This repository is for the course Applied Data Science 2, for its final capstone documentation.
Title: Recommendation of Refactoring Techniques to address Self-Admitted Technical Debt
Authors:
- Abdullah A Alsaleh (aa6304@rit.edu)
- Vinayak Sengupta (vs4016@rit.edu)
- Mohamed Wiem Mkaouer - Project Advisor (mwmvse@rit.edu)
About:
The goal of the project is to support software developers in improving the quality of their code by the recommendation of the appropriate refactoring strategies to address Self-Admitted Technical Debt (SATD). To do so, we are designing and implementing a recommendation model that takes as input of existing SATD comments, and recommends the appropriate refactoring operations that needs to be performed as part of addressing the debt in the comment. Along with that we are also going to be classifying among which SATD comments is refactoring even required.
- Python 3 (3.8+)
- numpy (1.18.5)
- pandas (1.0.5)
- Matplotlib (2.2.4)
- seaborn (0.11.0)
- pickle ( 0.7.5)
- scikit-learn (0.23.1)
- natural language tool kit (3.5)
- keras (2.4.0)
The data has been collected by the combined effort of 2 open-source tools, SATDBailiff and RefactoringMiner. The SATD-Bailiff program detects SATDs from method comments based on a machine learning model, then tracks the SATDs' span (from their occurrence to resolution). RefactoringMiner, is a Java library/API that detects refactorings applied to a Java project.The main columns of the data are the ‘resolution’, 'v1_comment', 'v2_comment' and 'refactoring_type' columns containing the end result of the refactoring, the comment before refactoring, the comment after refactoring and the refactoring method itself, respectively. We will be working with 10 unique refactoring label classes. The data set of 14156 rows with a unique instance of comments for each corresponding label. .
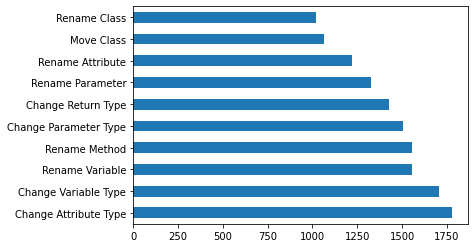
- The frequency of each class occuring:
- Random Forest Classifier
- Logistic Regression
- Support Vector Machine (SVM)
- Multi Nomial Naive Bayes (MNB)
- Convolutional neural network (CNN)
- Long short-term memory (LSTM)
| Model | F1 score | +MLSMOTE | Accuracy | +MLSMOTE | Time |
|---|---|---|---|---|---|
| RF | 0.73 | 0.68 | 0.46 | 0.36 | 1.5 min |
| LR | 0.71 | 0.67 | 0.40 | 0.30 | 9.21 min |
| SVM | 0.66 | 0.65 | 0.32 | 0.33 | 8.92 min |
| MNB | 0.67 | 0.66 | 0.35 | 0.29 | 1.2 min |
| MLP | 0.73 | 0.69 | 0.46 | 0.34 | 33 min |
| CNN | 0.62 | 0.61 | 0.73 | 0.70 | 7.33 min |
| LSTM | 0.61 | 0.60 | 0.71 | 0.71 | 125 min |
- Clone the project
- Run the test.py file to see the predicted result based on pickled train models.