Official PyTorch Implementation & Interactive Simulator
Spatio-Temporal Hybrid Architecture Reproduction and Validation Pipeline for Wafer Defect Pattern Classification
⚠️ Copyright Notice Copyright (c) 2026 Kang Gyu Min. All rights reserved.
This repository provides the official implementation of the core architecture developed for my Master's Thesis at Kyung Hee University Graduate School, which was subsequently published in the SCIE journal [The International Journal of Advanced Manufacturing Technology (JCR Q2)]. It also serves as a validation project demonstrating model reproducibility across distinct hardware infrastructures.
Combining Residual Network and Bidirectional Long Short-Term Memory with Additive Attention for Wafer Defect Classification
Gyumin Kang, et al.
🔗 Read the Article on Springer
A hybrid model that combines the global spatial feature extraction capabilities of CNNs with the sequential context understanding of RNNs.
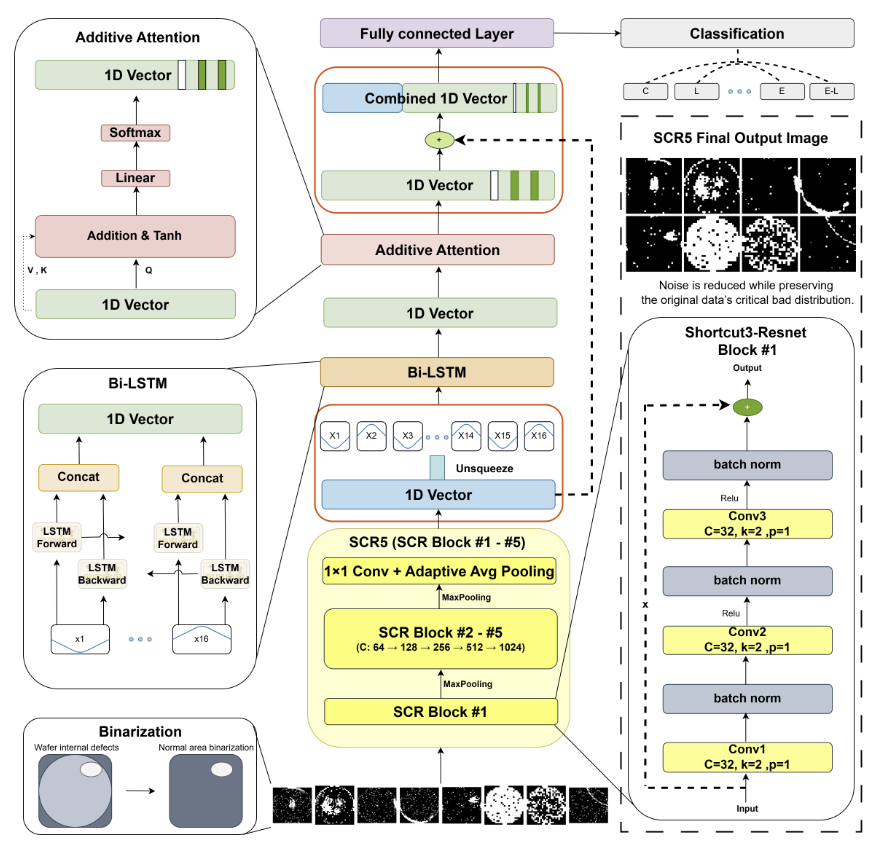
- Shortcut3-ResNet (SCR5): Extracts spatial features from the Binarized Wafer Map.
- Sliding-Window Tokenization: Converts high-dimensional feature vectors into overlapping sequential tokens.
- Bi-LSTM & Additive Attention: Analyzes bidirectional sequences and dynamically assigns attention weights to windows exhibiting strong defect characteristics.
🎯 MUST-TRY: Experience the AI Model in Action!
We strongly encourage reviewers to try our web-based interactive simulator. Rather than just reading the code, you can manually generate 8 distinct wafer defect patterns and visually verify how the SCRBLAA-Net architecture detects and activates upon them in real-time.
(⚡️ Click the link above to test it immediately in your browser! Zero installation required & runs in 1 second.)
This repository accurately reproduces the proposed architecture using PyTorch and conducts a variance analysis across different infrastructure environments.
- Original Paper Performance:
Test Accuracy 94.98%(NVIDIA RTX 3090 Ti 24GB / CUDA Environment) - Local Reproduction Performance:
Test Accuracy 94.10%/ (MacBook pro M5 base chip / MPS Environment)
💡 Analysis of Reproduction Variance: The 94.98% accuracy reported in the paper is a maximized metric derived under a strictly controlled random seed on a high-end desktop environment (NVIDIA RTX 3090 Ti) using a CUDA backend. The minor numerical variance of approximately 0.88%p observed in this local reproduction (MacBook Apple Silicon) is attributed to the following factors:
- Hardware Core Architecture: Hardware-level differences in tensor computation algorithms and floating-point precision processing between NVIDIA's CUDA acceleration environment and Apple Silicon's MPS (Metal Performance Shaders) architecture.
- Stochastic Backend Variance: Stochastic variability during weight initialization and accelerated computation processes, caused by differences in framework backend optimization solutions.
Despite these environmental discrepancies, defending a high classification accuracy of over 94% and a stable Macro F1-Score of over 0.91 quantitatively proves that the proposed SCRBLAA-Net architecture does not overfit to a specific hardware infrastructure and maintains robust generalization performance across diverse deployment environments.
A high-speed binarization pipeline was applied to maximize subtle defect patterns and suppress manufacturing process noise.

(The image above shows representative binarized wafer map samples for the 8 defect types after preprocessing.)
- Deep Learning Framework: PyTorch (MPS / CUDA Support)
- Data Processing: NumPy, Pandas, OpenCV, Scikit-Learn
- Visualization & Demo: Matplotlib, Seaborn, HTML5/CSS/Vanilla JS