Enhanced n8n Community Node for Sogni AI Image, Video & LLM Generation
Generate AI images, videos, and LLM responses using Sogni AI Supernet directly in your n8n workflows with full ControlNet support for guided image generation, video generation capabilities, Qwen Image Edit for multi-reference image editing, and Sogni LLM chat generation for text workflows.
This node pulls from your personal Sogni account—sign up for free to get 50 free Render credits per day. Under the hood, the project utilizes the @sogni-ai/sogni-client-wrapper, which is built on top of the official @sogni-ai/sogni-client SDK.
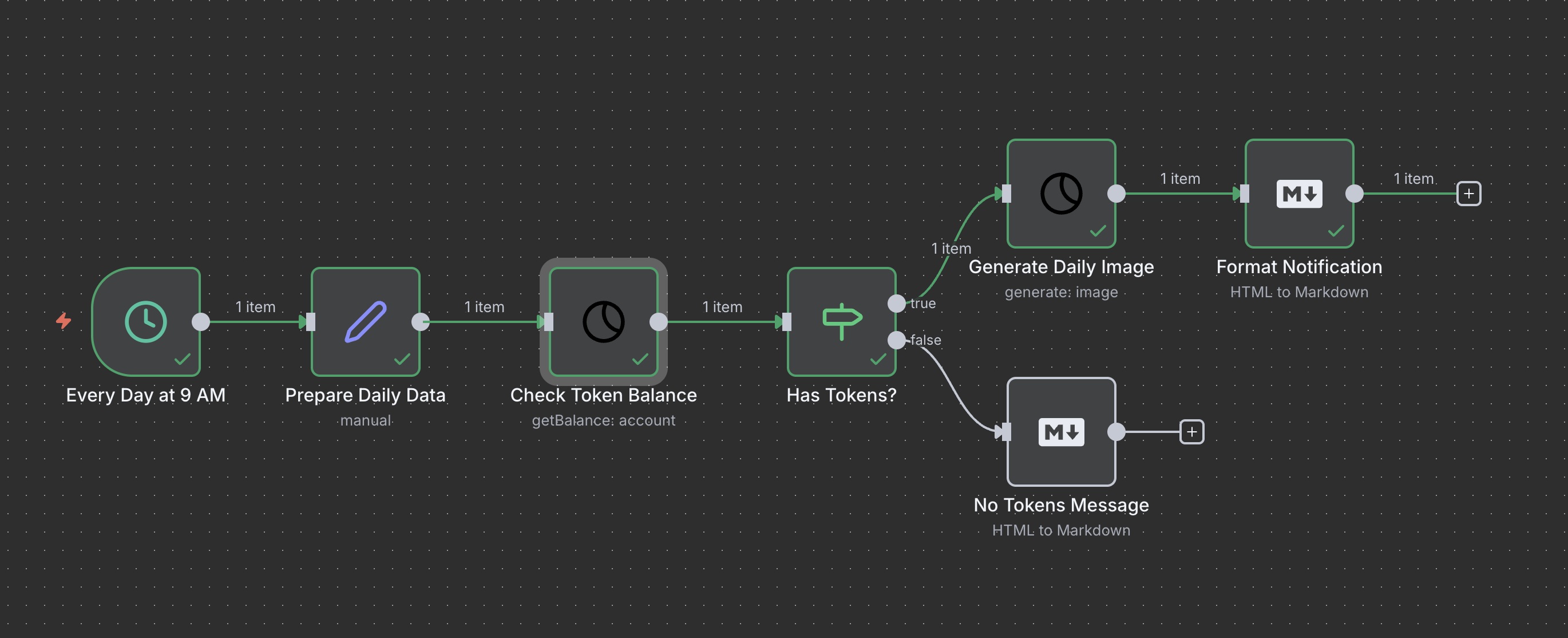
- Generate: Create AI images with optional ControlNet guidance
- Edit: Edit images using Qwen Image Edit models with context images
- Generate: Create AI videos with customizable parameters
- Estimate Cost: Estimate token/USD cost before generation
- Generate: Create text responses with Sogni chat models
- Get All: List all available Sogni LLM/chat models
- Get All: List all available models
- Get: Get specific model details
- Get Balance: Check SOGNI and Spark token balance
- In n8n, open Settings ▸ Community Nodes
- Select Install
- Enter
n8n-nodes-sogni - Confirm the installation (restart n8n if prompted)
# Run in your n8n installation directory
npm install n8n-nodes-sogni
# Restart your n8n instance after installation- In n8n, go to Credentials
- Click Add Credential
- Search for "Sogni AI"
- Enter your credentials:
- Username: Your Sogni account username
- Password: Your Sogni account password
- App ID: (Optional) Leave empty for auto-generation
- Create or open a workflow
- Click + to add a node
- Search for "Sogni AI"
- Select the node and configure
💡 Tip: You can import example workflows directly into n8n! Create a new workflow, click the ⋮ (three dots) in the top right corner, select Import from File..., and choose a sample workflow from the ./examples folder.
