...menustart
...menuend
-
映射方法
- 除法
h(k)= k mod m- pick m to be a prime , not too close to a power of 2 or 10
- sometimes , make the table size a prime is inconvenient
- 乘法
m = 2ʳ,w-bit wordsh(k)=(A·k mod 2ʷ) rsh (w-r)- A is an odd integer
2ʷ⁻¹ < A < 2ʷ - Don't pick A too close to 2ʷ⁻¹ or 2ʷ
- 除法
-
映射冲突解决方法
- 链表法
- 在冲突位置添加新节点
- open addressing
- 按照某种规则向后,或左右探测
- Linear probing: 线性探测
h(k,i)=(h'(k)+i) mod m
- Double hashing
h(k,i)=(h₁(k)+i·h₂(k)) mod m- h₂(k) must be relatively prime to m
- one way is to make m a power of 2 and design h₂(k) to produce only odd numbers
- Linear probing: 线性探测
- the expected number of probe is :
1/(1-a)- if the table is half full, then the expected number of probes is 1/(1-0.5)=2
- if the table is 90% full, then the expected number of probes is 1/(1-0.9)=10
- 按照某种规则向后,或左右探测
- 链表法
-
Universal hashing
- hash函数的弱点: 总能找到一组key, 使得hashing到同一个slot i
- 解决方案: choose the hash function at random, independently of the keys
- the chance of a collision between x and y is 1/m if we choose h randomly from H.
-
构造 Universal hashing
- let
mbe prime k=<k₀,k₁,...kᵣ>, 0 <= kᵢ < m- decompose key k into r+1 digits
- each digit in the set {0,1,...,m-1}
- k 的m进制表示
a = <a₀,a₁,...aᵣ>- aᵢ is choosen randomly from {0,1,...,m-1}
- 随机m进制数
- Define
hₐ(k)=Σaᵢkᵢ mod m.- Dot product mode m
- Fact from number theory
- Theorem: let m be prime. For any z ∈ Zm such that z ≠ 0, there exists a unique z⁻¹ ∈ Zm , such that
z·z⁻¹=1 (mod m)
- Theorem: let m be prime. For any z ∈ Zm such that z ≠ 0, there exists a unique z⁻¹ ∈ Zm , such that
- let
-
Perfect hashing
- 给定一组键集,构建一个静态hash table, 如果要查某个key是否在表中,在最坏的情况下,怎么做的做好。
- eg: 假定表中存的是1000个最常用英文单词,判断一个单词是否是常用单词,我要的不是预期的性能,我要确保最坏情况的性能。有没有相应的建表方法,能让我快速的查找。
- Given n keys, construct a static hash table of size m=O(n) (不需要很大的表),使得在最坏的情况下,查找的时间是O(1).
- Perfect hashing 采用2级结构
- 每一级上都采用 universal hashing
- 第一级按照正常 universal hashing, 可能发生冲突
- 第二级hash table 大小由此处碰撞个数nᵢ个数决定:
mᵢ=nᵢ², 第二级没有冲突 - Theorem: Let H be a class of universal hash functions for a table of size m=n², then we use a random h ∈ H to hash n keys into the table , then expected number of collisions is at most 1/2.
- 构造所有第二级的hash(多试几个hash)
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位
哈希表适用于 有大量查找的场合。
要统计最热门查询,首先就是要统计每个Query出现的次数,然后根据统计结果,找出Top 10。所以我们可以基于这个思路分两步来设计该算法。
- 第一步:Query统计
Query统计有以下俩个方法,可供选择:
- 直接排序法
- 一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,直接排序无法满足内存需求
- 当数据量比较大而且内存无法装下的时候,我们可以采用外排序的方法来进行排序,这里我们可以采用归并排序。
- 排完序之后我们再对已经有序的Query文件进行遍历,统计每个Query出现的次数,再次写入文件中。
- Hash Table法
- 维护一个Key为Query字串,Value为该Query出现次数的HashTable
- 直接排序法
- 第二步:找出Top 10
- 算法一:普通排序
- 算法二:堆排序
Purpose: maintain a (possibly evolving) set of stuff. (transactions, people associated data, IP address, etc. )
Insert: add new record
Delete: delete existing record
Lookup: check for a particular record
A hash table does not maintain an ordering on the elements that it supports.
All operations in O(1) time!
