This repository consists of:
- The visualisation engine
- The data retrieval jupyter notebooks
- The KNIME workflows for ML- models training and prediciton
Two KNIME workflows are provided for generating off-target ML models and evaluating created models. Generate_off-target_ml-model.knwf KNIME workflow allows hyperparameter search, 5-fold cross-validation and generating final models that can be used for the evaluation in the Test_models_fin.knwf workflow.
KNIME version == 4.6
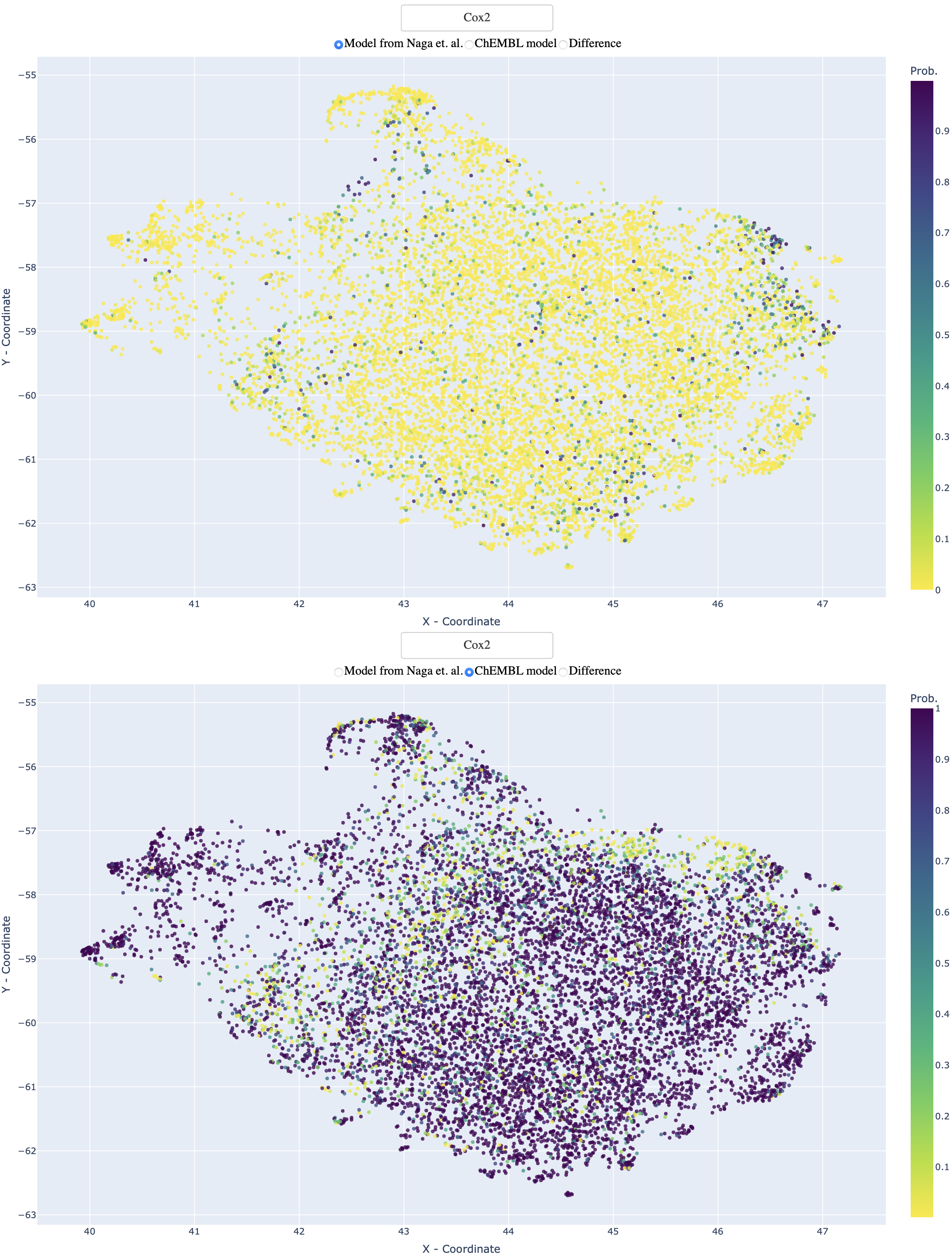
The visualisation of the prediction space of ChEMBL and Naga et. al. models is an important tool for understanding the performance of these models and for identifying differences between them. This visualization is created using Uniform Manifold Approximation and Projection (UMAP) and a custom distance function that takes into account 95% structural similarity of the molecules and 5% proximity in the prediction space.
To create this visualization, we have selected 10,000 random molecules from ChEMBL and visualized them using UMAP and our custom distance function. The visualization is interactive and allows for a detailed exploration of the prediction space of the models.
- rdkit for drawing molecules
- plotly and dash for visualising
- dash-bootstrap-components for styling the visualization
To start the visualization, simply run the command python viz.py in your terminal or command prompt.
Please cite the following publication: "Identifying Differences in the Performance of Machine Learning Models for off-Targets trained on publicly available and proprietary datasets" by Aljoša Smajić, Iris Rami, Sergey Sosnin, Gerhard F. Ecker, submitted to Chemical Research in Toxicology.