by Nick Diakopoulos
- Introduction to first in-class project: building a democrat detector
Course tools: scikit-learn, pandas, ntlk, capitolwords.org's api (you will need to register for a key)
-Week Inspiration: Diakopolous Report
Focus: modeling: predictive and interpretable
- tools:
- data journalism and reproducibility
- upshot on github
- e.g., rangel charity
- e.g., world cup
- reminder: same bostock as in d3
- also producing tools, e.g., statement for getting congressional press statements
- upshot on github
- why open source?
- many eyes
- BUT this doesn't mean no bugs. cf., heartbleed
- overfitting (cf., Einstein's "Everything should be made as simple as possible, but not simpler."
- discussion of nifty projects
- sentiment analysis: it's a thing
- example of a sentiment analysis as a service company
- hedometer: example of a sentiment analysis research project
- more on naive bayes
- importance of probability
-Week Inspiration: Nifty project on authorship detection
- algorithms that learn from data to model the world ( i.e., machine learning)
- the role of optimization in those algos
- representation (e.g., documents)
- examples: reading aloud the authorship nifty assignment
- another example: bag of words
- introduce naive Bayes
- introduce probability and Bayes rule
- go through naive Bayes
- show how it's a graphical model (pictures, organizing stories in your head, a chance to talk about complexity)
- say but don't show how you could do this with priors and for multiclass
- talk about other classification algorithms
- how do decide what algorithm or priors are "best"?
- digression on meaning of modeling and desiderata of models
-Week Inspiration: what is Bayes theorem
- k-nearest neighbors (predicting from examples)
- back to 'Naive Bayes' and Bayes rule
- 'being Bayesian'
- critical literacy
- why this classifier? what else is possible?
- computational complexity: what is realistic?
- what assumptions are made?
- what is "good" modeling -- see Leo (an allusion to CP Snow's the two cultures
- rhetorical literacy: try something else!
- random forests
- decision trees,
- e.g., in ProPublica's message machine
- iris image as simple decision tree
- SVMs
- explore scikit-learn's classification algorithms
- introduction to unsupervised learning
- normalization via standard score
- preprocessing at command line
- more on data journalism
- supervised learning
- kmeans movie
- useful resources to learn more
{kind=link}
Possibly useful: Bayes Rule
- supervised learning/classification with probability modeling
Focus: Exploratory data analysis, iterative algorithms (and therefore fast-vs-accurate)
opening questions:
- how can journalists be disciplined while facing deadlines?
- hard with deadlines; cf., "The Goat Must Be Fed: Why digital tools are missing in most newsrooms", by the Duke Reporters' Lab, May 2014
- hard even for professional developers; cf., commit logs from last night
- growing awareness is already leading to novel field, and novel curricula. cf., the software carpentry movement.
- note that you ignore good software carpentry at your peril. cf., " How to lose $172,222 a second for 45 minutes"
- should the relationship between journalist and story end when story is published? (cf., "The leaked New York Times innovation report is one of the key documents of this media age", Joshua Benton, Neiman Journalism Lab )
- see also this summary/table of contents
- example of journalist engaging audience
- example of journalist turning relations with readers into new stories
new matters:
-
(supervised) regression and (over-)fitting
-
document clustering in kmeans
-
'GMM' (Gaussian/Normal/Bell curve mixture modeling)
- explanation
- image of pseudocode from ESL
- demo
- actual code for GMM
-
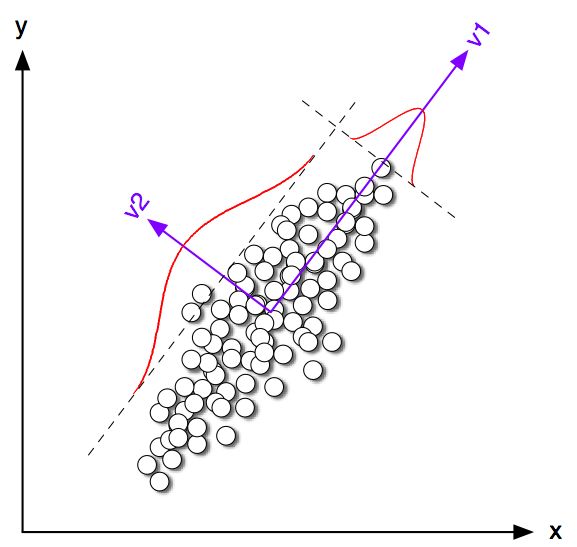
dimensionality reduction via PCA
-
try something else in scikit-learn from among their clustering algorithms! Try changing number of clusters! Go play!
{kind=link}
thoughts on UNIX and algorithms in your life:
- too many aliases, mathbabe post
- example: code to introduce people to each other
- example of pipes for word counting
- killall is useful
- some example aliases
-Week Inspiration: Krugman busts out probability
- generative clustering (clustering as inference)
(note: lots of room for critical literacy here)
- Networks - centralities - functional literacy - critical literacy: does choice of centrality matter? - critical literacy: how do you reduce human interactions into a graph? - graph drawing/graph visualization - critical literacy: does graph drawing mean anything? what are the axes?
Possibly useful networkx
- Graphs
- No class! (Labor day)
- Demos
- the site
- their tutorial on infernece
- their tutorial on scikit-learn
- 1-page algorithm cheat sheet
- (longer) user guide
- many examples
- Reading Machines, Stephen Ramsay, 2011
- NBA Census: https://raw.githubusercontent.com/ledeprogram/courses/master/algorithms/NBA-Census-10.14.2013.csv
- Iris data: https://raw.githubusercontent.com/ledeprogram/courses/master/algorithms/data/iris.csv
- Authorship data: https://raw.githubusercontent.com/ledeprogram/courses/master/algorithms/data/books/book-data.csv
- Mystery books: 1 2 3 4 5