Releases: PennyLaneAI/catalyst
Catalyst v0.14.0
Release 0.14.0 (current release)
New features since last release
-
Programs compiled with
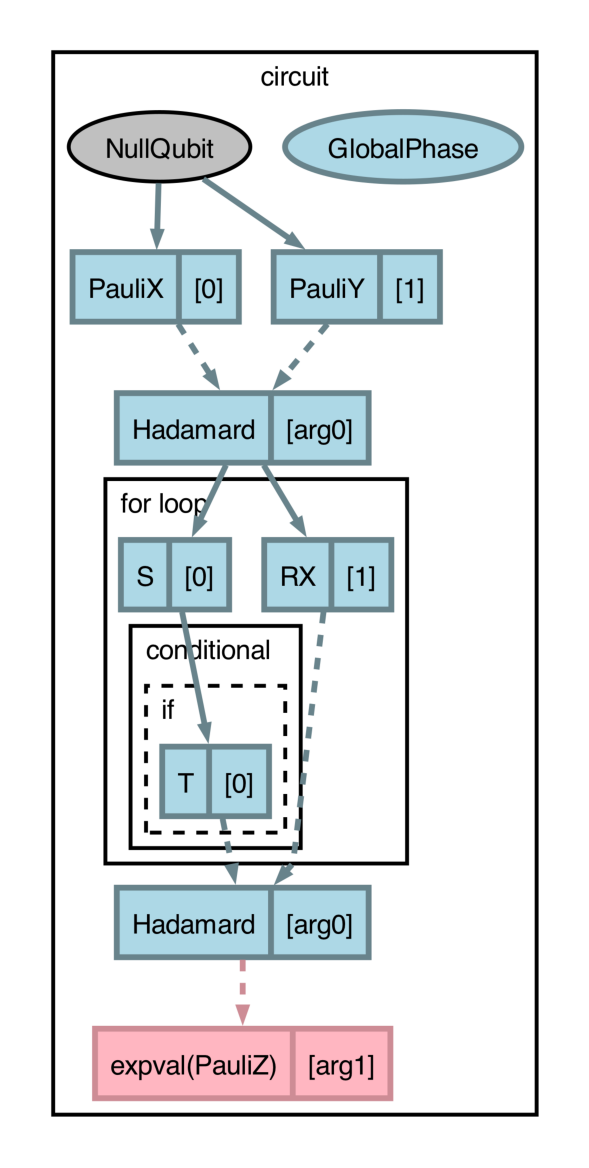
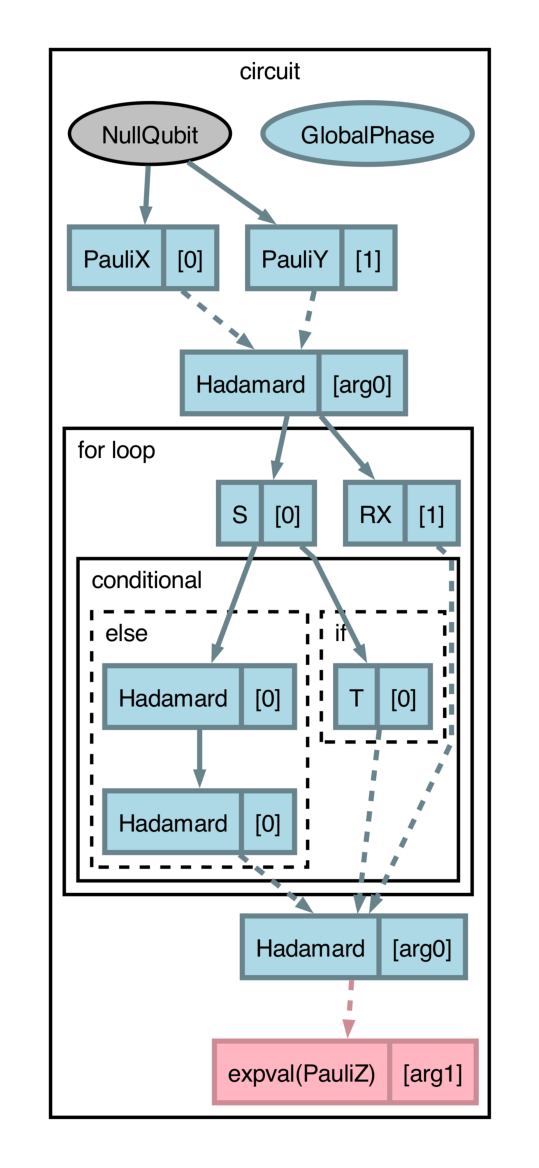
qjitcan now be visualized withdraw_graph, allowing for sequentially analyzing impacts of compilation passes on structured and dynamic programs. (#2213) (#2214) (#2218) (#2229) (#2231) (#2234) (#2243) (#2246) (#2260) (#2285) (#2287) (#2298) (#2290) (#2340) (#2357) (#2309) (#2363)Consider the following circuit:
import pennylane as qml import catalyst @qml.qjit(autograph=True) @catalyst.passes.cancel_inverses @catalyst.passes.merge_rotations @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(x, y): qml.X(0) qml.Y(1) qml.H(x) for i in range(3): qml.S(0) qml.RX(0.1, wires=1) qml.RX(0.2, wires=1) if i == 3: qml.T(0) else: qml.H(0) qml.H(0) qml.H(x) return qml.expval(qml.Z(y))
The circuit structure (
forloop and conditional branches) along with the dynamicism (variablesxandy) can be succinctly represented withdraw_graph.>>> x, y = 1, 0 >>> fig, ax = catalyst.draw_graph(circuit)(x, y) >>> fig.savefig('path_to_file.png', dpi=300, bbox_inches="tight")
The output of
draw_graphis amatplotlib.figure.Figure, allowing for natural manipulations like increasing resolution, size, etc.By default, all compilation passes specified will be applied and visualized. However,
draw_graphcan be used with thelevelargument to inspect compilation pass impacts, where thelevelvalue denotes the cumulative set of applied compilation transforms (in the order they appear) to be applied and visualized. Withlevel=1, drawing the above circuit will apply themerge_rotationtransform only:>>> fig, ax = catalyst.draw_graph(circuit, level=1)(x, y) >>> fig.savefig('path_to_file.png', dpi=300, bbox_inches="tight")
The
draw_graphfunction visualizes aqjit-compiled QNode in a similar manner as view-op-graph does in MLIR, which leverages Graphviz to show data-flow in the compiled IR. As such, use ofdraw_graphrequires installation of Graphviz and the pydot software package. Please consult the links provided for installation instructions. Additionally, it is recommended to usedraw_graphwith PennyLane's program capture enabled (seeqml.capture.enable). -
The Ross-Sellinger Gridsynth algorithm for discretizing
RZandPhaseShiftgates has been added to Catalyst withgridsynth, allowing for Clifford+T workloads to benefit more from just-in-time compilation withqjit. (#2140) (#2166) (#2292)The
gridsynthcompilation pass discretizesRZandPhaseShiftgates to either the Clifford+T basis or to the Pauli-product-rotation (PPR) basis, complimenting existing transforms likepennylane.transforms.clifford_t_decompositionand Pauli-based-computation compilation passes. This pass is also callable from the PennyLane frontend viapennylane.transforms.gridsynth. -
A new statevector simulator called
lightning.amdgpuhas been added for optimized performance on AMD GPUs, and is compatible with Catalyst. (#2283)The
lightning.amdgpudevice is a specific instantiation of thelightning.kokkosbackend, supporting the same features and operations aslightning.kokkos, with pre-compiled wheels forlightning.amdgpuavailable on PyPI for easy installation to use on MI300 series AMD GPUs.This device can be used within
qjit'd workflows exactly as other devices compatible with Catalyst:@qml.qjit @qml.qnode(qml.device('lightning.amdgpu', wires=2)) def circuit(): qml.Hadamard(0) return qml.state()
>>> circuit() [0.70710678+0.j 0. +0.j 0.70710678+0.j 0. +0.j]
See the Lightning-AMDGPU documentation for more details and installation instructions.
