

You meet with the agent. The agent meets with you. Management hears both sides. skiplevel turns the transcripts already sitting on your machine into The 360 Review: a two-sided performance review between you and your coding agents — Claude Code, Codex CLI, and opencode. HR regrets scheduling the meeting.
$ uvx skiplevel
skiplevel: scheduling a meeting with Claude Code + opencode's managers...
rifling through ~/.claude/projects ...
rifling through ~/.local/share/opencode ...
found 652 sessions (432 MB). Reading everything. Judging silently.
parsed 541 sessions across 31 days...
counted 52 'you're absolutely right's... oh no
tallied 34,849 tool calls and $4,062.61 in tokens...
found one file read 30 times in a single session. no further questions.
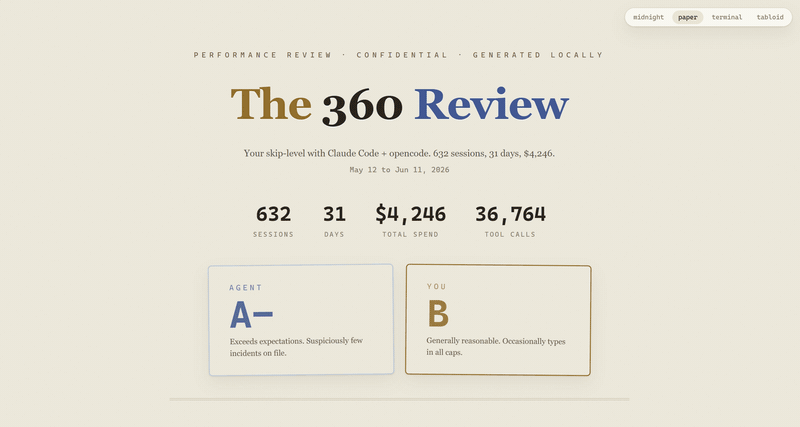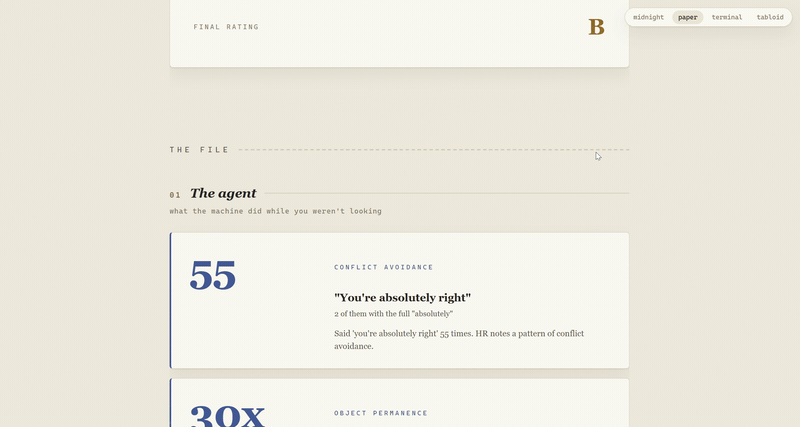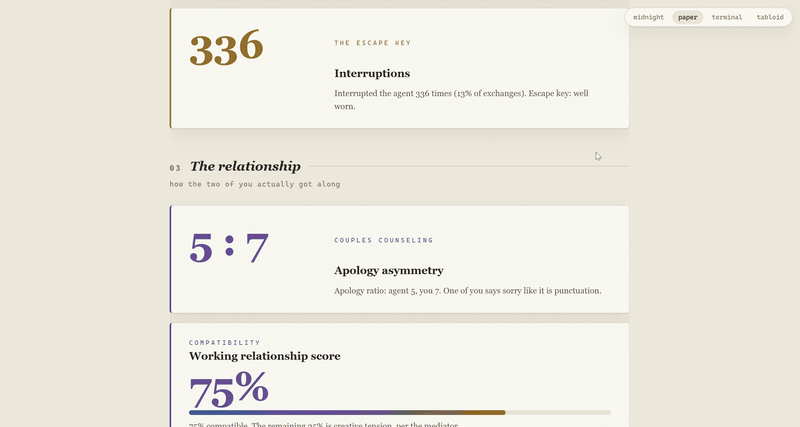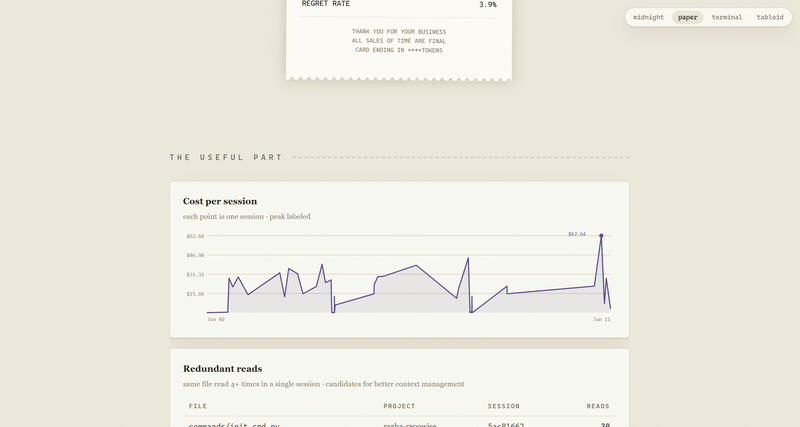
verdict: AGENT A- / YOU B. the committee has spoken.
Skip-level complete in 8.1s. The truth is in skiplevel-report.html
generated locally. nothing left your machine.
One self-contained HTML file. Four themes: midnight (dark, default), paper (printed HR document), terminal (green phosphor), and tabloid (newsprint gossip). Switchable from a pill in the report, persistent, and exports respect the active theme. Looks good in screenshots, which is the point.
uvx skiplevel # zero install, zero config
# or
pip install skiplevel
skiplevelFlags:
| flag | what it does |
|---|---|
--harness H |
auto (default: review every agent with transcripts), claude-code, codex, or opencode |
--dir PATH |
transcripts root (default: each harness's own home) |
--out PATH |
output file (default ./skiplevel-report.html) |
--json |
also dump the raw stats JSON next to the HTML |
--no-open |
do not open a browser |
--roast |
