[LIVY-616] Livy Server discovery#189
Conversation
|
What IDEA plugin do you use for import ordering? |
|
BinaryThriftServerSuite."fetch different data types" looks flaky https://travis-ci.org/apache/incubator-livy/jobs/566398488 Created separated ticket https://issues.apache.org/jira/browse/LIVY-618 |
Codecov Report
@@ Coverage Diff @@
## master #189 +/- ##
============================================
- Coverage 68.71% 68.66% -0.05%
- Complexity 908 909 +1
============================================
Files 100 103 +3
Lines 5674 5710 +36
Branches 854 854
============================================
+ Hits 3899 3921 +22
- Misses 1219 1231 +12
- Partials 556 558 +2
Continue to review full report at Codecov.
|

|
I have added API for getting Livy Server address to LivyClient, HttpClient, RSCClient and LivyScalaClient. I don't see a way to forward Livy address from DiscoveryManager to HttpClient or LivyScalaClient (we need to add a dependency on So, from client code we can use: Added scaladocs, small refactoring. |
|
Refactored configuration to provide a more flexible mechanism for configuration, simplified code |
|
Hi @o-shevchenko thanks a lot for your contribution. It would be better to have a design doc to describe what you're trying to resolve and what is your solution. It's really hard for the reviewer to understand your code without any documentation. |
|
Thanks a lot @jerryshao for your comment. I'll prepare documentation about the solution. |
|
@jerryshao you can find documentation in the Jira ticket: https://issues.apache.org/jira/browse/LIVY-616. |
… as mixin it instead of creating as field
|
@jerryshao Any updates? |
| private def resolvedSeverHost(livyConf: LivyConf) = { | ||
| val host = livyConf.get(LivyConf.SERVER_HOST) | ||
| if (host.equals(livyConf.get(LivyConf.SERVER_HOST.dflt.toString))) { | ||
| InetAddress.getLocalHost.getHostName |
There was a problem hiding this comment.
I do not quite understand the if condition here. Could you please explain it a bit? Thanks.
And another question is why we return the hostname instead of IP here? IMHO, IP should be more convenient, as hostname user needs to update their hosts file or set up the name service.
There was a problem hiding this comment.
You can find more detailed info in the specification which attached to the Jira ticket
To enable Livy Server discovery we need to set livy.zookeeper.url. During start Livy Server we save URI to ZooKeeper. If we specify host by livy.server.host then we will use this value. if we use the default value “0.0.0.0” the local host name will be stored(InetAddress.getLocalHost.getHostName) to be able to communicate from other nodes. We will store address as java.net.URI (in format schema://host:port, e.g.http://livyhostname:8998)
So, basically it's needed to resolve Livy Server address by replacing 0.0.0.0 default value with the correct IP address if user didn't specify any Livy Server address in the conf file. In this case, we can use InetAddress.getLocalHost.getHostName to get the address from the node where LivyServer was started.
See your point, InetAddress.getLocalHost.getHostAddress might be the better choice here.
Thanks!
There was a problem hiding this comment.
From your description, should it be
if (host.equals(LivyConf.SERVER_HOST.dflt.toString)) {
...There was a problem hiding this comment.
oh, I see
it's my mistake.
good catch!
livyConf.get(LivyConf.SERVER_HOST.dflt.toString) not make a sense in this case, looks like it's typical copy problem
| * @param livyConf - Livy configurations | ||
| * @param mockCuratorClient - used for testing | ||
| */ | ||
| class LivyDiscoveryManager(val livyConf: LivyConf, |
There was a problem hiding this comment.
Should we consider providing a generic method to publishing configuration key/value to zookeeper?
In some other scenario, e.g. this PR #193 , a bunch of hive related configurations need to be published.
If we have a generic method publish configuration key/value, it may be easier to let other components to leverage the code.
There was a problem hiding this comment.
We already have one in ZooKeeperManager
LivyDiscovery is a hight level of abstraction which is used for better understanding, single responsibility and API simplification
There was a problem hiding this comment.
I just refactored StateStore to move functionality for communication with ZK from ZooKeeperStateStore.scala to separated trait ZooKeeperManager.scala. In ZooKeeperStateStore we will use ZooKeeperManager to store data in ZK. ZooKeeperManager code was not changed except couple small improvements for configurations to make it more flexible.
We can use this trait everywhere when we need to store something to ZooKeeper since it's generic:
def setData(key: String, value: Object): Unit = {
val prefixedKey = prefixKey(key)
val data = serializeToBytes(value)
if (exist(prefixedKey)) {
curatorClient.setData().forPath(prefixedKey, data)
} else {
curatorClient.create().creatingParentsIfNeeded().forPath(prefixedKey, data)
}
}
def getData[T: ClassTag](key: String): Option[T] = {
val prefixedKey = prefixKey(key)
if (exist(prefixedKey)) {
Option(deserialize[T](curatorClient.getData().forPath(prefixedKey)))
} else {
None
}
}
There was a problem hiding this comment.
ZooKeeperManager should be used every time by design when we need to store something to ZK. I think we need to have one logic for ZK interaction for LivyServer discovery, ZK state store, Livy HA, Livy Thrift Server HA. That's why I moved this functionality to the separated trait, to make it reuseable for someone else.
There was a problem hiding this comment.
Also, I have tried to make all configurations more generic and configurable on the top level to use it everywhere. As far as I see, for now, we have a couple of PRs with different ZK logic which can't be reused a lot and I see too specific confs like livy.server.thrift.zookeeper.quorum instead of simple common livy.zookeeper.url which can be reused. In this PR I want to not only add LivyServer discovery but also create init structure for subsequent work with ZooKeeper.
Codecov Report❌ Patch coverage is Additional details and impacted files@@ Coverage Diff @@
## master #189 +/- ##
============================================
- Coverage 68.71% 68.51% -0.20%
- Complexity 908 919 +11
============================================
Files 100 103 +3
Lines 5674 5746 +72
Branches 854 866 +12
============================================
+ Hits 3899 3937 +38
- Misses 1219 1243 +24
- Partials 556 566 +10 ☔ View full report in Codecov by Sentry. 🚀 New features to boost your workflow:
|
What changes were proposed in this pull request?
JIRA ticket https://issues.apache.org/jira/browse/LIVY-616.
Implement Livy Server discovery mechanism based on ZooKeeper. And provide convenient API for clients to get LivyServer URL without explicitly set it manually by "livy.server.host" property. Then we also can use it in LivyClientBuilder to set URL automatically. It will provide a more easy way for configuration. We don't need to set "livy.server.host" or "zeppelin.livy.url" manually in a case when we don't know where Livy Server will be started.
I have separated ZooKeeper logic from StateStore logic, as a result, we can use new ZooKeeperManager just to communicate with ZooKeeper and build new logic based on it (as I did for DiscoveryManager and ZooKeeperStateStore)
How was this patch tested?
Added unit tests for new functionality.
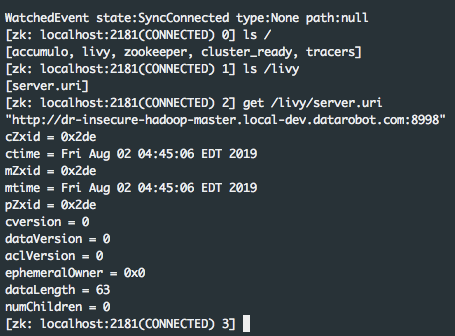
Tested manually:
After starting LivyServer we can get Livy Server URI from ZooKeeper
Also verified on a secured cluster.
What the best way to add new API?
I see the couple of ways to do that:
Please, advise.