Applications:
- de-duplication 处理重复条目
- the 2-SUM problem
- Input: unsorted array A of n integers
- determine whether or not there are two numbers x,y = t
- Naive solution: O(n²)
- Better : (1) sort A ( O(nlogn) ) . (2) for each x in A , look t-x in A via binary seach ( O(nlogn) )
- Amazing : (1) insert elements into hash table H ,O(n). (2) for each x in A, look up t-x in H , O(n)
- symbol tables in compilers
- black list
- search algorithms , eg. in a chess playing program , the game tree exploration
- use hash table to avoid exploring any configuration more than once.
- pick n= #buckets , with n ≈ |S|
- choose a hash function :
- input key -> hash function -> position in array [0,1,2,...,n-1]
- use array A of length n, store x in A[h(x)]
23个人中,有两个人生日同天的概率 >= 50%.
所以,hash 出现 collision 的概率是非常高的。
Collision: distinct x,y∈U, such that h(x)=h(y)
- Solution#1: separate chaining
- keep a link list in each bucket
- 1 -> A
- 2 -> nil
- 3 -> B -> D
- 4 -> C
- Solution#2: open addressing
- only 1 object per bucket
- hash function replaced by probe sequence hs₁(x),h₂(x),...
哈希表有多种不同的实现方法,最常用的一种方法——拉链法,我们可以理解为“链表的数组”
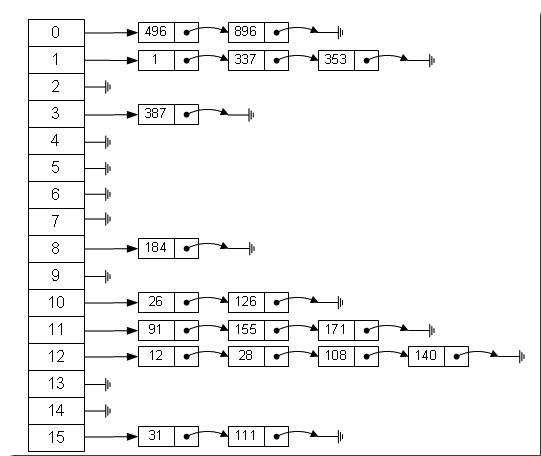
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。我们根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
元素特征转变为数组下标的方法就是散列法。散列法当然不止一种,下面列出三种比较常用的:
- 除法散列法
- 最直观的一种,上图使用的就是这种散列法,
- 公式:index = value % 16
- 平方散列法
- 求index是非常频繁的操作,而乘法的运算要比除法来得省时(对现在的CPU来说,估计我们感觉不出来),所以我们考虑把除法换成乘法和一个位移操作。
- 公式:index = (value * value) >> 28
- 如果数值分配比较均匀的话这种方法能得到不错的结果,但我上面画的那个图的各个元素的值算出来的index都是0——非常失败。也许你还有个问题,value如果很大,value * value不会溢出吗?答案是会的,但我们这个乘法不关心溢出,因为我们根本不是为了获取相乘结果,而是为了获取index。
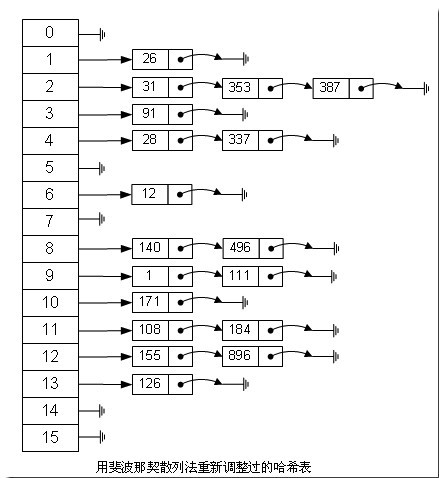
- 斐波那契(Fibonacci)散列法
- 平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
- 对于16位整数而言,这个乘数是40503
- 对于32位整数而言,这个乘数是2654435769
- 对于64位整数而言,这个乘数是11400714819323198485
- 这几个“理想乘数”是如何得出来的呢?这跟一个法则有关,叫黄金分割法则,而描述黄金分割法则的最经典表达式无疑就是著名的斐波那契数列,即如此形式的序列:0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946,…
- 对我们常见的32位整数而言
- 公式:index = ((value * 2654435769) mod ((2^32)-1) ) >> 28
- 平方散列法的缺点是显而易见的,所以我们能不能找出一个理想的乘数,而不是拿value本身当作乘数呢?答案是肯定的。
如果用这种斐波那契散列法的话,那上面的图就变成这样了:
快速查找,删除的基本数据结构,通常需要总数据量可以放入内存。
hash函数选择,针对字符串,整数,排列,具体相应的hash方法。 碰撞处理,一种是open hashing,也称为拉链法;另一种就是closed hashing,也称开地址法,opened addressing。
- Note: in hash table with chaining, Insert is θ(1)
- insert new object x at front of list in A[h(x)]
- O( list length ) for Insert / Delete
- Point: performance depends on the choice of hash function
- Properties of a Good Has Function:
- should lead to good performance
- ie, should "spread data out"
- gold standard: completely random hashing
- should be easy to store / very fast to evaluated
- should lead to good performance
06:57
TODO
Google的爬虫每天需要抓取大量的网页。于是就有一个问题:每当爬虫分析出一个url的时候,是抓呢,还是不抓呢?如何知道这个url已经爬过了?