-
A new control-flow operation has been added called
catalyst.switch, which is aqjit-compatible index-switch style control flow decorator. Switches allow for more efficient, non-recursive lowering of distinct cases and can simplify control flow among multiple branches. (#2171)from catalyst import qjit, switch @qjit @qml.qnode(qml.device("lightning.qubit", wires=1)) def my_circuit(i, theta): @switch(i) # initialize a switch on variable i def my_switch(angle): # this is the default branch (required) qml.RX(angle, wires=0) @my_switch.branch(1) # create a branch with case i = 1 def my_branch(angle): qml.RY(angle, wires=0) @my_switch.branch(4) # create a branch with case i = 4 def my_branch_4(angle): qml.H(0) my_switch(theta) # must invoke the switch return qml.probs()
-
Catalyst can now compile circuits that are directly expressed in terms of Pauli product rotation (PPR) and Pauli product measurement (PPM) operations:
PauliRotandpauli_measure, respectively. This is only supported with PennyLane program capture enabled (pennylane.capture.enable). This support enables research and development spurred from A Game of Surface Codes (arXiv1808.02892). (#2145) (#2233) (#2284) (#2296) (#2336) (#2360)PauliRotandpauli_measurecan be manipulated with Catalyst's existing passes for PPR-PPM compilation only when PennyLane program capture is enabled. This includespennylane.transforms.to_ppr,pennylane.transforms.commute_ppr,pennylane.transforms.merge_ppr_ppm,pennylane.transforms.ppr_to_ppm,pennylane.transforms.reduce_t_depth,pennylane.transforms.decompose_arbitrary_pprandpennylane.transforms.ppm_compilation. Note that these transforms must be called from the PennyLane frontend, not fromcatalyst.passes.import pennylane as qml import jax.numpy as jnp import catalyst qml.capture.enable() pipelines=[('pip', ["quantum-compilation-stage"])] @qml.qjit(pipelines=pipelines, target="mlir") @qml.transforms.ppm_compilation @qml.qnode(qml.device("null.qubit", wires=4)) def circuit(): # equivalent to a Hadamard gate qml.PauliRot(jnp.pi / 2, pauli_word="Z", wires=0) qml.PauliRot(jnp.pi / 2, pauli_word="X", wires=0) qml.PauliRot(jnp.pi / 2, pauli_word="Z", wires=0) # equivalent to a CNOT gate qml.PauliRot(jnp.pi / 2, pauli_word="ZX", wires=[0, 1]) qml.PauliRot(-jnp.pi / 2, pauli_word="Z", wires=[0]) qml.PauliRot(-jnp.pi / 2, pauli_word="X", wires=[1]) # equivalent to a T gate qml.PauliRot(jnp.pi / 4, pauli_word="Z", wires=0) ppm = qml.pauli_measure(pauli_word="ZXY", wires=[1, 2, 0]) return
>>> print(circuit.mlir_opt) ... %3 = qec.fabricate magic : !quantum.bit %mres, %out_qubits:2 = qec.ppm ["X", "Z"] %1, %3 : i1, !quantum.bit, !quantum.bit %mres_0, %out_qubits_1 = qec.select.ppm(%mres, ["Y"], ["X"]) %out_qubits#1 : i1, !quantum.bit %4 = qec.ppr ["X"](2) %out_qubits#0 cond(%mres_0) : !quantum.bit quantum.dealloc_qb %out_qubits_1 : !quantum.bit %5 = quantum.extract %0[ 2] : !quantum.reg -> !quantum.bit %mres_2, %out_qubits_3:3 = qec.ppm ["Z", "Y", "X"] %4, %2, %5 : i1, !quantum.bit, !quantum.bit, !quantum.bit ... -
A new transform called
decompose_arbitrary_pprpass has been added, which decomposes abitrary-angle Pauli-product rotations (PPRs) as outlined in Figure 13(d) from arXiv:2211.15465. (#2304) (#2354)An arbitrary-angle PPR is defined as a PPR whose angle of rotation is not $\tfrac{\pi}{2...
Catalyst v0.13.0
New features since last release
-
Catalyst now supports
qml.specs, meaning that users can use theqml.specsfunction to track the exact resources of programs compiled with~.qjit! This new feature is currently only supported when usinglevel="device". (#2033) (#2055)This is made possible by leveraging resource-tracking capabilities using the
null.qubitdevice under the hood, which gathers circuit information via mock execution. This makes getting exact resources from large circuits extremely performant. For example, the circuit below has 100 qubits and its device-level resources can be calculated in around 1 minute!from functools import partial gateset = {qml.H, qml.S, qml.CNOT, qml.T, qml.RX, qml.RY, qml.RZ} @qml.qjit @partial(qml.transforms.decompose, gate_set=gateset) @qml.qnode(qml.device("null.qubit", wires=100)) def circuit(): qml.QFT(wires=range(100)) qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) qml.OutAdder(x_wires=range(10), y_wires=range(10, 20), output_wires=range(20, 31)) return qml.expval(qml.Z(0) @ qml.Z(1)) circ_specs = qml.specs(circuit, level="device")()
>>> print(circ_specs['resources']) num_wires: 100 num_gates: 138134 depth: 90142 shots: Shots(total=None) gate_types: {'CNOT': 55313, 'RZ': 82698, 'Hadamard': 123} gate_sizes: {2: 55313, 1: 82821}
Note that there are certain limitations to
specssupport. For example,whileloops might not terminate when executing on thenull.qubitdevice due to the quantum execution being mocked out. -
The graph-based decomposition system, enabled with the global toggle
qml.decomposition.enable_graph(), is now supported with Catalyst with PennyLane program capture enabled (qml.capture.enable()). This provides~.qjitcompatibility to defining custom decomposition rules and access to the many decomposition rules for templates and operators in PennyLane that have been added over the past few release cycles. (#1820) (#2099) (#2091) (#2029) (#2001) (#2115)qml.decomposition.enable_graph() qml.capture.enable() @qml.register_resources({qml.H: 2, qml.CZ: 1}) def my_cnot1(wires): qml.H(wires=wires[1]) qml.CZ(wires=wires) qml.H(wires=wires[1]) @qml.qjit @partial( qml.transforms.decompose, gate_set={"H", "CZ", "GlobalPhase"}, alt_decomps={qml.CNOT: [my_cnot1]}, ) @qml.qnode(qml.device("lightning.qubit", wires=2)) def circuit(): qml.H(0) qml.CNOT(wires=[0, 1]) return qml.state()
>>> circuit() Array([0.70710678+0.j, 0. +0.j, 0. +0.j, 0.70710678+0.j], dtype=complex128)
Similar to PennyLane's behaviour, this feature will fall back to the old system whenever the graph cannot find decomposition rules for all unsupported operators in the program, and a
UserWarningis raised.For more information, please consult the PennyLane decomposition module.
-
Catalyst now supports dynamic wire allocation with
qml.allocate()andqml.deallocate()when program capture is enabled, unlockingqjit-able applications like decompositions of gates that require temporary auxiliary wires and logical patterns in subroutines that benefit from having dynamic wire management. (#2002) (#2075)Two new functions,
qml.allocate()andqml.deallocate(), have been added to PennyLane to support dynamic wire allocation. With Catalyst, these features can be accessed onlightning.qubit,lightning.kokkos, andlightning.gpu.Dynamic wire allocation refers to the allocation of wires in the middle of a circuit, as opposed to the static allocation during device initialization. For example:
qml.capture.enable() @qjit @qml.qnode(qml.device("lightning.qubit", wires=2)) # 2 initial qubits def circuit(): qml.X(0) # |10> with qml.allocate(1) as q: # |10> and |0>, 1 dynamically allocated qubit qml.X(q[0]) # |10> and |1> qml.CNOT(wires=[q[0], 1]) # |11> and |1> return qml.probs(wires=[0, 1])
>>> print(circuit()) [0. 0. 0. 1.]In the above program, 2 qubits are allocated during device initialization, and 1 additional qubit is allocated inside the circuit with
qml.allocate(1).For more information on what
qml.allocate()andqml.deallocate()do, please consult the PennyLane v0.43 release notes.There are some notable differences between the behaviour of these features with
qjitversus without. For details, please see the relevant sections in the Catalyst sharp bits page. -
A new quantum compilation pass called
~.passes.reduce_t_depthhas been added, which reduces the depth and count of non-Clifford Pauli product rotations (PPRs) in circuits. This compilation pass works by commuting non-Clifford PPRs (those requiring aT-state to implement) in adjacent layers and merging compatible ones. More details can be found in Figure 6 of A Game of Surface Codes. (#1975) (#2048) (#2085)The impact of the
~.passes.reduce_t_depthpass can be measured using~.passes.ppm_specsto compare the circuit depth before and after applying the pass. Consider the following circuit:import pennylane as qml from catalyst import qjit, measure pips = [("pipe", ["enforce-runtime-invariants-pipeline"])] no_reduce_T = { "to_ppr": {}, "commute_ppr": {}, "merge_ppr_ppm": {}, } reduce_T = { "to_ppr": {}, "commute_ppr": {}, "merge_ppr_ppm": {}, "reduce_t_depth": {} } for pipeline in [reduce_T, no_reduce_T]: @qjit(pipelines=pips, target="mlir", circuit_transform_pipeline=pipeline) @qml.qnode(qml.device("null.qubit", wires=3)) def circuit(): n = 3 for i in range(n): qml.H(wires=i) qml.S(wires=i) qml.CNOT(wires=[i, (i + 1) % n]) qml.T(wires=i) qml.H(wires=i) qml.T(wires=i) return [measure(wires=i) for i in range(n)] print(ppm_specs(circuit))
{'circuit_0': {'depth_pi8_ppr': 3, 'depth_ppm': 1, 'logical_qubits': 3, 'max_weight_pi8': 3, 'num_of_ppm': 3, 'pi8_ppr': 6}} {'circuit_0': {'depth_pi8_ppr': 4, 'depth_ppm': 1, 'logical_qubits': 3, 'max_weight_pi8': 3, 'num_of_ppm': 3, 'pi8_ppr': 6}}After performing the
~.passes.to_ppr,~.passes.commute_ppr, and~.passes.merge_ppr_ppmpasses, the circuit contains a depth of four of non-Clifford PPRs (depth_pi8_ppr). Subsequently applying the~.passes.reduce_t_depthpass will move PPRs around via commutation, resulting in a circuit with a smaller PPR depth of three. -
Catalyst now handles more types of hybrid workflows by supporting returning classical and MCM values with the dynamic one-shot MCM method. (#2004) (#2090)
For example, the code below will generate 10 values, with an equal probability of 42 and 43 appearing.
