- Flask Web Demo URL
barumSpeakWeb
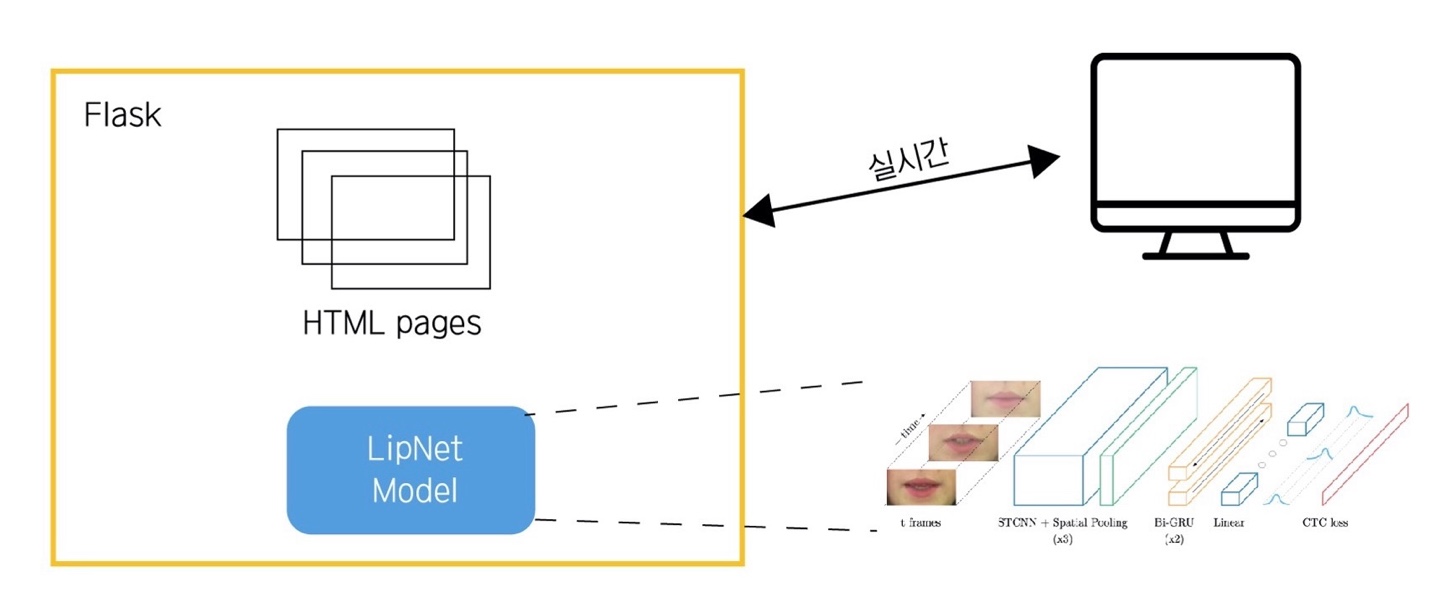
- 영어 발음을 조금 더 원어민에 가깝게 발음할 수 있도록 도움을 줄 수 있을 것을 기대
- 더 많은 데이터를 이용하여 학습할 수 있는 문장을 늘림에 따라 서비스의 확대 기대
- 음성인식 모델
- Library : Keras, Tensorflow, OpenCV, DLib
- Tool : PyCharm, TensorBoard
- Language : Python
- Hardware : Web Camera, Desktop(NVIDIA GeForce GTX 1070)
- Ubuntu 20.04.2 LTS(GNU/Linux 5.11.0-34-generic x86_64)
- CUDA V10.0.130
- cudNN 7.4.2
- Tensorflow 1.14.0
- keras 2.0.2
- python 3.6.13
- NVIDIA 드라이버 470.63.01
- Anaconda 4.10.1
- dlib 19.22.0
- ffmpeg 4.2.4-1
git clone https://github.com/barumSpeak/barumLipNet.git
cd LipNet/
pip install -e .
바탕화면에 align 폴더를 만든다. 그리고 각각
training/overlapped_speakers/s{i}/datasets 와
training/overlapped_speakers/datasets에 symbolic link를 건다.
필요한 준비물은 다음과 같다.
- 360 * 288 크기, 초당 25 frame의 동영상을 준비한다.
- 각 동영상에 해당하는 align 파일을 만든다.
- grid.txt에 학습시키는 모든 align 문장이 들어있다.
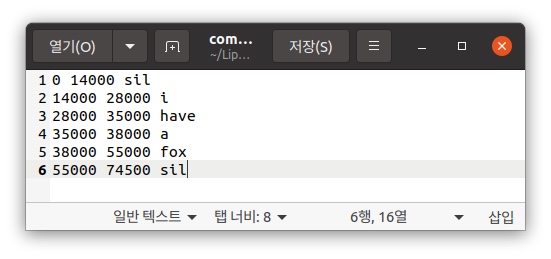
align은 각 동영상에 대한 정답 파일이다.
따라서, 동영상 1개당 1개의 align 파일이 존재해야 한다.
align 작성은 각 글자에 해당하는 frame을 적어준다.
(sil : 묵음, sp : 공백을 의미)
학습시킬 동영상 폴더를 지정해준다.
python train.py s{i}
학습으로 생성된 가중치 파일과 예측할 동영상을 지정해준다.
python predict.py [path to weight] [path to video]