{
"resource": "image",
"operation": "generate",
"modelId": "flux1-schnell-fp8",
"positivePrompt": "A beautiful sunset over mountains",
"network": "fast",
"additionalFields": {
"negativePrompt": "blurry, low quality",
"steps": 20,
"guidance": 7.5,
"tokenType": "spark",
"downloadImages": true
}
}{
"resource": "image",
"operation": "generate",
"modelId": "flux1-schnell-fp8",
"positivePrompt": "A fantasy castle, magical, glowing",
"network": "fast",
"additionalFields": {
"enableControlNet": true,
"controlNetType": "canny",
"controlNetImageProperty": "data",
"controlNetStrength": 0.7,
"controlNetMode": "balanced",
"steps": 20,
"downloadImages": true
}
}{
"resource": "video",
"operation": "generate",
"videoModelId": "wan_v2.2-14b-fp8_t2v_lightx2v",
"videoPositivePrompt": "A serene waterfall flowing through a lush green forest",
"videoNetwork": "fast",
"videoAdditionalFields": {
"videoSettings": {
"frames": 81,
"fps": 16,
"steps": 4,
"guidance": 7.5
},
"output": {
"downloadVideos": true,
"outputFormat": "mp4",
"width": 640,
"height": 640
},
"advanced": {
"tokenType": "spark",
"timeout": 300000
}
}
}{
"resource": "image",
"operation": "edit",
"imageEditModelId": "qwen_image_edit_2511_fp8_lightning",
"imageEditPrompt": "Change the background to a beautiful sunset beach",
"contextImage1Property": "data",
"imageEditNetwork": "fast",
"imageEditAdditionalFields": {
"generationSettings": {
"negativePrompt": "blurry, distorted",
"numberOfMedia": 1
},
"output": {
"downloadImages": true,
"outputFormat": "png"
},
"advanced": {
"tokenType": "spark"
}
}
}All 15 ControlNet types are supported:
| Type | Description | Best For |
|---|---|---|
| canny | Edge detection | Structure preservation |
| scribble | Hand-drawn sketches | Sketch to image |
| lineart | Line art extraction | Clean line drawings |
| lineartanime | Anime line art | Anime/manga style |
| softedge | Soft edge detection | Artistic control |
| shuffle | Composition transfer | Layout preservation |
| tile | Tiling patterns | Seamless textures |
| inpaint | Masked area filling | Object removal/editing |
| instrp2p | Instruction-based editing | Text-guided edits |
| depth | Depth map | 3D structure |
| normalbae | Normal map | Surface details |
| openpose | Pose detection | Human pose transfer |
| segmentation | Semantic segmentation | Layout control |
| mlsd | Line segment detection | Architecture |
| instantid | Identity preservation | Face consistency |
See ControlNet Guide for detailed usage instructions.