import pennylane as qml from catalyst import qjit, measure @qjit(autograph=True) @qml.qnode(qml.device("lightning.qubit", wires=1), mcm_method="one-shot", shots=10) def circuit(): qml.Hadamard(wires=0) m = measure(0) if m: return 42, m else: return 43, m
>>> print(circuit()) (Array([42, 43, 42, 42, 43, 42, 42, 43, 42, 42], dtype=int64), Array([ True, False, True, True, False, True, True, False, True, True], dtype=bool)) -
The default mid-circuit measurement method in catalyst has been changed from
"single-branch-statistics"to"one-shot"when mcms are present in the program, which provides a more sensible experience overall when using finite shots. [#2017] [#2019]The main differentiator is that
"one-shot"explores all branches of the decision tree when probabilistic elements are present in the program, such as mid-circuit measurements, device noise, or other sources of randomness. The cost is that simulation / device execution is repeatedshotsnumber of times. -
Catalyst now provides native support for
qml.SingleExcitation,qml.DoubleExcitation, andqml.PCPhaseon compatible devices (e.g., Lightning simulators). This enhancement avoids unnecessary gate decomposition, leading to reduced compilation time and improved...
Catalyst v0.12.0
New features since last release
-
A new compilation pass called
passes.ppm_compilationhas been added to Catalyst to transform Clifford+T gates into Pauli Product Measurements (PPMs) using just one transform, allowing for exploring representations of programs in a new paradigm in logical quantum compilation. (#1750)Based on arXiv:1808.02892, this new compilation pass simplifies circuit transformations and optimizations by combining multiple sub-passes into a single compilation pass, where Clifford+T gates are compiled down to Pauli product rotations (PPRs,
$\exp(-iP_{{x, y, z}} \theta)$ ) and PPMs:-
passes.to_ppr: converts Clifford+T gates into PPRs. -passes.commute_ppr: commutes PPRs past non-Clifford PPRs. -passes.merge_ppr_ppm: merges Clifford PPRs into PPMs. -passes.ppr_to_ppm: decomposes both non-Clifford PPRs ($\theta = \tfrac{\pi}{8}$ ), consuming a magic state in the process, and Clifford PPRs ($\theta = \tfrac{\pi}{4}$ ) into PPMs. (#1664)
import pennylane as qml from catalyst.passes import ppm_compilation pipeline = [("pipe", ["enforce-runtime-invariants-pipeline"])] @qml.qjit(pipelines=pipeline, target="mlir") @ppm_compilation(decompose_method="clifford-corrected", avoid_y_measure=True, max_pauli_size=2) @qml.qnode(qml.device("null.qubit", wires=2)) def circuit(): qml.CNOT([0, 1]) qml.CNOT([1, 0]) qml.adjoint(qml.T)(0) qml.T(1) return catalyst.measure(0), catalyst.measure(1)
>>> print(circuit.mlir_opt) ... %m, %out:3 = qec.ppm ["Z", "Z", "Z"] %1, %2, %4 : !quantum.bit, !quantum.bit, !quantum.bit %m_0, %out_1:2 = qec.ppm ["Z", "Y"] %3, %out#2 : !quantum.bit, !quantum.bit %m_2, %out_3 = qec.ppm ["X"] %out_1#1 : !quantum.bit %m_4, %out_5 = qec.select.ppm(%m, ["X"], ["Z"]) %out_1#0 : !quantum.bit %5 = arith.xori %m_0, %m_2 : i1 %6:2 = qec.ppr ["Z", "Z"](2) %out#0, %out#1 cond(%5) : !quantum.bit, !quantum.bit quantum.dealloc_qb %out_5 : !quantum.bit quantum.dealloc_qb %out_3 : !quantum.bit %7 = quantum.alloc_qb : !quantum.bit %8 = qec.fabricate magic_conj : !quantum.bit %m_6, %out_7:2 = qec.ppm ["Z", "Z"] %6#1, %8 : !quantum.bit, !quantum.bit %m_8, %out_9:2 = qec.ppm ["Z", "Y"] %7, %out_7#1 : !quantum.bit, !quantum.bit %m_10, %out_11 = qec.ppm ["X"] %out_9#1 : !quantum.bit %m_12, %out_13 = qec.select.ppm(%m_6, ["X"], ["Z"]) %out_9#0 : !quantum.bit %9 = arith.xori %m_8, %m_10 : i1 %10 = qec.ppr ["Z"](2) %out_7#0 cond(%9) : !quantum.bit quantum.dealloc_qb %out_13 : !quantum.bit quantum.dealloc_qb %out_11 : !quantum.bit %m_14, %out_15:2 = qec.ppm ["Z", "Z"] %6#0, %10 : !quantum.bit, !quantum.bit %from_elements = tensor.from_elements %m_14 : tensor<i1> %m_16, %out_17 = qec.ppm ["Z"] %out_15#1 : !quantum.bit ... -
-
A new function called
passes.get_ppm_specshas been added for acquiring statistics after PPM compilation. (#1794)After compiling a workflow with any combination of
passes.to_ppr,passes.commute_ppr,passes.merge_ppr_ppm,passes.ppr_to_ppm, orpasses.ppm_compilation, usepasses.get_ppm_specsto track useful statistics of the compiled workflow, including:-
num_pi4_gates: number of Clifford PPRs -num_pi8_gates: number of non-Clifford PPRs -num_pi2_gates: number of classical PPRs -max_weight_pi4: maximum weight of Clifford PPRs -max_weight_pi8: maximum weight of non-Clifford PPRs -max_weight_pi2: maximum weight of classical PPRs -num_logical_qubits: number of logical qubits -num_of_ppm: number of PPMs
from catalyst.passes import get_ppm_specs, to_ppr, merge_ppr_ppm, commute_ppr pipe = [("pipe", ["enforce-runtime-invariants-pipeline"])] @qjit(pipelines=pipe, target="mlir", autograph=True) def test_convert_clifford_to_ppr_workflow(): device = qml.device("lightning.qubit", wires=2) @merge_ppr_ppm @commute_ppr(max_pauli_size=2) @to_ppr @qml.qnode(device) def f(): qml.CNOT([0, 2]) qml.T(0) return measure(0), measure(1) @merge_ppr_ppm(max_pauli_size=1) @commute_ppr @to_ppr @qml.qnode(device) def g(): qml.CNOT([0, 2]) qml.T(0) qml.T(1) qml.CNOT([0, 1]) for i in range(10): qml.Hadamard(0) return measure(0), measure(1) return f(), g()
>>> ppm_specs = get_ppm_specs(test_convert_clifford_to_ppr_workflow) >>> print(ppm_specs) { 'f_0': {'max_weight_pi8': 1, 'num_logical_qubits': 2, 'num_of_ppm': 2, 'num_pi8_gates': 1}, 'g_0': {'max_weight_pi4': 2, 'max_weight_pi8': 1, 'num_logical_qubits': 2, 'num_of_ppm': 2, 'num_pi4_gates': 36, 'num_pi8_gates': 2} }
-
-
Catalyst now supports
qml.Snapshot, which captures quantum states at any point in a circuit. (#1741)For example, the code below is capturing two snapshot'd states, all within a qjit'd circuit:
NUM_QUBITS = 2 dev = qml.device("lightning.qubit", wires=NUM_QUBITS) @qjit @qml.qnode(dev) def circuit(): wires = list(range(NUM_QUBITS)) qml.Snapshot("Initial state") for wire in wires: qml.Hadamard(wires=wire) qml.Snapshot("After applying Hadamard gates") return qml.probs() results = circuit() snapshots, *results = circuit() >>> print(snapshots) [Array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=complex128), Array([0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j], dtype=complex128)] >>> print(results) Array([0.25, 0.25, 0.25, 0.25], dtype=float64)
>>> print(results) ([Array([1.+0.j, 0.+0.j, 0.+0.j, 0.+0.j], dtype=complex128), Array([0.5+0.j, 0.5+0.j, 0.5+0.j, 0.5+0.j], dtype=complex128)], Array([0.25, 0.25, 0.25, 0.25], dtype=float64)) -
Catalyst now supports automatic qubit management, meaning that the number of wires does not need to be specified during device initialization. (#1788)
@qjit def workflow(): dev = qml.device("lightning.qubit") # no wires here! @qml.qnode(dev) def circuit(): qml.PauliX(wires=2) return qml.probs() return circuit() print(workflow())
[0. 1. 0. 0. 0. 0. 0. 0.]
