By analyzing the user's sentences, it elicits emotions and presents various recommendations accordingly.
more information Blog
3달 여간의 교육을 받으며 파이썬부터 시작해서 ML, DL의 기초 OpenCV를 간단하게 다뤄보았다.
배운 것들을 토대로 모델을 만드는 프로젝트를 진행했다. (Jupyter notebook사용)
최대한 특이한걸 해보고 싶었지만 실력부족, 아이디어부족 등등.. 결국 뻔하디 뻔한 그런 주제로 들어온 것 같지만 그래도 3달여간 다른 3명의 팀원들과 함께 매일 저녁 6시부터 10시까지 함께 고생하며 완성한 첫 프로젝트인만큼 꽤나 기억에 많이 남을 것 같다.
간단하게 기록을 남긴다.
데이터셋은 3가지 종류를 사용했다. AI hub 개편 전에 있던 한국어 연속성대화셋, 단발성 대화셋을 합쳐서 하나
깃허브에 있는 네이버 영화리뷰, 네이버 쇼핑리뷰.
스팀 게임리뷰는 워낙 거기에 있는 단어들이 유니크한 것들이 많았기 때문에 정확도가 떨어지고 범용성이 적다고 생각하여 제외하여 이렇게 3개만 사용했다. 이것도 42만개정도 되는 양이니 아주 적은 양은 아니었다.
먼저 간단하게 사용한 모듈을 보자
import pandas as pd
import numpy as np
%matplotlib inline
import matplotlib.pyplot as plt
import re
import urllib.request
from konlpy.tag import Okt
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from collections import Counter
from sklearn.model_selection import train_test_split아!! python 3.8, Okt를 사용하기 위해 Jpype까지 설치해주었고 별도의 가상환경을 만들어서 그곳에서 개발하였다!!
개발환경 만드는 것도 헷갈려서 3일 걸렸다.
먼저 DS01파일을 보자.
data = pd.read_csv('DS01.csv')
data
사실 AI hub에 있는 대화세트는 7가지의 감정으로 분류가 되어있었는데, 처음에는 이것만으로 딥러닝을 진행하였으나 데이터량과 단어의 수에 비해 분류해야할 항목이 많다보니 정확도가 7%가 나와버리는...대참사가 일어났기 때문에 부정과 긍정으로 나누어서 진행했다.


data['발화'].nunique(), data['감정_int'].nunique()
data.isnull().sum()
data.drop_duplicates(subset = ["발화"], inplace = True)null값을 확인하고 중복값을 제거해주었다.
다음
urllib.request.urlretrieve("https://raw.githubusercontent.com/bab2min/corpus/master/sentiment/naver_shopping.txt", filename="ratings_total.txt")
shop_data = pd.read_table('ratings_total.txt', names=['ratings', '발화'])
print('전체 리뷰 개수 :',len(shop_data)) # 전체 리뷰 개수 출력전체 리뷰 개수 : 200000
ratings(별점)
발화 (리뷰내용)
데이터프레임꼴로 만들었다.
shop_data['감정_int'] = np.select([shop_data.ratings > 3], [1], default=0)
shop_data[4000:4005]리뷰점수 4,5점은 긍정. 1,2점은 부정. 3점은 중립이라 넣지 않았다.
이렇게 분류해서 감정_int라는 행으로 추가해주었다.
왜냐..이따 데이터를 합칠거니까
이렇게 하고 난 후에 뭐가 있는지 보자

shop_data['ratings'].nunique(), shop_data['발화'].nunique(), shop_data['감정_int'].nunique()(4, 199908, 2)
shop_data.drop_duplicates(subset=['발화'], inplace=True) # reviews 열에서 중복인 내용이 있다면 중복 제거
print('총 샘플의 수 :',len(shop_data))총 샘플의 수 : 199908
print(shop_data.isnull().values.any())False
null값이 있는지 확인했는데 없다.