| Parameter | Type | Description |
|---|---|---|
| Model ID | string | AI model to use (e.g., flux1-schnell-fp8) |
| Positive Prompt | string | What you want to generate |
| Network | options | fast (SOGNI tokens) or relaxed (Spark tokens) |
| Parameter | Type | Default | Description |
|---|---|---|---|
| Negative Prompt | string | "" | What to avoid |
| Style Prompt | string | "" | Style description |
| Number of Images | number | 1 | How many images (1-10) |
| Steps | number | 20 | Inference steps (1-100) |
| Guidance | number | 7.5 | Prompt adherence (0-30) |
| Token Type | options | spark | spark or sogni |
| Output Format | options | png | png or jpg |
| Download Images | boolean | true | Download as binary data |
| Size Preset | string | "" | Size preset ID |
| Width | number | 1024 | Custom width (256-2048) |
| Height | number | 1024 | Custom height (256-2048) |
| Seed | number | random | Reproducibility seed |
| Timeout | number | 600000 | Max wait time (ms) |
| Parameter | Type | Default | Description |
|---|---|---|---|
| Enable ControlNet | boolean | false | Enable ControlNet |
| ControlNet Type | options | canny | Type of ControlNet |
| Control Image Property | string | data | Binary property name |
| Strength | number | 0.5 | Control strength (0-1) |
| Mode | options | balanced | balanced / prompt_priority / cn_priority |
| Guidance Start | number | 0 | When to start (0-1) |
| Guidance End | number | 1 | When to end (0-1) |
| Parameter | Type | Description |
|---|---|---|
| Video Model ID | string | AI model to use for video generation |
| Video Positive Prompt | string | What you want in the video |
| Video Network | options | fast or relaxed |
| Parameter | Type | Default | Description |
|---|---|---|---|
| Negative Prompt | string | "" | What to avoid in video |
| Style Prompt | string | "" | Video style description |
| Number of Videos | number | 1 | How many videos (1-4) |
| Frames | number | 30 | Number of frames (10-120). For LTX-2 use 8n+1 frame counts |
| Duration | number | auto | Optional seconds for model-aware frame calculation |
| FPS | number | 30 | Frames per second (10-60) |
| Steps | number | 20 | Inference steps (1-100) |
| Guidance | number | 7.5 | Prompt adherence (0-30) |
| Shift | number | model default | Optional motion intensity control |
| TeaCache Threshold | number | model default | Optional T2V/I2V optimization control |
| Sampler | string | model default | Optional sampler override |
| Scheduler | string | model default | Optional scheduler override |
| Reference Image Property | string | "" | Binary property for i2v/s2v/animate workflows |
| Reference End Image Property | string | "" | Binary property for interpolation end frame |
| Reference Audio Property | string | "" | Binary property for s2v workflows |
| Reference Video Property | string | "" | Binary property for animate/v2v workflows |
| Video Start | number | 0 | Optional source-video offset (seconds) |
| Audio Start | number | 0 | Optional source-audio offset (seconds) |
| Audio Duration | number | server default | Optional source-audio duration (seconds) |
| Trim End Frame | boolean | false | Useful for transition stitching |
| First Frame Strength | number | model default | LTX-2 keyframe interpolation control (0-1) |
| Last Frame Strength | number | model default | LTX-2 keyframe interpolation control (0-1) |
| SAM2 Coordinates (JSON) | string | "" | Animate-replace subject points, e.g. [{"x":0.5,"y":0.5}] |
| Enable LTX-2 Video ControlNet | boolean | false | Enables controlNet for LTX v2v |
| Video ControlNet Type | options | canny | canny, pose, depth, detailer |
| Video ControlNet Strength | number | 0.8 | ControlNet strength for v2v |
| Output Format | options | mp4 | Currently only mp4 is supported |
| Download Videos | boolean | true | Download as binary data |
| Width | number | 512 | Video width (256-1024) |