While this feature adds a lot of convenience, it may also reduce performance on devices where reallocating resources can be expensive, such as statevector simulators.
-
Two new peephole-optimization compilation passes called
passes.disentangle_cnotandpasses.disentangle_swaphave been added. Each compilation pass replacesSWAPorCNOTinstructions with other equivalent elementary gates. (#1823)As an example,
passes.disentangle_cnotapplied to the circuit below will replace theCNOTgate with anXgate.dev = qml.device("lightning.qubit", wires=2) @qml.qjit(keep_intermediate=True) @catalyst.passes.disentangle_cnot @qml.qnode(dev) def circuit(): # first qubit in |1> qml.X(0) # second qubit in |0> # current state : |10> qml.CNOT([0,1]) # state after CNOT : |11> return qml.state()
>>> from catalyst.debug import get_compilation_stage >>> print(get_compilation_stage(circuit, stage="QuantumCompilationPass")) ... %out_qubits = quantum.custom "PauliX"() %1 : !quantum.bit %2 = quantum.extract %0[ 1] : !quantum.reg -> !quantum.bit %out_qubits_0 = quantum.custom "PauliX"() %2 : !quantum.bit ...
Improvements 🛠
-
The
qml.measureoperation for mid-circuit measurements can now be used in qjit-compiled circuits with program capture enabled. (#1766)Note that the simulation behaviour of mid-circuit measurements can differ between PennyLane and Catalyst, depending on the chosen
mcm_method. Please see the
Functionality differences from PennyLane section in the :doc:sharp bits and debugging tips page <sharp_bits>for additional information. -
The behaviour of measurement processes executed on
null.qubitwith qjit is now more consistent with their behaviour onnull.qubitwithout qjit. (#1598)Previously, measurement processes like
qml.sample,qml.counts,qml.probs, etc., returned values from uninitialized memory when executed onnull.qubitwith qjit. This change ensures that measurement processes onnull.qubitalways return the value 0 or the result corresponding to the '0' state, depending on the context. -
The package name of the Catalyst distribution has been updated to be consistent with PyPA standards, from
PennyLane-Catalysttopennylane_catalyst. This change is not expected to affect users as tools in the Python ecosystem (e.g.pip) already handle both versions through normalization. (#1817) -
The
passes.commute_pprandpasses.merge_ppr_ppmpasses now accept an optionalmax_pauli_sizeargument, which limits the size of the Pauli strings generated by the passes through commutation or absorption rules. (#1719) -
The
passes.to_pprpass is now more efficient by adding support for the direct conversion of...
Catalyst v0.11.0-post1
Users are now redirected to pennylane.ai/search with the doc content type selected and the associated project and version filters selected when using the search bar.
Catalyst v0.11.0
New features since last release
-
A novel optimization technique is implemented in Catalyst that performs quantum peephole optimizations across loop boundaries. The technique has been added to the existing optimizations
cancel_inversesandmerge_rotationsto increase their effectiveness in structured programs. (#1476)A frequently occurring pattern is operations at the beginning and end of a loop that cancel each other out. With loop boundary analysis, the
cancel_inversesoptimization can eliminate these redundant operations and thus reduce quantum circuit depth.For example,
dev = qml.device("lightning.qubit", wires=2) @qml.qjit @catalyst.passes.cancel_inverses @qml.qnode(dev) def circuit(): for i in range(3): qml.Hadamard(0) qml.CNOT([0, 1]) qml.Hadamard(0) return qml.expval(qml.Z(0))
Here, the Hadamard gate pairs which are consecutive across two iterations are eliminated, leaving behind only two unpaired Hadamard gates, from the first and last iteration, without unrolling the for loop. For more details on loop-boundary optimization, see the PennyLane Compilation entry.
-
A new intermediate representation and compilation framework has been added to Catalyst to describe and manipulate programs in the Pauli product measurement (PPM) representation. As part of this framework, three new passes are now available to convert Clifford + T gates to Pauli product measurements as described in arXiv:1808.02892. (#1499) (#1551) (#1563) (#1564) (#1577)
Note that programs in the PPM representation cannot yet be executed on available backends. The passes currently exist for analysis, but PPM programs may become executable in the future when a suitable backend is available.
The following new compilation passes can be accessed from the
catalyst.passesmodule or incatalyst.pipeline:-
catalyst.passes.to_ppr: Clifford + T gates are converted into Pauli product rotations (PPRs) ($\exp{iP \theta}$ , where$P$ is a tensor product of Pauli operators):-
Hgate → 3 rotations with$P_1 = Z, P_2 = X, P_3 = Z$ and$\theta = \tfrac{\pi}{4}$ -
Sgate → 1 rotation with$P = Z$ and$\theta = \tfrac{\pi}{4}$ -
Tgate → 1 rotation with$P = Z$ and$\theta = \tfrac{\pi}{8}$ -
CNOTgate → 3 rotations with$P_1 = (Z \otimes X), P_2 = (-Z \otimes \mathbb{1}), P_3 = (-\mathbb{1} \otimes X)$ and$\theta = \tfrac{\pi}{4}$
-
-
catalyst.passes.commute_ppr: Commute Clifford PPR operations (PPRs with$\theta = \tfrac{\pi}{4}$ ) to the end of the circuit, past non-Clifford PPRs (PPRs with$\theta = \tfrac{\pi}{8}$ ) -
catalyst.passes.ppr_to_ppm: Absorb Clifford PPRs into terminal Pauli product measurements (PPMs).
For more information on PPMs, please refer to our PPM documentation page.