이렇게 정리한 쇼핑데이터를 확인해보자.
shop_data = shop_data.drop(['ratings'], axis = 1)
shop_data
ds01과 같은 꼴로 잘 다듬었다.
이제 둘을 concat으로 붙여준다.
Data = pd.concat([data, shop_data])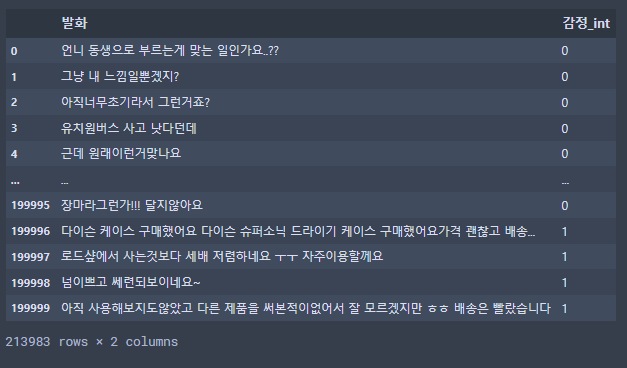
잘 붙었다. 데이터셋 21만여개 확보 완료
이제 같은 방식으로 영화리뷰도 붙여주면 된다.
영화리뷰는 깃에 train, test로 나뉘어있기 때문에 두번해줘야된다.
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt", filename="ratings_train.txt")
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt", filename="ratings_test.txt")
movie1_data = pd.read_table('ratings_train.txt')
movie2_data = pd.read_table('ratings_test.txt')
#쓸모없는 행 삭제
movie1_data = movie1_data.drop(['id'], axis=1)
movie2_data = movie2_data.drop(['id'], axis=1)
#행 이름 맞춰줌
movie1_data.columns=['발화', '감정_int']
movie2_data.columns=['발화', '감정_int']
#데이터 합체
Data = pd.concat([Data, movie1_data, movie2_data])이제 이렇게 합쳐진 데이터를 train, test셋으로 나눠주자.
보통 25%를 테스트셋으로 활용한다는데 우리는 학습데이터양을 늘리기 위해 10%만 떼어냈다.
train, test = train_test_split(Data, test_size=0.1, random_state=210617)
print('훈련용 리뷰의 개수 :', len(train))
print('테스트용 리뷰의 개수 :', len(test))훈련용 리뷰의 개수 : 372584 테스트용 리뷰의 개수 : 41399
학습이 편향되지 않기 위해서는 label이 균일하게 분포되어있는 지 확인해주어야 한다.
train['감정_int'].value_counts().plot(kind = 'bar')
print(train.groupby('감정_int').size().reset_index(name = 'count'))
다행히 거의 5:5로 아름답게 나누어져있다.
이제 한글을 제외한 나머지는 빈칸으로 바꿔주고 빈칸을 null로 바꾼다음 null값을 제거해버리자.
순수하게 한글만 남기도록 전처리한다.
train['발화'] = train['발화'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
test['발화'] = test['발화'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
train['발화'] = train['발화'].str.replace('^ +', "")
test['발화'] = test['발화'].str.replace('^ +', "")
train['발화'].replace('', np.nan, inplace = True)
test['발화'].replace('', np.nan, inplace = True)이 과정을 하였더니 train에서 1520개, test에서 166개가 제거 되었다.
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
okt = Okt()stopwords는 참 어렵다. 너무 빡빡하게 설정할 경우 단어들이 다 끊겨버리고 너무 느슨하게 해도 이상하게 분류가 된다.
다른 블로그들을 참고하면서 간단하게 설정하였다.
t_train = []
t_test = []
for sentence in train['발화']:
temp_X = okt.morphs(sentence, stem = True)
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
t_train.append(temp_X)
for sentence in test['발화']:
temp_X = okt.morphs(sentence, stem = True) # 토큰화
temp_X = [word for word in temp_X if not word in stopwords] # 불용어 제거
t_test.append(temp_X)문장을 단어단위로 쪼개어 리스트에 넣어주는 작업.
