데이터 모델링 : 데이터베이스를 어떻게 만들고, 수정할 건지에 대한 계획을 세우는 작업
논리적 모델링 : 개념적 구조를 정하는 것
물리적 모델링 : 데이터베이스 구축에 필요한 걸 정하는 것
데이터 모델 : 데이터를 사용하려는 목적에 맞게 정리하고 체계화해놓은 모형
데이터 모델링 : 하기 4가지 요소를 파악해 데이터 모델을 만드는 과정
Entity(개체) : 데이터를 저장하려고 하는 대상 - row
Attribute(속성) : Entity에 대해서 저장하려고 하는 특징
Relationship(관계) : Entity들 사이 생기는 연결점
Constraiont(제약 조건) : 여러 데이터 요소들에 있는 규칙
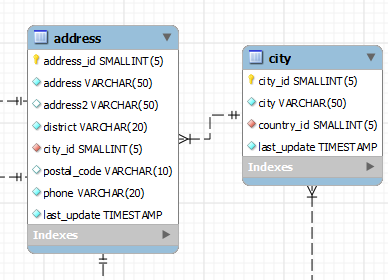
Relational Model : 데이터를 로우와 컬럼으로 정리한 테이블, 또는 표를 의미
Entity-Relationship 모델 (ERM)
ERM : Entity를 하나의 네모로, attribute을 네모 안에 문자열로, 그리고 relationship을 선으로 표현
개념 모델(경영인, 기획자) → 논리 모델(개발자 구체화) → 물리 모델(데이터베이스 구축) : 점점 구체적
중복되는 데이터가 생기지 않는다.
NULL이 생기지 않는다.
데이터가 늘어날 때 테이블 구조가 변하지 않는다.
비즈니스 룰 :특정 조직이 운영되기 위해 따라야 하는 정책, 절차, 원칙에 대한 간단 명료한 설명(모델링의 핵심 기반)
Entity, Relationship, Attribute 후보 찾기
비지니스 룰이 있을 때, Entity, Attribute, Relationship을 찾는 가장 기본적인 원칙
세가지 기본 원칙을 사용하여 비지니스 룰에서 ERM 초안을 만든다.
모든 명사는 Entity 후보
모든 동사는 Relationship 후보
하나의 "값"으로 표현할 수 있는 명사는 attribute의 후보
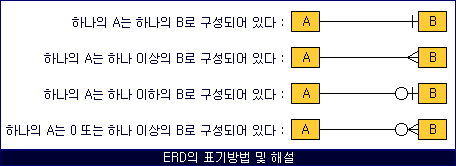
카디널리티는 M:N 관계: 두 entity type 사이 관계에서 한 종류의 entity가 다른 종류의 entity 몇 개에 대해서 관계를 맺을 수 있는지를 나타내는 개념
1:1 관계, 1:N 관계, M:N 관계
카디널리티 ERM(=ERD)
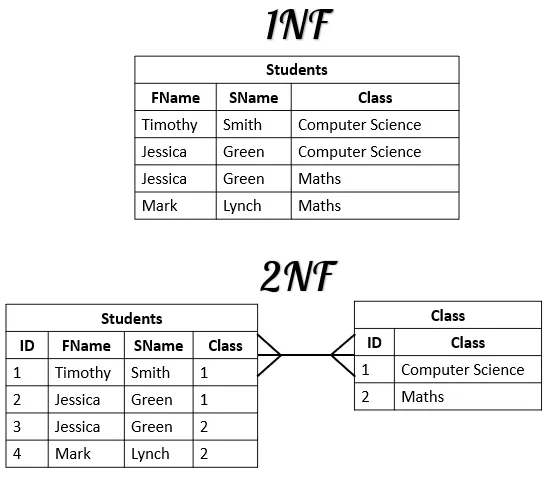
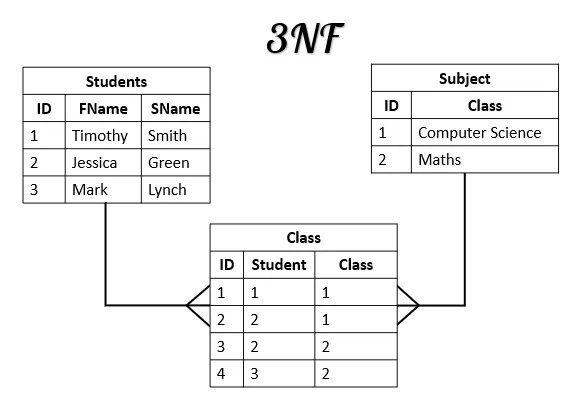
1NF : 모든 항목에 값이 있어야 한다. (NOT NULL & 중복되는 데이터가 없어야 한다 2NF : 개체의 속성이 한 식별자에 종속되어야 한다.
선형 탐색 : 가장 첫 원소부터 시작해서, 가장 마지막 원소까지 순서대로 하나씩 확인 (O(n))
이진 탐색 : 특정 순서대로 정렬돼 있을 때, 중간 원소를 처음부터 확인 O(lg(n))
Clustered 인덱스 : 데이터 자체를 특정 순서대로 저장하는 인덱스 CREATE CLUSTERED INDEX index_name ON table_name (column_name) Non-clustered 인덱스 : 로우들이 실제 저장된 순서 자체는 건들지 않고, 아예 다른 곳에 컬럼 값들의 순서를 저장하는 방법 CREATE INDEX index_name ON table_name (column_name)Composite 인덱스 : 여러 개의 컬럼에 대한 인덱스 CREATE INDEX index_name ON table_name (column_name_1, column_2, ...)SHOW INDEX FROM table_name;
DROP INDEX index_name ON table_name;