-
-
Catalyst now supports qubit number-invariant compilation. That is, programs can be compiled without specifying the number of qubits to allocate ahead of time. Instead, the device can be supplied with a dynamic program variable as the number of wires. (#1549) (#1553) (#1565) (#1574)
For example, the following toy workflow is now supported, where the number of qubits,
n, is provided as an argument to a qjit'd function:import catalyst import pennylane as qml @catalyst.qjit(autograph=True) def f(n): device = qml.device("lightning.qubit", wires=n, shots=10) @qml.qnode(device) def circuit(): for i in range(n): qml.RX(1.5, wires=i) return qml.counts() return circuit()
>>> f(3) (Array([0, 1, 2, 3, 4, 5, 6, 7], dtype=int64), Array([0, 0, 3, 2, 3, 1, 1, 0], dtype=int64)) >>> f(4) (Array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], dtype=int64), Array([0, 0, 1, 1, 2, 0, 0, 0, 0, 0, 1, 1, 2, 1, 0, 1], dtype=int64))
-
Catalyst better integrates with PennyLane program capture, supporting PennyLane-native control flow operations and providing more efficient transform handling when both Catalyst and PennyLane support a transform. (#1468) (#1509) (#1521) (#1544) (#1561) (#1567) (#1578)
Using PennyLane's program capture mechanism involves setting
experimental_capture=Truein the qjit decorator. With this present, the following control flow functions in PennyLane are now usable with qjit:-
Support for
qml.cond:import pennylane as qml from catalyst import qjit dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): def ansatz_true(): qml.RX(x, wires=0) qml.Hadamard(wires=0) def ansatz_false(): qml.RY(x, wires=0) qml.cond(x > 1.4, ansatz_true, ansatz_false)() return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.99500417, dtype=float64) -
Support for
qml.for_loop:dev = qml.device("lightning.qubit", wires=2) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): @qml.for_loop(10) def loop(i): qml.H(wires=1) qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) loop() return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.97986841, dtype=float64) -
Support for
qml.while_loop:@qjit(experimental_capture=True) @qml.qnode(dev) def circuit(x: float): f = lambda c: c < 5 @qml.while_loop(f) def loop(c): qml.H(wires=1) qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) return c + 1 loop(0) return qml.expval(qml.Z(0))
>>> circuit(0.1) Array(0.97526892, dtype=float64)
Additionally, Catalyst can now apply its own compilation passes when equivalent transforms are provided by PennyLane (e.g.,
cancel_inversesandmerge_rotations). In cases where Catalyst does not have its own analogous implementation of a transform available in PennyLane, the transform will be expanded according to rules provided by PennyLane.For example, consider this workflow that contains two PennyLane transforms:
cancel_inversesandsingle_qubit_fusion. Catalyst has its own implementation ofcancel_inversesin thepassesmodule, and will smartly invoke its implementation intead. Conversely, Catalyst does not have its own implementation ofsingle_qubit_fusion, and will therefore resort to PennyLane's implementation of the transform.dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) def func(r1, r2): @qml.transforms.cancel_inverses @qml.transforms.single_qubit_fusion @qml.qnode(dev) def circuit(r1, r2): qml.Rot(*r1, wires=0) qml.Rot(*r2, wires=0) qml.RZ(r1[0], wires=0) qml.RZ(r2[0], wires=0) qml.Hadamard(wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(0)) return circuit(r1, r2)
>>> r1 = jnp.array([0.1, 0.2, 0.3]) >>> r2 = jnp.array([0.4, 0.5, 0.6]) >>> func(r1, r2) Array(0.7872403, dtype=float64)
-
Improvements 🛠
-
Several changes have been made to reduce compile time:
- MLIR's verifier has been turned off. (#1513)
- Unnecessary I/O has been removed. (#1514) (#1602)
- Improvements have been made to reduce complexity and memory. (#1524)
- IR canonicalization and LLVMIR textual generation is now performed lazily. (#1530)
- Speed up how tracers are overwritten for hybrid ops. (#1622)
-
Catalyst now decomposes non-differentiable gates when differentiating through workflows. Additionally, with
diff_method=parameter-shift, circuits are now verified to be fully compatible with Catalyst's parameter-shift implementation before compilation. (#1562) (#1568) (#1569) (#1604)Gates that are constant, such as when all parameters are Python or NumPy data types, are not decomposed when this is allow...
Catalyst v0.10.0
New features since last release
-
Catalyst can now load and apply local MLIR plugins from the PennyLane frontend. (#1287) (#1317) (#1361) (#1370)
Custom compilation passes and dialects in MLIR can be specified for use in Catalyst via a shared object (
*.soor*.dylibon macOS) that implements the pass. Details on creating your own plugin can be found in our compiler plugin documentation. At a high level, there are three ways to use a plugin once it's properly specified:-
catalyst.passes.apply_passcan be used on QNodes when there is a Python entry point defined for the plugin. In that case, the plugin and pass should both be specified and separated by a period.@catalyst.passes.apply_pass("plugin_name.pass_name") @qml.qnode(qml.device("lightning.qubit", wires=1)) def qnode(): return qml.state() @qml.qjit def module(): return qnode()
-
catalyst.passes.apply_pass_plugincan be used on QNodes when the plugin did not define an entry point. In that case the full filesystem path must be specified in addition to the pass name.from pathlib import Path @catalyst.passes.apply_pass_plugin(Path("path_to_plugin"), "pass_name") @qml.qnode(qml.device("lightning.qubit", wires=1)) def qnode(): return qml.state() @qml.qjit def module(): return qnode()
-
Alternatively, one or more dialect and pass plugins can be specified in advance in the
catalyst.qjitdecorator, via thepass_pluginsanddialect_pluginskeyword arguments. Thecatalyst.passes.apply_passfunction can then be used without specifying the plugin.from pathlib import Path plugin = Path("shared_object_file.so") @catalyst.passes.apply_pass("pass_name") @qml.qnode(qml.device("lightning.qubit", wires=0)) def qnode(): qml.Hadamard(wires=0) return qml.state() @qml.qjit(pass_plugins=[plugin], dialect_plugins=[plugin]) def module(): return qnode()
For more information on usage, visit our compiler plugin documentation.
-
Improvements 🛠
-
The Catalyst CLI, a command line interface for debugging and dissecting different stages of compilation, is now available under the
catalystcommand after installing Catalyst with pip. Even though the tool was first introduced inv0.9, it was not yet included in binary distributions of Catalyst (wheels). The full usage instructions are available in the Catalyst CLI documentation. (#1285) (#1368) (#1405) -
Lightning devices now support finite-shot expectation values of
qml.Hermitianwhen used with Catalyst. (#451) -
The PennyLane state preparation template
qml.CosineWindowis now compatible with Catalyst. (#1166) -
A development distribution of Python with dynamic linking support (
libpython.so) is no longer needed in order to usecatalyst.debug.compile_executableto generate standalone executables of compiled programs. (#1305) -
In Catalyst
v0.9the output of the compiler instrumentation (catalyst.debug.instrumentation) had inadvertently been made more verbose by printing timing information for each run of each pass. This change has been reverted. Instead, thecatalyst.qjitoptionverbose=Truewill now instruct the instrumentation to produce this more detailed output. (#1343) -
Two additional circuit optimizations have been added to Catalyst:
disentangle-CNOTanddisentangle-SWAP. The optimizations are available via thecatalyst.passesmodule. (#1154) (#1407)The optimizations use a finite state machine to propagate limited qubit state information through the circuit to turn CNOT and SWAP gates into cheaper instructions. The pass is based on the work by J. Liu, L. Bello, and H. Zhou, Relaxed Peephole Optimization: A Novel Compiler Optimization for Quantum Circuits, 2020, arXiv:2012.07711.
Breaking changes 💔
-
The minimum supported PennyLane version has been updated to
v0.40; backwards compatibility in either direction is not maintained. (#1308) -
(Device Developers Only) The way the
shotsparameter is initialized in C++ device backends is changing. (#1310)The previous method of including the shot number in the
kwargsargument of the device constructor is deprecated and will be removed in the next release (v0.11). Instead, the shots value will be specified exclusively via the existingSetDeviceShotsfunction called at the beginning of a quantum execution. Device developers are encouraged to update their device implementations between this and the next release while both methods are supported.Similarly, the
SampleandCountsfunctions (and theirPartial*equivalents) will no longer provide ashotsargument, since they are redundant. The signature of these functions will update in the next release. -
(Device Developers Only) The
toml-based device schemas have been integrated with PennyLane and updated to a new versionschema = 3. (#1275)Devices with existing TOML
schema = 2will not be compatible with the current release of Catalyst until updated. A summary of the most importation changes is listed here:operators.gates.nativerenamed tooperators.gatesoperators.gates.decompandoperators.gates.matrixare removed and no longer necessaryconditionproperty is renamed toconditions- Entries in the
measurement_processessection now expect the full PennyLane class name as opposed to the deprecatedmp.return_typeshorthand (e.g.ExpectationMPinstead ofExpval). - The
mid_circuit_measurementsfield has been replaced withsupported_mcm_methods, which expects a list of mcm methods that the device is able to work with (or empty if unsupported). - A new field has been added,
overlapping_observables, which indicates whether a device supports multiple measurements during one execution on overlapping wires. - The
optionssection has been removed. Instead, the Python device class should define adevice_kwargsfield holding the name and values of C++ device constructor kwargs.
See the Custom Devices page for the most up-to-date information on integrating your device with Catalyst and PennyLane.
Bug fixes 🐛
-
Fixed a bug introduced in Catalyst
v0.8that breaks nested invocations ofqml.adjointandqml.ctrl(e.g.qml.adjoint(qml.adjoint(qml.H(0)))). (#1301) -
Fixed a bug in
catalyst.debug.compile_executablewhen using non-64bit arrays as input to the compiled function, due to incorrectly computed stride information. (#1338)
Internal changes ⚙️
-
Starting with Python 3.12, Catalyst's binary distributions (wheels) will now follow Python's Stable ABI, eliminating the need for a separate wheel per minor Python version. To enable this, the following changes have made:
-
Stable ABI wheels are now generated for Python 3.12 and up. [(#1357)](#1357 (#1385)
-
Pybind11 has been replaced with nanobind for C++/Python bindings across all components. (#1173) (#1293) (#1391) (#624)
Nanobind has been developed as a natural successor to the pybind11 library and offers a number of advantages like its ability to target Python's Stable ABI.