opt-in LLM roast via your own claude CLI (see below) |
--theme T |
initial theme: midnight, paper, terminal, tabloid |
| harness | where the diary lives |
|---|---|
| Claude Code | ~/.claude/projects/**/*.jsonl |
| Codex CLI | $CODEX_HOME/sessions/ and archived_sessions/ rollout JSONL (default ~/.codex) |
| opencode | ~/.local/share/opencode/opencode.db (SQLite), or the older storage/ JSON tree |
By default every harness with transcripts gets summoned into the same
meeting and one combined review. --harness codex (or claude-code,
opencode) reviews a single agent; --dir points at a non-standard
location, and the layout is sniffed automatically.
Notes per harness:
- Codex CLI: archived copies of active sessions are deduplicated, forked-session token replays are not double-counted, and sessions predating token telemetry (Sept 2025) parse fine with zero cost.
- opencode: child (subagent) sessions count toward tokens and tools but not toward your prompt stats; opencode's own per-message cost is used when present, otherwise the price table kicks in.
You get graded on clarity, patience, civility, and trust calibration: prompt lengths, a punch card of when you actually work, your late-night ratio, interrupt rate, vocabulary (including your "fix" count and your all-caps incidents), and the median seconds you give the agent before demanding more.
The agent gets graded on efficiency, reliability, safety, and composure: "you're absolutely right" counts, apology rates, files it read 4+ times in one session (object permanence), retry storms (the same failing call, again, with hope), sensitive file touches with timestamps, blast radius, and its longest unsupervised tool-call chain.
The relationship gets the rest: apology asymmetry, a timeline of your single longest session, an itemized Expense Report of Regret, compatibility score, and yearbook superlatives.