1시간 조금 안되게 돌아갔다.
tokenizer = Tokenizer()
tokenizer.fit_on_texts(t_train)
tokenizer.fit_on_texts(t_test)쪼개진 단어들에 숫자를 붙여주었다. 딥러닝을 위한 단계!
근데 매번 껐다켰다할때마다 이 사전을 다시 만드는 작업이 너무나도 힘들었다.
그런데 pickle이라는 함수가 객체를 저장할 수 있게 해준다.
import pickle
## Save pickle
with open("movieshopping.pickle","wb") as fw:
pickle.dump(tokenizer, fw)1시간 조금 안되게 걸려 만든 단어사전을 저장해주었다.
threshold = 1
total_cnt = len(tokenizer.word_index) # 단어의 수
rare_cnt = 0 # 등장 빈도수가 threshold보다 작은 단어의 개수를 카운트
total_freq = 0 # 훈련 데이터의 전체 단어 빈도수 총 합
rare_freq = 0 # 등장 빈도수가 threshold보다 작은 단어의 등장 빈도수의 총 합
# 단어와 빈도수의 쌍(pair)을 key와 value로 받는다.
for key, value in tokenizer.word_counts.items():
total_freq = total_freq + value
# 단어의 등장 빈도수가 threshold보다 작으면
if(value < threshold):
rare_cnt = rare_cnt + 1
rare_freq = rare_freq + value
print('단어 집합(vocabulary)의 크기 :',total_cnt)
print('등장 빈도가 %s번 이하인 희귀 단어의 수: %s'%(threshold - 1, rare_cnt))
print("단어 집합에서 희귀 단어의 비율:", (rare_cnt / total_cnt) * 100)
print("전체 등장 빈도에서 희귀 단어 등장 빈도 비율:", (rare_freq / total_freq) * 100)단어 집합(vocabulary)의 크기 : 75397
등장 빈도가 0번 이하인 희귀 단어의 수: 0
단어 집합에서 희귀 단어의 비율: 0.0
전체 등장 빈도에서 희귀 단어 등장 빈도 비율: 0.0
단어의 종류만 75397개...
여기서 2번 이하로 등장한 단어가 전체 단어에서 46%
3번 이하는 56%..
과감하게 전부다 학습에 사용하기로 하였다.
또한, 한두번 나온 단어가 그 문장의 감성을 표현할 수 있는 핵심단어일 수도 있다는 생각도 하였기 때문에 적게 나온 단어를 따로 제거하지 않았다.
t_train1 = tokenizer.texts_to_sequences(t_train)
t_test1 = tokenizer.texts_to_sequences(t_test)단어로 쪼개진 문장을 숫자로 바꿔주었다.
e_train = train['감정_int']
e_test = test['감정_int']정답데이터로 사용할 감정_int도 분류!
print('문장의 최대 길이 :',max(len(l) for l in t_train1))
print('문장의 평균 길이 :',sum(map(len, t_train1))/len(t_train1))
plt.hist([len(s) for s in t_train1], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()
데이터셋에서 문장의 최대 길이(단어의 수) = 69
평균길이는 11.46
분포도 그래프로 보여주었다.
def below_threshold_len(max_len, nested_list):
cnt = 0
for s in nested_list:
if(len(s) <= max_len):
cnt = cnt + 1
print('전체 샘플 중 길이가 %s 이하인 샘플의 비율: %s'%(max_len, (cnt / len(nested_list))*100))
max_len = 42
below_threshold_len(max_len, t_train1)전체 샘플 중 길이가 42 이하인 샘플의 비율: 99.18666321712696
길이를 길게 잡을 경우 학습에 시간이 오래걸리기 때문에 가장 데이터손실이 적으면서도 학습시간을 줄일 수 있도록 전체의 99.18%를 포함하도록 문장길이를 42로 설정하였다.