-
Python C-API calls have been replaced with functions from Python's Limited API. (#1354)
-
The
QuantumExtensionmodule for MLIR Python bindings, which relies on pybind11, has been removed. The module was never included in the distributed wheels and could not be converted to nanobind easily due to its dependency on upstream MLIR code. Pybind11 does not support the Python Stable ABI. (#1187)
-
-
Catalyst no longer depends on or pins the
scipypackage. Instead, OpenBLAS is sourced directly from scipy-openblas32 or Accelerate is used. (#1322) [(#1328)](https://github.com/PennyLaneAI/catalys...
Catalyst v0.9.0
New features
-
Catalyst now supports the specification of shot-vectors when used with
qml.samplemeasurements on thelightning.qubitdevice. (#1051)Shot-vectors allow shots to be specified as a list of shots,
[20, 1, 100], or as a tuple of the form((num_shots, repetitions), ...)such that((20, 3), (1, 100))is equivalent toshots=[20, 20, 20, 1, 1, ..., 1].This can result in more efficient quantum execution, as a single job representing the total number of shots is executed on the quantum device, with the measurement post-processing then coarse-grained with respect to the shot-vector.
For example,
dev = qml.device("lightning.qubit", wires=1, shots=((5, 2), 7)) @qjit @qml.qnode(dev) def circuit(): qml.Hadamard(0) return qml.sample()
>>> circuit() (Array([[0], [1], [0], [1], [1]], dtype=int64), Array([[0], [1], [1], [0], [1]], dtype=int64), Array([[1], [0], [1], [1], [0], [1], [0]], dtype=int64))
Note that other measurement types, such as
expvalandprobs, currently do not support shot-vectors. -
A new function
catalyst.pipelineallows the quantum-circuit-transformation pass pipeline for QNodes within a qjit-compiled workflow to be configured. (#1131) (#1240)import pennylane as qml from catalyst import pipeline, qjit my_passes = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } dev = qml.device("lightning.qubit", wires=2) @pipeline(my_passes) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0)) @qjit def fn(x): return jnp.sin(circuit(x ** 2))
pipelinecan also be used to specify different pass pipelines for different parts of the same qjit-compiled workflow:my_pipeline = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } my_other_pipeline = {"cancel_inverses": {}} @qjit def fn(x): circuit_pipeline = pipeline(my_pipeline)(circuit) circuit_other = pipeline(my_other_pipeline)(circuit) return jnp.abs(circuit_pipeline(x) - circuit_other(x))
The pass pipeline order and options can be configured globally for a qjit-compiled function, by using the
circuit_transform_pipelineargument of theqjitdecorator.my_passes = { "cancel_inverses": {}, "my_circuit_transformation_pass": {"my-option" : "my-option-value"}, } @qjit(circuit_transform_pipeline=my_passes) def fn(x): return jnp.sin(circuit(x ** 2))
Global and local (via
@pipeline) configurations can coexist, however local pass pipelines will always take precedence over global pass pipelines.The available MLIR passes are listed and documented in the passes module documentation.
-
A peephole merge rotations pass, which acts similarly to the Python-based PennyLane merge rotations transform, is now available in MLIR and can be applied to QNodes within a qjit-compiled function. (#1162) (#1205) (#1206)
The
merge_rotationspass can be provided to thecatalyst.pipelinedecorator:from catalyst import pipeline, qjit my_passes = { "merge_rotations": {} } dev = qml.device("lightning.qubit", wires=1) @qjit @pipeline(my_passes) @qml.qnode(dev) def g(x: float): qml.RX(x, wires=0) qml.RX(x, wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliX(0))
It can also be applied directly to qjit-compiled QNodes via the
catalyst.passes.merge_rotationsPython decorator:from catalyst.passes import merge_rotations @qjit @merge_rotations @qml.qnode(dev) def g(x: float): qml.RX(x, wires=0) qml.RX(x, wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliX(0))
-
Static arguments of a qjit-compiled function can now be indicated by name via a
static_argnamesargument to theqjitdecorator. (#1158)Specified static argument names will be treated as compile-time static values, allowing any hashable Python object to be passed to this function argument during compilation.
>>> @qjit(static_argnames="y") ... def f(x, y): ... print(f"Compiling with y={y}") ... return x + y >>> f(0.5, 0.3) Compiling with y=0.3
The function will only be re-compiled if the hash values of the static arguments change. Otherwise, re-using previous static argument values will result in no re-compilation:
Array(0.8, dtype=float64) >>> f(0.1, 0.3) # no re-compilation occurs Array(0.4, dtype=float64) >>> f(0.1, 0.4) # y changes, re-compilation Compiling with y=0.4 Array(0.5, dtype=float64)
-
Catalyst Autograph now supports updating a single index or a slice of JAX arrays using Python's array assignment operator syntax. (#769) (#1143)
Using operator assignment syntax in favor of
at...opexpressions is now possible for the following operations:x[i] += yin favor ofx.at[i].add(y)x[i] -= yin favor ofx.at[i].add(-y)x[i] *= yin favor ofx.at[i].multiply(y)x[i] /= yin favor ofx.at[i].divide(y)x[i] **= yin favor ofx.at[i].power(y)
@qjit(autograph=True) def f(x): first_dim = x.shape[0] result = jnp.copy(x) for i in range(first_dim): result[i] *= 2 # This is now supported return result
>>> f(jnp.array([1, 2, 3])) Array([2, 4, 6], dtype=int64)
-
Catalyst now has a standalone compiler tool called
catalyst-clithat quantum-compiles MLIR input files into an object file independent of the Python frontend. (#1208) (#1255)This compiler tool combines three stages of compilation:
quantum-opt: Performs the MLIR-level optimizations and lowers the input dialect to the LLVM dialect.mlir-translate: Translates the input in the LLVM dialect into LLVM IR.llc: Performs lower-level optimizations and creates the object file.
catalyst-cliruns all three stages under the hood by default, but it also has the ability to run each stage individually. For example:# Creates both the optimized IR and an object file catalyst-cli input.mlir -o output.o # Only performs MLIR optimizations catalyst-cli --tool=opt input.mlir -o llvm-dialect.mlir # Only lowers LLVM dialect MLIR input to LLVM IR catalyst-cli --tool=translate llvm-dialect.mlir -o llvm-ir.ll # Only performs lower-level optimizations and creates object file catalyst-cli --tool=llc llvm-ir.ll -o output.o
Note that
catalyst-cliis only available when Catalyst is built from source, and is not included when installing Catalyst via pip or from wheels. -
Experimental integration of the PennyLane capture module is available. It currently only supports quantum gates, without control flow. (#1109)
To trigger the PennyLane pipeline for capturing the program as a Jaxpr, simply set
experimental_capture=Truein the qjit decorator.import pennylane as qml from catalyst import qjit dev = qml.device("lightning.qubit", wires=1) @qjit(experimental_capture=True) @qml.qnode(dev) def circuit(): qml.Hadamard(0) qml.CNOT([0, 1]) return qml.expval(qml.Z(0))
Improvements
-
Multiple
qml.samplecalls can now be returned from the same program, and can be structured using Python containers. For example, a program can return a dictionary of the formreturn {"first": qml.sample(), "second": qml.sample()}. (#1051) -
Catalyst now ships with
null.qubit, a Catalyst runtime plugin that mocks out all functions in the QuantumDevice interface. This device is provided as a convenience for testing and benchmarking purposes. (#1179)qml.device("null.qubit", wires=1) @qml.qjit @qml.qnode(dev) def g(x): qml.RX(x, wires=0) return qml.probs(wires=[0])
-
Setting the
seedargument in theqjitdecorator will now seed sampled results, in addition to mid-circuit measurement results. (#1164)dev = qml.device("lightning.qubit", wires=1, shots=10) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = catalyst.measure(0) if m: qml.Hadamard(0) return qml.sample() @qml.qjit(seed=37, autograph=True) def workflow(x): return jnp.squeeze(jnp.stack([circuit(x) for i in range(4)]))
>>> workflow(1.8) Array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 0, 0, 1, 1, 0, 0, 1, 0], [0, 0, 1, 0, 1, 1, 0, 0, 1, 1], [1, 1, 1, 0, 0, 1, 1, 0, 1, 1]], dtype=int64) >>> workf...
Catalyst v0.8.1
New features
-
The
catalyst.mitigate_with_zneerror mitigation compilation pass now supports the option to fold gates locally as well as the existing method of globally. (#1006) (#1129)While global folding applies the scale factor by forming the inverse of the entire quantum circuit (without measurements) and repeating the circuit with its inverse, local folding instead inserts per-gate folding sequences directly in place of each gate in the original circuit.