| Height | number | 512 | Video height (256-1024) |
| Timeout | number | auto | Max wait time (ms) |
| Auto Resize Video Assets | boolean | true | Normalize/resize reference assets for video compatibility |
| Parameter | Type | Description |
|---|---|---|
| Image Edit Model ID | string | Qwen Image Edit model to use |
| Edit Prompt | string | Description of the edit to apply |
| Context Image 1 | string | Binary property name for first context image (required) |
| Network | options | fast or relaxed |
| Parameter | Type | Default | Description |
|---|---|---|---|
| Context Image 2 | string | "" | Binary property for second context image |
| Context Image 3 | string | "" | Binary property for third context image |
| Negative Prompt | string | "" | What to avoid in result |
| Style Prompt | string | "" | Style description |
| Number of Images | number | 1 | How many images (1-10) |
| Steps | number | auto | Inference steps (auto: 20 for standard, 4 for lightning) |
| Guidance | number | auto | Prompt adherence (auto: 4.0 for standard, 1.0 for lightning) |
| Download Images | boolean | true | Download as binary data |
| Output Format | options | png | png or jpg |
| Token Type | options | spark | spark or sogni |
| Timeout | number | auto | Max wait time (ms) |
| Model ID | Description | Recommended Steps |
|---|---|---|
qwen_image_edit_2511_fp8 |
Standard quality model | 20 steps |
qwen_image_edit_2511_fp8_lightning |
Fast lightning model | 4 steps |
See the examples directory for complete workflow JSON files:
- Basic Image Generation - Simple text-to-image
- Batch Processing - Generate multiple images
- Dynamic Model Selection - Auto-select best model
- Scheduled Generation - Daily automated images
- Video Generation - AI video creation with customizable parameters
- Image Edit with Qwen - Edit images using context-aware Qwen models
- Emotional Slothi Telegram Bot - Dynamic Qwen image-edit + Telegram posting
- LTX-2 Video-to-Video ControlNet - Advanced v2v workflow with reference video + controls
- WAN Animate-Replace with SAM2 - Subject-guided video replacement with reference image + source video
- LTX-2 Text-to-Video - Minimal prompt-only LTX t2v workflow
- LTX 2.3 Dynamic Text-to-Video - Auto-select an available
ltx23-*model before generation - Sogni LLM Person Poem Page - Ask for a person's name in an n8n form, auto-select an available chat model, generate a witty rhyming poem, and show it on n8n's completion page
- Sogni LLM Describe Uploaded Image - Upload an image in an n8n form, send it to the documented Qwen3.5 VLM path, and show the generated description on n8n's completion page
{
"projectId": "ABC123...",
"modelId": "flux1-schnell-fp8",
"prompt": "A beautiful sunset...",
"imageUrls": [
"https://complete-images-production.s3-accelerate.amazonaws.com/..."
],
"completed": true,
"jobs": [
{
"id": "JOB123...",
"status": "completed"
}
]
}- image: First generated image
- image_1: Second image (if multiple)
- image_2: Third image (if multiple)
- etc.
{
"projectId": "VID123...",
"modelId": "video-model-id",
"prompt": "A cat playing...",
"videoUrls": [
"https://complete-videos-production.s3-accelerate.amazonaws.com/..."
],
"completed": true,
"jobs": [
{
"id": "JOB456...",
"status": "completed"
}
]
}- video: First generated video
- video_1: Second video (if multiple)
- video_2: Third video (if multiple)
- etc.
Binary data includes:
- Proper MIME type (video/mp4)
- Filename:
sogni_video_[projectId]_[index].[ext] - Full resolution video data
{
"projectId": "EDIT123...",
"modelId": "qwen_image_edit_2511_fp8_lightning",
"prompt": "Change the background to a sunset beach",
"imageUrls": [
"https://complete-images-production.s3-accelerate.amazonaws.com/..."
],
"completed": true,
"contextImagesCount": 1,
"jobs": [
{
"id": "JOB789...",
"status": "completed"
}
]
}- image: First edited image
- image_1: Second image (if multiple)
- image_2: Third image (if multiple)
- etc.