t_train2 = pad_sequences(t_train1, maxlen = max_len)
t_test2 = pad_sequences(t_test1, maxlen = max_len)문장길이를 모두 42로 패딩하였다.
from keras import models
from tensorflow.keras.layers import Embedding, Dense, LSTM, GRU, Dropout
from tensorflow.keras.models import Sequential
from tensorflow.keras.models import load_model
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint딥러닝에 사용할 모듈들
model = Sequential()
model.add(Embedding(vocab_size, 100))
model.add(LSTM(128, return_sequences = True))
model.add(Dropout(0.5))
model.add(GRU(128))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.summary()
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=4)
mc = ModelCheckpoint('bilstm.h5', monitor='val_acc', mode='max', verbose=1, save_best_only=True)
model.compile(optimizer='adam', loss='mse', metrics=['acc'])
history = model.fit(t_train2, e_train, epochs=15, callbacks=[es, mc], batch_size=6000, validation_split=0.2)optimizer, loss, layer들을 상당히 많이 바꿔가면서 진행하였다. 그 결과 대부분 잘 나왔지만
optimizer = 'adam', loss='mse'가 대체적으로 결과가 좋았고
LSTM과 GRU를 섞은 것이 결과도 가장 좋았다.
layer를 많이 쌓는다고 무조건 좋지 않았고 오히려 안좋았다.
loaded_model = load_model('bilstm.h5')
print("\n 테스트 정확도: %.4f" % (loaded_model.evaluate(t_test2, e_test)[1]))bilstm도 돌리다가 모델저장파일명을 안바꿨지만..
어쨌든 ...

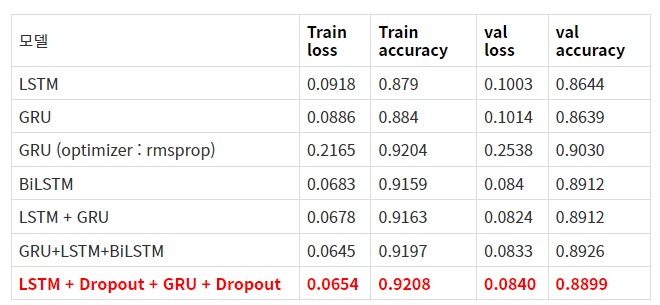
이러한 결과를 보여주었다.
어쨌든..
위에서 저장한 피클데이터, 모델파일을 통해 추천시스템을 만들었다.
솔직히 다이나믹한 추천시스템은 시간부족으로 만들지 못했다. 그냥 리스트에 다양한 항목을 넣고 감정점수에 따라서 아이템을 추천하는 방식으로 만들어보았다.
리스트는 설명에 필요한 정도로 다 삭제해주었다. 만약 추가하고자한다면 다른 항목을 넣어주면 된다.
from tensorflow.keras.models import load_model
import random
from konlpy.tag import Okt
import os
from tensorflow.keras.preprocessing.text import Tokenizer
import pickle
from tensorflow.keras.preprocessing.sequence import pad_sequences
with open("finalsenti.pickle","rb") as fr:
tokenizer = pickle.load(fr)
okt = Okt()
stopwords = ['도', '는', '다', '의', '가', '이', '은', '한', '에', '하', '고', '을', '를', '인', '듯', '과', '와', '네', '들', '듯', '지', '임', '게']
loaded_model = load_model('final.h5')
max_len = 42
global corpus
global avg_emo
global score
corpus = []
avg_emo = 0
heal = ['여수 밤바다', '파주 평화누리공원']
extreme= ['통영 어드벤처 타워', '제주도 스쿠버다이빙']
movie=['루카','콰이어트 플레이스']
#음악 (네이버 바이브 참고 1위~20위)
k_balad=['Timeless-SG워너비','추적이는 여름 비가 되어-장범준']
k_dance=['Butter-방탄소년단','Next Level-aespa']
k_hip=['마.피.아. In the morning-ITZY(있지)','봄날-방탄소년단']
trt=['이제 나만 믿어요-임영웅','별빛 같은 나의 사랑아-임영웅']
f_dance=['You-Regard, Troye Sivan, Tate McRae','Closer (Feat. Halsey)-The Chainsmokers'
newage=['River Flows In You-이루마','Letter From The Earth (지구에서 온 편지)-김광민']
korean = ["삼계탕", "삼겹살"]
western = ["스테이크", "파스타"]
asian = ["짜장면", "뿌팟퐁커리"]
spicy = ["떡볶이", "김치찜"]
dessert = ["와플", "마카롱"]
snack = ["닭강정", "양꼬치"]