For example,
import jax import pennylane as qml from catalyst import qjit, mitigate_with_zne from pennylane.transforms import exponential_extrapolate dev = qml.device("lightning.qubit", wires=4, shots=5) @qml.qnode(dev) def circuit(): qml.Hadamard(wires=0) qml.CNOT(wires=[0, 1]) return qml.expval(qml.PauliY(wires=0)) @qjit(keep_intermediate=True) def mitigated_circuit(): s = jax.numpy.array([1, 2, 3]) return mitigate_with_zne( circuit, scale_factors=s, extrapolate=exponential_extrapolate, folding="local-all" # "local-all" for local on all gates or "global" for the original method (default being "global") )()
>>> circuit() >>> mitigated_circuit()
Improvements
-
Fixes an issue where certain JAX linear algebra functions from
jax.scipy.linalggave incorrect results when invoked from within a qjit block, and adds full support for otherjax.scipy.linalgfunctions. (#1097)The supported linear algebra functions include, but are not limited to:
Breaking changes
- The argument
scale_factorsofmitigate_with_znefunction now follows the proper literature definition. It now needs to be a list of positive odd integers, as we don't support the fractional part. (#1120)
Bug fixes
- Those functions calling the
gather_pprimitive (likejax.scipy.linalg.expm) can now be used in multiple qjits in a single program. (#1096)
Contributors
This release contains contributions from (in alphabetical order):
Joey Carter,
Alessandro Cosentino,
Paul Haochen Wang,
David Ittah,
Romain Moyard,
Daniel Strano,
Raul Torres.
Catalyst v0.8.0
New features
-
JAX-compatible functions that run on classical accelerators, such as GPUs, via
catalyst.acceleratenow support autodifferentiation. (#920)For example,
from catalyst import qjit, grad @qjit @grad def f(x): expm = catalyst.accelerate(jax.scipy.linalg.expm) return jnp.sum(expm(jnp.sin(x)) ** 2)
>>> x = jnp.array([[0.1, 0.2], [0.3, 0.4]]) >>> f(x) Array([[2.80120452, 1.67518663], [1.61605839, 4.42856163]], dtype=float64)
-
Assertions can now be raised at runtime via the
catalyst.debug_assertfunction. (#925)Python-based exceptions (via
raise) and assertions (viaassert) will always be evaluated at program capture time, before certain runtime information may be available.Use
debug_assertto instead raise assertions at runtime, including assertions that depend on values of dynamic variables.For example,
from catalyst import debug_assert @qjit def f(x): debug_assert(x < 5, "x was greater than 5") return x * 8
>>> f(4) Array(32, dtype=int64) >>> f(6) RuntimeError: x was greater than 5
Assertions can be disabled globally for a qjit-compiled function via the
disable_assertionskeyword argument:@qjit(disable_assertions=True) def g(x): debug_assert(x < 5, "x was greater than 5") return x * 8
>>> g(6) Array(48, dtype=int64) -
Mid-circuit measurement results when using
lightning.qubitandlightning.kokkoscan now be seeded via the newseedargument of theqjitdecorator. (#936)The seed argument accepts an unsigned 32-bit integer, which is used to initialize the pseudo-random state at the beginning of each execution of the compiled function. Therefor, different
qjitobjects with the same seed (including repeated calls to the sameqjit) will always return the same sequence of mid-circuit measurement results.dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = measure(0) if m: qml.Hadamard(0) return qml.probs() @qjit(seed=37, autograph=True) def workflow(x): return jnp.stack([circuit(x) for i in range(4)])
Repeatedly calling the
workflowfunction above will always result in the same values:>>> workflow(1.8) Array([[1. , 0. ], [1. , 0. ], [1. , 0. ], [0.5, 0.5]], dtype=float64) >>> workflow(1.8) Array([[1. , 0. ], [1. , 0. ], [1. , 0. ], [0.5, 0.5]], dtype=float64)
Note that setting the seed will not avoid shot-noise stochasticity in terminal measurement statistics such as
sampleorexpval:dev = qml.device("lightning.qubit", wires=1, shots=10) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) m = measure(0) if m: qml.Hadamard(0) return qml.expval(qml.PauliZ(0)) @qjit(seed=37, autograph=True) def workflow(x): return jnp.stack([circuit(x) for i in range(4)])
>>> workflow(1.8) Array([1. , 1. , 1. , 0.4], dtype=float64) >>> workflow(1.8) Array([ 1. , 1. , 1. , -0.2], dtype=float64)
-
Exponential fitting is now a supported method of zero-noise extrapolation when performing error mitigation in Catalyst using
mitigate_with_zne. (#953)This new functionality fits the data from noise-scaled circuits with an exponential function, and returns the zero-noise value:
from pennylane.transforms import exponential_extrapolate from catalyst import mitigate_with_zne dev = qml.device("lightning.qubit", wires=2, shots=100000) @qml.qnode(dev) def circuit(weights): qml.StronglyEntanglingLayers(weights, wires=[0, 1]) return qml.expval(qml.PauliZ(0) @ qml.PauliZ(1)) @qjit def workflow(weights, s): zne_circuit = mitigate_with_zne(circuit, scale_factors=s, extrapolate=exponential_extrapolate) return zne_circuit(weights)
>>> weights = jnp.ones([3, 2, 3]) >>> scale_factors = jnp.array([1, 2, 3]) >>> workflow(weights, scale_factors) Array(-0.19946598, dtype=float64)
-
A new module is available,
catalyst.passes, which provides Python decorators for enabling and configuring Catalyst MLIR compiler passes. (#911) (#1037)The first pass available is
catalyst.passes.cancel_inverses, which enables the-removed-chained-self-inverseMLIR pass that cancels two neighbouring Hadamard gates.from catalyst.debug import get_compilation_stage from catalyst.passes import cancel_inverses dev = qml.device("lightning.qubit", wires=1) @qml.qnode(dev) def circuit(x: float): qml.RX(x, wires=0) qml.Hadamard(wires=0) qml.Hadamard(wires=0) return qml.expval(qml.PauliZ(0)) @qjit(keep_intermediate=True) def workflow(x): optimized_circuit = cancel_inverses(circuit) return circuit(x), optimized_circuit(x)
-
Catalyst now has debug functions
get_compilation_stageandreplace_irto acquire and recompile the IR from a given pipeline pass for functions compiled withkeep_intermediate=True. (#981)For example, consider the following function:
@qjit(keep_intermediate=True) def f(x): return x**2
>>> f(2.0) 4.0Here we use
get_compilation_stageto acquire the IR, and then modify%2 = arith.mulf %in, %in_0 : f64to turn the square function into a cubic one viareplace_ir:from catalyst.debug import get_compilation_stage, replace_ir old_ir = get_compilation_stage(f, "HLOLoweringPass") new_ir = old_ir.replace( "%2 = arith.mulf %in, %in_0 : f64\n", "%t = arith.mulf %in, %in_0 : f64\n %2 = arith.mulf %t, %in_0 : f64\n" ) replace_ir(f, "HLOLoweringPass", new_ir)
The recompilation starts after the given checkpoint stage:
>>> f(2.0) 8.0Either function can also be used independently of each other. Note that
get_compilation_stagereplaces theprint_compilation_stagefunction; please see the Breaking Changes section for more details. -
Catalyst now supports generating executables from compiled functions for the native host architecture using
catalyst.debug.compile_executable. (#1003)>>> @qjit ... def f(x): ... y = x * x ... catalyst.debug.print_memref(y) ... return y >>> f(5) MemRef: base@ = 0x31ac22580 rank = 0 offset = 0 sizes = [] strides = [] data = 25 Array(25, dtype=int64)
We can use
compile_executableto compile this function to a binary:>>> from catalyst.debug import compile_executable >>> binary = compile_executable(f, 5) >>> print(binary) /path/to/executable
Executing this function from a shell environment:
$ /path/to/executable MemRef: base@ = 0x64fc9dd5ffc0 rank = 0 offset = 0 sizes = [] strides = [] data = 25
Improvements
-
Catalyst has been updated to work with JAX v0.4.28 (exact version match required). (#931) (#995)
-
Catalyst now supports keyword arguments for qjit-compiled functions. (#1004)
>>> @qjit ... @grad ... def f(x, y): ... return x * y >>> f(3., y=2.) Array(2., dtype=float64)
Note that the
static_argnumsargument to theqjitdecorator is not supported when passing argument values as keyword arguments. -
Support has been added for the
jax.numpy.argsortfunction within qjit-compiled functions. (#901) -
Autograph now supports in-place array assignments with static slices. (#843)
For example,
@qjit(autograph=True) def f(x, y): y[1:10:2] = x return y
>>> f(jnp.ones(5), jnp.zeros(10)) Array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.], dtype=float64)
-
Autograph now works when
qjitis applied to a function decorated withvmap,cond,for_looporwhile_loop. Previously, stacking the autograph-enabled qjit decorator directly on top of other Catalyst decorators would lead to errors. (#835) (#938) (#942)from catalyst import vmap, qjit dev = qml.device("lightning.qubit", wires=2) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) return qml.expval(qml.PauliZ(0))
>>> x = jnp.array([0.1, 0.2, 0.3]) >>> qjit(vmap(circuit), autograph=True)(x) Array([0.99500417, 0.98006658, 0.95533649], dtype=float64)
-
Runtime memory usage, and compilation complexity, has been reduced by eliminating some scalar tensors from the IR. This has been done by adding a
linalg-detensorizepass at the end of the HLO lowering pipeline. (#1010) -
Program verification is exte...