这个问题,归纳抽象后可以定义为:
给定一个集合S(注意,这里的集合是传统意义上的集合:元素彼此不同。本文不考虑multiset),给定一个元素e,需要判断e∈S 是否成立。(学术界一般称为membership问题)
都有哪些方案可以解决这个问题?
一种简单的想法是把url存储在一个哈希表中,每次去表里look up下判断是否存在。假如每个url占用40B,那么10亿条url将占用大概30多GB的内存!Can this be more space efficient ?
我们可不可以不存url本身?这样子所需空间就会大大减少了。于是我们想到一个很经典的做法:bitmap(位图)。将集合S中的url哈希到bitmap上,给定一个url,只需要将它hash,得到它在bitmap的下标,检查该位置是否为1即可。
这样做空间是省了,可是也产生了一个问题:由于冲突(碰撞),不是集合S中的元素也可能被哈希到值为1的位置上,导致误报。
给定一个元素e,如果实际上e∉S 而被判为 e∈S ,那么我们称e是false positive(伪正例。顺便说一句,false positive等的分析在machine learning的classification任务里评价model时非常重要)。
如何降低false positive的概率呢?Bloom Filter的想法是使用多个独立的哈希函数。
在传统的Bloom Filter中,我们有:
- 集合S:其大小为n。也就是说,集合中有n个不同元素。
- 可用内存B:B被当成位数组bitmap来使用,大小为m。(有m个bit)。
- 哈希函数:有k个独立的、均匀分布的哈希函数。
Bloom Filter的做法是:初始时,所有比特位都初始化为0。对于集合中的每个元素,利用k个哈希函数,对它哈希得到k个位置,将bitmap中的对应的k个位置置为1。
给定一个元素e,为了判断它是否是集合中的元素,也利用该k个函数得到k个位置,检查该k个位置是否都为1,如果是,认为e∈S ,否则认为e∉S 。
不难看出,如果e∈S ,那么Bloom Filter肯定会正确判断出e∈S ,但是它还是可能产生false positive。那么,如何分析false positive的概率呢?
既然Bloom Filter要靠多个哈希函数将集合映射到位数组中,那么应该选择几个哈希函数才能使元素查询时的错误率降到最低呢?这里有两个互斥的理由:如果哈希函数的个数多,那么在对一个不属于集合的元素进行查询时得到0的概率就大;但另一方面,如果哈希函数的个数少,那么位数组中的0就多。
当n和m固定时,选择k=(m/n)·ln2 附近的一个整数,将使false positive possibility最小 。 在这种情况下,最小错误率f等于 (1/2)ᴷ ≈ (0.6185)ᵐ⁄ⁿ. 要想保持错误率低,最好让位数组有一半还空着。
在错误率不大于є的情况下,m至少要等于n·log2(1/є)才能表示任意n个元素的集合。在哈希函数的个数取到最优时,要让错误率不超过є,m至少需要取到最小值的1.44倍。
工程实现时,我们需要k个哈希函数或者哈希函数值。如何构造和获得k个独立的哈希函数呢? 其实只需要两个独立的哈希函数hf1和hf2即可,也就是通过如下方式获得k个哈希函数值:
hash value = hf1(key) + i*hf2(key)
其中i=0、1、2…k-1
more space efficient
- can not store an associated object
- no deletion
- small false postive probability
- can actually make mistakes
- might say x has been inserted even though it hasn't been
- Original: early spellchecker
- Canonical: list of forbidden passwords
- Modern: network routers
- limit memory need to be super-fast
Ingredient:
- array of n bits
- k hash functions: h₁,h₂,...,hk
- k = small constant
Inserti(x):
for i=1,2,...,k:
# whether or not bit already set to 1
set A[hi(x)] = 1
Lookup(x):
return True <=> A[hi(x)] = 1 for every i=1,2,...,k
Note:
- no false negatives
- if x was inserted, lookup(x) guaranteed to success
- but false postive
- if all k hi(x) is already set to 1 by other insertions.
TODO