coffee = ["아메리카노", "콜드브루"]
beverage = ["초코 라떼", "민트초코 라떼"]
motivation = ["{동기부여가 될만한 말들}"]
category = [heal,extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage]
f8 = [extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,korean,western,asian,spicy,dessert,snack,coffee,beverage]
f6 = [extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,korean,western,asian,spicy,dessert,snack,coffee,beverage]
f3 = [heal,extreme,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage, dessert]
f1 = [heal,movie,k_balad,k_dance,k_hip,trt,f_dance,newage,korean,western,asian,spicy,dessert,snack,coffee,beverage, dessert]
f0 = [heal,movie,k_balad,k_dance,k_hip,f_dance,newage,korean,western,asian,spicy,spicy,dessert,snack,snack,coffee,beverage]
def recomend_sys(new_sentence):
global score
global timecheck
global corpus
global score
global avg_emo
new_sentence = okt.morphs(new_sentence, stem=True) # 토큰화
new_sentence = [word for word in new_sentence if not word in stopwords] # 불용어 제거
encoded = tokenizer.texts_to_sequences([new_sentence]) # 정수 인코딩
pad_new = pad_sequences(encoded, maxlen = max_len) # 패딩
score = float(loaded_model.predict(pad_new)) # 예측
corpus.append(score)
if len(corpus) >= 5:
avg_emo = sum(corpus)/len(corpus)
if(avg_emo > 0.8):
pick = random.choice(f8)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("오늘처럼 좋은 날엔 {0} 어떠신가요?\n".format(random.choice(pick)))
corpus=[]
elif(avg_emo > 0.6):
pick = random.choice(f6)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("좋은 일있으신가요? 오늘 {0} 어떠세요?\n".format(random.choice(pick)))
corpus=[]
elif(avg_emo > 0.4) :
pick = random.choice(category)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("오늘같은 날에는 {0} 어때요? 기분이 좋아질거에요!!\n".format(random.choice(pick)))
corpus=[]
elif(avg_emo > 0.3) :
pick = random.choice(f3)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("꿀꿀한 오늘 {0} 추천해요.\n".format(random.choice(pick)))
corpus=[]
elif(avg_emo > 0.18) :
pick = random.choice(f1)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("오늘 {0} 어떠세요? 안좋은 기분을 환기시켜줄 거에요.\n".format(random.choice(pick)))
corpus=[]
else:
pick = random.choice(f0)
if pick == motivation: # | pick == rest:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("당신을 위한 한마디 : {1}\n".format(random.choice(pick)))
corpus=[]
else:
print("기분 점수 : {0:.2f}".format(avg_emo*100))
print("오늘 안좋은 일이 있으셨나요. 오늘같은 날 {0} 어떠세요?\n".format(random.choice(pick)))
corpus=[]
else:
print('감정 분석까지 {0}개의 문장이 남았어요!'.format(5-len(corpus)))5개의 문장이 들어갔을 때, 평균점수로 추천하도록 만들었다.
아래 이미지 클릭시 유투브로 이동하여 재생됩니다.
구현되는 모습을 동영상으로 촬영하였다.
이상...기타 프론트엔드로 이쁘게 구현하거나 좀더 멋드러지게 만들지는 못했지만 NLP를 직접 분석하고 RNN에 대해서 많은 공부를 할 수 있었던 값지고 소중한 경험이었다.