Binary data includes:
- Proper MIME type (image/png or image/jpeg)
- Filename:
sogni_edit_[projectId]_[index].[ext] - Full resolution edited image
-
Fast Network:
- Uses SOGNI tokens
- Faster generation (seconds to minutes)
- Higher cost
- Best for: Time-sensitive applications
-
Relaxed Network:
- Uses Spark tokens
- Slower generation (minutes to hours)
- Lower cost
- Best for: Batch processing, scheduled jobs
Popular models:
flux1-schnell-fp8: Fast, high quality, 4 steps recommendedcoreml-sogni_artist_v1_768: Artistic stylechroma-v.46-flash_fp8: Fast generation
Use "Get All Models" operation to see all available models.
- Flux models: 4-8 steps (optimized for speed)
- SD models: 15-30 steps (better quality)
- ControlNet: 20-30 steps (more control)
- Start with strength 0.5 and adjust
- Use
balancedmode for most cases - Match ControlNet type to your control image
- See ControlNet Guide for details
- Enable
downloadImagesto prevent URL expiry - URLs expire after 24 hours
- Binary data is permanent in n8n
- Recommended for production workflows
- Image - Fast network: 60,000ms (1 minute) usually enough
- Image - Relaxed network: 600,000ms (10 minutes) recommended
- Video - Fast network: 120,000ms (2 minutes) minimum
- Video - Relaxed network: 1,200,000ms (20 minutes) recommended
- Adjust based on complexity and model
- Frame Count: Start with 30 frames for quick tests, increase for longer videos
- FPS: Use 30 fps for smooth motion, 10-15 fps for stylized/animated look
- Resolution: Start with 512x512 for faster generation, increase as needed
- Format: Currently only MP4 format is supported
- Models: Look for models with "video", "animation", or "motion" in their names
- Model Selection: Use
lightningvariant for fast results (4 steps), standard for quality (20 steps) - Context Images: Provide 1-3 reference images that inform the edit
- Edit Prompts: Be specific about what to change (e.g., "change background to beach" vs "make it better")
- Multiple References: Use 2-3 context images for complex edits like style transfer or object compositing
- Steps: Leave empty for auto-detection based on model, or override for fine control
Solution: Add more Spark or SOGNI tokens to your account
Solution: Use "Get All Models" to see available models
Solution:
- Ensure previous node outputs binary data
- Check the binary property name
- Use "View" in n8n to inspect data
Solution:
- Use relaxed network for slower but more reliable generation
- Increase timeout in Additional Fields
- Split large batches into smaller chunks
Solution:
- Check
downloadImagesis enabled - Verify network connectivity
- Check n8n logs for download errors
Solution:
- Ensure previous node outputs binary data with the correct property name
- Check
contextImage1Propertymatches your binary property (default:data) - Use "View" in n8n to inspect binary data from previous node
- For multiple context images, verify each property name is correct
Solution:
- Use more specific edit prompts describing exactly what to change
- Try the standard model (
qwen_image_edit_2511_fp8) for better quality - Adjust guidance value (higher = more adherence to prompt)
- Provide additional context images for complex edits
Sogni Generate → HTTP Request (Discord Webhook)
Sogni Generate → Google Drive (Upload File)
Sogni Generate → Twitter/Instagram API
Load Image → Sogni ControlNet → Post-Processing → Save
Use expressions to generate dynamic prompts:
{{ "A " + $json.style + " image of " + $json.subject }}Enable ControlNet based on conditions:
{{ $json.hasControlImage ? true : false }}This node uses the @sogni-ai/sogni-client-wrapper library. For standalone Node.js usage:
import { SogniClientWrapper } from '@sogni-ai/sogni-client-wrapper';
const client = new SogniClientWrapper({
username: 'your-username',
password: 'your-password',
autoConnect: true,
});
const result = await client.createProject({
modelId: 'flux1-schnell-fp8',
positivePrompt: 'A beautiful sunset',
network: 'fast',
tokenType: 'spark',
waitForCompletion: true,
});See @sogni-ai/sogni-client-wrapper for full API documentation.