Catalyst v0.7.0
New features
-
Add support for accelerating classical processing via JAX with
catalyst.accelerate. (#805)Classical code that can be just-in-time compiled with JAX can now be seamlessly executed on GPUs or other accelerators with
catalyst.accelerate, right inside of QJIT-compiled functions.@accelerate(dev=jax.devices("gpu")[0]) def classical_fn(x): return jnp.sin(x) ** 2 @qjit def hybrid_fn(x): y = classical_fn(jnp.sqrt(x)) # will be executed on a GPU return jnp.cos(y)
Available devices can be retrieved via
jax.devices(). If not provided, the default value ofjax.devices()[0]as determined by JAX will be used. -
Catalyst callback functions, such as
pure_callback,debug.callback, anddebug.print, now all support auto-differentiation. (#706) (#782) (#822) (#834) (#882) (#907)-
When using callbacks that do not return any values, such as
catalyst.debug.callbackandcatalyst.debug.print, these functions are marked as 'inactive' and do not contribute to or affect the derivative of the function:import logging log = logging.getLogger(__name__) log.setLevel(logging.INFO) @qml.qjit @catalyst.grad def f(x): y = jnp.cos(x) catalyst.debug.print("Debug print: y = {0:.4f}", y) catalyst.debug.callback(lambda _: log.info("Value of y = %s", _))(y) return y ** 2
>>> f(0.54) INFO:__main__:Value of y = 0.8577086813638242 Debug print: y = 0.8577 array(-0.88195781) -
Callbacks that do return values and may affect the qjit-compiled functions computation, such as
pure_callback, may have custom derivatives manually registered with the Catalyst compiler in order to support differentiation.This can be done via the
pure_callback.fwdandpure_callback.bwdmethods, to specify how the forwards and backwards pass (the vector-Jacobian product) of the callback should be computed:@catalyst.pure_callback def callback_fn(x) -> float: return np.sin(x[0]) * x[1] @callback_fn.fwd def callback_fn_fwd(x): # returns the evaluated function as well as residual # values that may be useful for the backwards pass return callback_fn(x), x @callback_fn.bwd def callback_fn_vjp(res, dy): # Accepts residuals from the forward pass, as well # as (one or more) cotangent vectors dy, and returns # a tuple of VJPs corresponding to each input parameter. def vjp(x, dy) -> (jax.ShapeDtypeStruct((2,), jnp.float64),): return (np.array([np.cos(x[0]) * dy * x[1], np.sin(x[0]) * dy]),) # The VJP function can also be a pure callback return catalyst.pure_callback(vjp)(res, dy) @qml.qjit @catalyst.grad def f(x): y = jnp.array([jnp.cos(x[0]), x[1]]) return jnp.sin(callback_fn(y))
>>> x = jnp.array([0.1, 0.2]) >>> f(x) array([-0.01071923, 0.82698717])
-
-
Catalyst now supports the 'dynamic one shot' method for simulating circuits with mid-circuit measurements, which compared to other methods, may be advantageous for circuits with many mid-circuit measurements executed for few shots. (#5617) (#798)
The dynamic one shot method evaluates dynamic circuits by executing them one shot at a time via
catalyst.vmap, sampling a dynamic execution path for each shot. This method only works for a QNode executing with finite shots, and it requires the device to support mid-circuit measurements natively.This new mode can be specified by using the
mcm_methodargument of the QNode:dev = qml.device("lightning.qubit", wires=5, shots=20) @qml.qjit(autograph=True) @qml.qnode(dev, mcm_method="one-shot") def circuit(x): for i in range(10): qml.RX(x, 0) m = catalyst.measure(0) if m: qml.RY(x ** 2, 1) x = jnp.sin(x) return qml.expval(qml.Z(1))
Catalyst's existing method for simulating mid-circuit measurements remains available via
mcm_method="single-branch-statistics".When using
mcm_method="one-shot", thepostselect_modekeyword argument can also be used to specify whether the returned result should includeshots-number of postselected measurements ("fill-shots"), or whether results should include all results, including invalid postselections ("hw_like"):@qml.qjit @qml.qnode(dev, mcm_method="one-shot", postselect_mode="hw-like") def func(x): qml.RX(x, wires=0) m_0 = catalyst.measure(0, postselect=1) return qml.sample(wires=0)
>>> res = func(0.9) >>> res array([-2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, 1, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648, -2147483648]) >>> jnp.delete(res, jnp.where(res == np.iinfo(np.int32).min)[0]) Array([1, 1, 1], dtype=int64)
Note that invalid shots will not be discarded, but will be replaced by
np.iinfo(np.int32).minThey will not be used for processing final results (like expectation values), but they will appear in the output of QNodes that return samples directly.For more details, see the dynamic quantum circuit documentation.
-
Catalyst now has support for returning
qml.sample(m)wheremis the result of a mid-circuit measurement. (#731)When used with
mcm_method="one-shot", this will return an array with one measurement result for each shot:dev = qml.device("lightning.qubit", wires=2, shots=10) @qml.qjit @qml.qnode(dev, mcm_method="one-shot") def func(x): qml.RX(x, wires=0) m = catalyst.measure(0) qml.RX(x ** 2, wires=0) return qml.sample(m), qml.expval(qml.PauliZ(0))
>>> func(0.9) (array([0, 1, 0, 0, 0, 0, 1, 0, 0, 0]), array(0.4))In
mcm_method="single-branch-statistics"mode, it will be equivalent to returningmdirectly from the quantum function --- that is, it will return a single boolean corresponding to the measurement in the branch selected:@qml.qjit @qml.qnode(dev, mcm_method="single-branch-statistics") def func(x): qml.RX(x, wires=0) m = catalyst.measure(0) qml.RX(x ** 2, wires=0) return qml.sample(m), qml.expval(qml.PauliZ(0))
>>> func(0.9) (array(False), array(0.8)) -
A new function,
catalyst.value_and_grad, returns both the result of a function and its gradient with a single forward and backwards pass. (#804) (#859)This can be more efficient, and reduce overall quantum executions, compared to separately executing the function and then computing its gradient.
For example:
dev = qml.device("lightning.qubit", wires=3) @qml.qnode(dev) def circuit(x): qml.RX(x, wires=0) qml.CNOT(wires=[0, 1]) qml.RX(x, wires=2) return qml.probs() @qml.qjit @catalyst.value_and_grad def cost(x): return jnp.sum(jnp.cos(circuit(x)))
>>> cost(0.543) (array(7.64695856), array(0.33413963)) -
Autograph now supports single index JAX array assignment (#717)
When using Autograph, syntax of the form
x[i] = ywhereiis a single integer will now be automatically converted to the JAX equivalent ofx = x.at(i).set(y):@qml.qjit(autograph=True) def f(array): result = jnp.ones(array.shape, dtype=array.dtype) for i, x in enumerate(array): result[i] = result[i] + x * 3 return result
>>> f(jnp.array([-0.1, 0.12, 0.43, 0.54])) array([0.7 , 1.36, 2.29, 2.62])
-
Catalyst now supports dynamically-shaped arrays in control-flow primitives. Arrays with dynamic shapes can now be used with
for_loop,while_loop, andcondprimitives. (#775) (#777) (#830)@qjit def f(shape): a = jnp.ones([shape], dtype=float) @for_loop(0, 10, 2) def loop(i, a): return a + i return loop(a)
>>> f(3) array([21., 21., 21.]) -
Support has been added for disabling Autograph for specific functions. (#705) (#710)
The decorator
catalyst.disable_autographallows one to disable Autograph from auto-converting specific external functions when called within a qjit-compiled function withautograph=True:def approximate_e(n): num = 1. fac = 1. for i in range(1, n + 1): fac *= i num += 1. / fac ...