Under the comedy there is a genuinely useful layer: sortable tables of redundant reads, retry storms, sensitive file touches, per-session cost trend, and top edited files. Real numbers, real receipts.
Two report cards — one for the agent, one for you — plus an archetype, a compatibility score, and yearbook superlatives. None of it is vibes. Each grade is a weighted average of four traits, each trait a number from 0 to 1 traced back to something you actually did:
| who | graded on (weights) |
|---|---|
| agent | efficiency (35%), reliability (30%), composure (20%), safety (15%) |
| you | clarity (30%), patience (30%), civility (20%), trust (20%) |
Two opinions are baked into the math worth flagging up front: there's such a thing as too clear (a 400-word prompt scores worse than an 80-word one), and too trusting (accepting every edit unread isn't trust, it's absence — the sweet spot is high, not maxed). Letter bands top out at A+ (≥0.93) and bottom out at D; there is no F.
The full rubric — every formula, the six archetypes, the award thresholds, and why cost is an honest estimate — is written up in docs/scoring.md. It is precise and it is not on your side.
Everything runs locally. The report is one HTML file with zero external requests: no CDN, no fonts, no analytics, no telemetry, no accounts.
Don't take our word for it: grep the source for requests or urllib.
You will find nothing. Then grep the generated HTML for http; you will
find two footer links (this repo and the Repowise team) and nothing else.
Roast mode is opt-in and sends only aggregated numbers (counts, ratios,
the top-ten word list) to your own Claude account through your own claude
CLI. No prompts, no code, no file paths leave your machine, ever.
skiplevel --roastIf the claude CLI is installed, the aggregated stats are sent to it with a
60 second timeout, and three lines of the report (the manager's comment, the
agent's review of you, and the share-card verdict) are written fresh for your
specific numbers. On any failure it falls back silently to the built-in
copy. Default mode never calls any LLM and is fully deterministic.
Built to be screenshotted. Every card grows copy and save buttons on hover: copy puts a PNG straight on your clipboard, save downloads it. The 1200x630 share card at the bottom has its own copy and save buttons, plus a GIF export that plays the whole review as a three-panel story — the two grades, then the agent's scorecard (its four traits and receipts), then yours (your traits, archetype, and verdict) — looped in the current theme (encoded in the page, no dependencies, nothing uploaded). Card export uses an inline SVG foreignObject render, which works in Chromium and Firefox; if your browser disagrees, the share card buttons are the reliable path.
- Streams every transcript line, never loads files into memory, skips anything malformed (and counts it). A multi-GB transcript directory takes seconds. opencode's SQLite database is opened strictly read-only.
- Harness-specific logic (scan paths, event normalization) lives behind a
small adapter interface:
adapters.py(Claude Code + registry),adapter_codex.py,adapter_opencode.py. Everything downstream is harness-agnostic; tool names are normalized to one vocabulary so "redundant reads" mean the same thing everywhere. - Deduplicates token usage by API message id (Claude Code writes one line per content block, repeating the same usage object, which would otherwise overcount cost by roughly 2.6x). Codex cumulative token counters are converted to per-turn deltas, and the cached share of input is split out before pricing.
- Costs come from a hardcoded price table per model in
constants.py, with cache reads and writes priced separately (opencode's own recorded cost wins when it has one). Flat-rate subscription usage is priced at API rates, which is why the report calls it an estimate. Waste estimates (re-reads, doomed retries) are labeled as estimates. - The grading rubric — traits, weights, bands, archetypes, awards, and the waste/cost estimates — is documented in docs/scoring.md.
- Schema notes from inspecting real transcripts live in docs/schema-notes.md (Claude Code), docs/schema-notes-codex.md, and docs/schema-notes-opencode.md.
- Per-agent comparison reviews (which of your reports earned the promotion)
- Trend vs your last skip-level ("you interrupted 12% less this month. growth.")
- More harnesses (Gemini CLI, Copilot CLI)
MIT. Built by the Repowise team.