- 📦 Updated
@sogni-ai/sogni-client-wrappertov1.6.1 - 🔄 Pulled in wrapper-side upgrades from
@sogni-ai/sogni-client@4.1.1 - ✅ Revalidated the n8n node against the latest wrapper release
- 🤖 Added support for Sogni Intelligence with Sogni LLM models like Qwen3.5, including
GenerateandGet Allchat model operations - 🧠 Added advanced chat inputs:
Messages JSONTools JSONTool Choice JSON
- 🧩 Preserved incoming item JSON in
LLM -> Generateoutputs so looped/stateful workflows can carry execution state forward - ⏱️ Extended chat-model lookup timeouts for more reliable LLM workflow startup
- 🧪 Added bundled LLM example workflows for:
- person poem generation with n8n forms and completion pages
- uploaded-image description using the documented Qwen3.5 VLM path
- 🖼️ Added a bundled sample upload image (
examples/duck.jpg) for quick vision workflow testing - 📚 Refreshed README and example docs around the current LLM and vision workflows
- 📦 Updated
@sogni-ai/sogni-client-wrappertov1.6.0
- 🧪 Added dedicated LTX-2 text-to-video example workflow (
examples/10-ltx2-text-to-video.json) - 📦 Updated
@sogni-ai/sogni-client-wrappertov1.5.2 - 🎬 Added
ltx23-*/ltx2.3-*video model detection and LTX frame normalization coverage - 🧪 Added dynamic LTX 2.3 example workflow (
examples/11-ltx23-dynamic-text-to-video.json)
- 📦 Updated
@sogni-ai/sogni-client-wrappertov1.4.3 - 🎬 Added
Video → Estimate Costoperation (wrapperestimateVideoCost) - 🧠 Improved video model detection to include
ltx2-*,ltx23-*, andwan_*model families - 🧩 Added advanced video workflow inputs/controls for LTX/WAN (
referenceVideo,referenceAudio, SAM2, keyframe strengths, video ControlNet) - 🖼️ Aligned Qwen image-edit guidance defaults with wrapper (
4.0standard,1.0lightning) - 🎥 Added
Auto Resize Video Assetstoggle for video generation
- 📚 Enhanced README documentation for Image Edit feature
- 📝 Added Image Edit output section, tips, and troubleshooting
- 🖼️ Added Qwen Image Edit support with multi-reference context images
- 📦 Updated @sogni-ai/sogni-client-wrapper to v1.4.0
- ⚡ Auto-detection of optimal steps based on model (20 for standard, 4 for lightning)
- 🎯 Up to 3 context images for sophisticated multi-reference editing
- 🎬 Added full video generation support
- 📦 Updated @sogni-ai/sogni-client-wrapper to v1.2.0
- 🎥 MP4 video format support
- ⚙️ Configurable video parameters (frames, FPS, resolution)
- 📥 Automatic video download as binary data
- 🔍 Dedicated video model selection and filtering
- 📝 Updated Sogni signup copy and highlighted ControlNet positioning
- 🆕 Refreshed installation instructions and Sogni account links
- 📚 Added references to Sogni platform, docs, and SDK packages
- ⚡ Changed default network from "relaxed" to "fast" for quicker generation
- 📝 Documentation updates
- 🔧 Minor bug fixes and improvements
- 📝 Documentation updates
- ✨ Added full ControlNet support (15 types)
- 📥 Added automatic image download
- 🔑 Enhanced appId auto-generation
- ⚙️ Improved default values
- 📚 Added ControlNet guide
- Initial release
- Basic image generation
- Model and account operations
- Size presets support
- ControlNet Guide - Complete ControlNet usage guide
- Example Workflows - Ready-to-use workflow examples
- Sogni AI - Platform overview and product updates
- Sogni SDK Docs - Official SDK documentation
- Sogni Docs - Platform guides and API references
- Integration Guide - Complete integration guide
For issues or questions:
- Check this README
- Review the ControlNet Guide
- Check example workflows
- Submit an issue on GitHub
MIT License - See LICENSE file for details
Built with:
- @sogni-ai/sogni-client - Official Sogni SDK
- @sogni-ai/sogni-client-wrapper - Enhanced wrapper library
- n8n - Workflow automation platform
Ready to generate and edit amazing AI images in your n8n workflows! 🎨✨